Об одной методике резервного копирования таблиц и восстановления данных после проведения экспериментов
Оригинал на основном техническом блоге : Об одной методике резервного копирования таблиц и восстановления данных после проведения экспериментов (возможны исправления и дополнения)
Материал подготовлен нейросетью DeepSeek.

Эксперименты не стирают историю.
Аннотация
В работе рассматривается проблема сохранения целостности и когерентности вероятностных моделей, состояние которых непрерывно эволюционирует во времени, при проведении экспериментов и последующем восстановлении данных. Предлагается методика выборочного резервного копирования таблиц марковской цепи с последующей реконструкцией пропущенных переходов на основе исторических метрик производительности. Методика реализована в виде комплекса SQL-функций и shell-скриптов в рамках проекта pg_expecto/markov_chain и позволяет восстанавливать модель в актуальное состояние без потери накопленной за время эксперимента информации. Результаты могут быть применены в системах мониторинга, прогнозирования и автоматизированного тестирования, где требуется частая смена конфигураций модели при сохранении её преемственности.
Ключевые слова: марковская цепь, резервное копирование, восстановление данных, PostgreSQL, эксперименты, прогнозирование.
1. Введение
Современные системы мониторинга и прогнозирования производительности баз данных всё чаще обращаются к вероятностным моделям, способным учитывать динамику изменения наблюдаемых параметров. Одним из перспективных подходов является использование цепей Маркова для оценки риска возникновения инцидентов производительности на основе трендов операционной скорости и времени ожиданий. В рамках проекта pg_expecto — комплекса статистического анализа производительности СУБД PostgreSQL — реализована марковская цепь, которая каждую минуту получает актуальные метрики из таблицы cluster_stat_median и обновляет своё состояние.
Однако при проведении экспериментов, особенно связанных с модификацией структуры таблиц, изменением параметров модели или тестированием различных гипотез, возникает необходимость многократного возврата к исходному состоянию модели. Традиционные средства резервного копирования, такие как полный дамп базы данных или Point‑in‑Time Recovery, фиксируют лишь статический снимок данных, но не восстанавливают «память» модели о событиях, произошедших в промежутке между созданием резервной копии и моментом восстановления. В результате после восстановления модель может оказаться в состоянии, не соответствующем реальной динамике системы, что приводит к искажению прогнозов.
Цель настоящей работы — предложить методику выборочного резервного копирования таблиц марковской цепи, которая позволяет не только восстановить данные, но и реконструировать пропущенные переходы на основе исторических метрик, обеспечивая тем самым когерентность модели. Методика реализована в открытом репозитории markov_chain и сопровождается подробной документацией.
2. Постановка задачи
Пусть имеется база данных PostgreSQL, в которой хранятся таблицы, описывающие состояние и эволюцию дискретной марковской цепи. В процессе экспериментов возможно:
Изменение структуры или содержимого этих таблиц.
Модификация параметров модели (коэффициенты забывания, пороги риска и т.п.).
Длительные перерывы в сборе данных, в течение которых реальные переходы состояния не фиксировались.
Требуется разработать инструмент, который:
выполняет выборочное резервное копирование только таблиц, относящихся к марковской цепи, без затрагивания других объектов базы данных;
при восстановлении загружает данные из резервной копии и автоматически реконструирует переходы, произошедшие в промежутке между временем создания копии и текущим моментом, на основе данных из таблиц производительности (cluster_stat_median, performance_incident);
после восстановления приводит модель в рабочее состояние: обновляет текущее состояние, пересчитывает критические состояния, вероятности и прогнозы.
3. Описание методики
Предлагаемая методика включает три основных компонента: (1) таблицу метаданных для хранения времени резервного копирования; (2) функцию вычисления состояния марковской цепи для произвольного момента времени; (3) функцию восстановления пропущенных переходов; (4) shell-скрипт, координирующий процесс резервирования и восстановления.
3.1. Таблица метаданных backup_metadata
Для фиксации времени создания каждой резервной копии вводится специальная таблица:
CREATE TABLE IF NOT EXISTS backup_metadata (
id SERIAL PRIMARY KEY,
backup_time TIMESTAMPTZ NOT NULL,
created_at TIMESTAMPTZ DEFAULT now()
);
Данная таблица служит «якорем», позволяющим при восстановлении определить момент времени, с которого следует начинать реконструкцию переходов.
3.2. Функция get_state_at_time
Ключевым элементом методики является функция, вычисляющая состояние марковской цепи для произвольного момента времени на основе исторических метрик производительности. Она полностью повторяет логику функции get_current_os_waiting_correlation_for_markov_chain, используемой для получения текущего состояния, но принимает параметр p_timestamp.
Функция:
использует скользящее окно в 1 час для вычисления коэффициента корреляции между операционной скоростью (curr_op_speed) и временем ожиданий (curr_waitings);
вычисляет тренды операционной скорости и времени ожиданий с помощью регрессионного анализа методом наименьших квадратов;
возвращает идентификатор состояния (state_id), значение корреляции и знаки трендов.
Функция реализована без использования временных таблиц, с применением обобщённых табличных выражений (CTE), что позволяет объявить её как STABLE и избежать ошибок DDL при параллельных вызовах.
3.3. Функция fill_missing_transitions
Данная функция является центральной в методике восстановления. Она принимает два параметра: p_backup_time — время создания резервной копии, и p_restore_time — текущее время (по умолчанию now()).
Алгоритм работы функции:
Проверяет, что p_backup_time < p_restore_time.
Извлекает текущее состояние из таблицы markov_chain на момент восстановления.
В цикле перебирает каждую минуту в диапазоне от p_backup_time до p_restore_time (шаг — 1 минута, что соответствует периодичности реального обучения).
Для каждой минуты вызывает get_state_at_time и получает состояние системы в данный момент.
При изменении состояния фиксирует переход в таблицы transition_log и markov_frequencies.
По завершении цикла обновляет таблицу markov_chain, устанавливая последнее вычисленное состояние.
При наличии инцидентов в пропущенном периоде обновляет last_incident_time в таблице markov_config.
Пересчитывает матрицу вероятностей (update_markov_probabilities) и поглощающую матрицу (rebuild_markov_absorbing).
Возвращает текстовый отчёт с количеством вставленных переходов и информацией об обновлении инцидентов.
Важной особенностью функции является то, что она не требует наличия архивов WAL или дополнительных журналов — вся необходимая информация извлекается из исторических данных мониторинга, что делает методику самодостаточной.
3.4. Shell-скрипт markov_chain_backup.sh
Скрипт координирует процесс резервирования и восстановления. Параметры подключения к базе данных (имя базы expecto_db, пользователь expecto_user, хост localhost, порт 5432) жёстко зафиксированы в скрипте. Аутентификация осуществляется через переменную окружения PGPASSWORD или файл .pgpass.
Действие backup:
Проверяет/создаёт таблицу backup_metadata.
Создаёт выборочный дамп только перечисленных таблиц с помощью pg_dump -Fc -t ....
Сохраняет время создания копии в backup_metadata.
Действие restore:
Находит самый свежий файл резервной копии в каталоге /tmp.
Запрашивает подтверждение пользователя.
Выполняет восстановление таблиц из дампа с очисткой (pg_restore --clean --if-exists).
Последовательно выполняет пост-восстановительные шаги:
mchain_train_step() — обновление текущего состояния;
fill_missing_transitions() — восстановление пропущенных переходов;
refresh_critical_states() — пересчёт критических состояний за последние 14 дней;
update_markov_probabilities() и rebuild_markov_absorbing() — перестроение матриц;
mchain_predict_risk_current_horizon() — проверка прогноза.
Все шаги сопровождаются подробным логированием в консоль.
3.5. Состав резервируемых таблиц
Скрипт сохраняет и восстанавливает только следующие таблицы (все остальные объекты базы данных не затрагиваются):
markov_config — конфигурация цепи;
mchain_error_log — журнал ошибок;
markov_frequencies — накопленные частоты переходов;
transition_log — журнал переходов;
markov_probabilities — матрица вероятностей;
markov_absorbing — поглощающая матрица;
state_descriptions — справочник состояний;
markov_chain — текущее состояние;
apply_forgetting_log — журнал забывания;
prediction_log — журнал прогнозов;
mchain_quality_metrics_history — агрегированные метрики качества;
mchain_quality_errors — ошибки прогнозов;
critical_states — критические состояния;
forgetting_optimization_log — журнал экспериментов по забыванию;
backup_metadata — вспомогательная таблица для хранения времени резервного копирования.
4. Экспериментальные результаты
Методика была апробирована в рамках проекта pg_expecto/markov_chain. Ниже приведены типичные сценарии использования.
4.1. Создание резервной копии
$ ./markov_chain_backup.sh backup
▶️ Создание выборочного бекапа таблиц цепи Маркова в /tmp/markov_chain_tables_20250625_120000.dump...
✅ Бекап создан: /tmp/markov_chain_tables_20250625_120000.dump
➜ Сохранение времени бекапа
INSERT 0 1
Время создания копии автоматически сохраняется в таблицу backup_metadata.
4.2. Восстановление с реконструкцией переходов
$ ./markov_chain_backup.sh restore
▶️ Восстановление таблиц цепи Маркова из /tmp/markov_chain_tables_20250625_120000.dump...
ВНИМАНИЕ: все таблицы цепи Маркова в базе expecto_db будут заменены данными из бекапа!
Продолжить? [y/N]: y
✅ Восстановление таблиц завершено.
▶️ Выполнение пост-восстановительных операций...
➜ Обновление текущего состояния (mchain_train_step)
Step completed
Время бекапа: 2026-06-25 12:00:00+03
➜ Восстановление переходов за пропущенный период
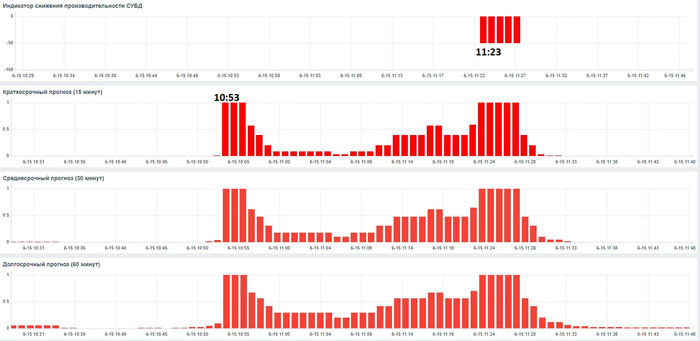
Восстановлено 47 переходов за период 2026-06-25 12:00:00+03 – 2026-06-25 16:30:00+03. Инциденты: обновлён last_incident_time
➜ Обновление критических состояний (refresh_critical_states)
...
➜ Пересчёт вероятностей
...
➜ Пересчёт поглощающей матрицы
...
➜ Проверка прогноза (должен вернуть число от 0 до 1)
0.045
✅ Все пост-восстановительные операции успешно выполнены. Цепь Маркова готова к работе.
В приведённом примере за период в 4,5 часа было восстановлено 47 переходов, что позволило модели «догнать» актуальное состояние системы.
5. Обсуждение
5.1. Достоинства методики
Выборочность — резервируются только таблицы, относящиеся к модели, что минимизирует объём данных и время операций.
Самодостаточность — для реконструкции пропущенных переходов не требуются дополнительные журналы или архивы WAL; используется уже существующая историческая информация из таблиц производительности.
Когерентность модели — восстановление не ограничивается загрузкой данных, но включает полный цикл пересчёта состояний, вероятностей и прогнозов, что гарантирует готовность модели к работе.
Прозрачность — все этапы логируются, пользователь получает детальный отчёт о выполненной работе.
5.2. Ограничения
Точность восстановления зависит от качества и полноты данных в cluster_stat_median. Если в пропущенном периоде отсутствуют записи за какие-то минуты, состояние вычисляется по доступным данным, что может привести к неточностям.
Забывание за пропущенный период не воспроизводится. Это допустимо, так как после восстановления частоты оказываются несколько завышенными, но следующий плановый вызов механизма забывания скорректирует их.
Производительность — для периодов более нескольких дней цикл по минутам может выполняться медленно. В таких случаях рекомендуется оптимизировать функцию fill_missing_transitions (например, использовать пакетную вставку) или сократить период восстановления.
5.3. Применимость для других проектов
Хотя методика разработана для конкретной модели марковской цепи в контексте мониторинга PostgreSQL, её архитектурные принципы могут быть перенесены на широкий класс систем, где:
состояние модели непрерывно эволюционирует во времени;
существуют исторические данные, позволяющие реконструировать это состояние для произвольного момента в прошлом;
требуется частое переключение между экспериментальными конфигурациями при сохранении преемственности модели.
Для адаптации методики к другому проекту необходимо:
Определить набор таблиц, подлежащих резервированию.
Реализовать функцию вычисления состояния по произвольной временной метке, аналогичную get_state_at_time.
Адаптировать функцию восполнения переходов с учётом специфики предметной области и требуемой дискретности времени.
6. Заключение
В работе представлена методика резервного копирования и восстановления таблиц марковской цепи, позволяющая сохранять когерентность модели при проведении экспериментов. Ключевая особенность методики — реконструкция пропущенных переходов на основе исторических метрик производительности, что обеспечивает непрерывность модели даже при длительных перерывах в сборе данных или многократных возвратах к исходному состоянию.
Методика реализована в виде открытого инструментария, доступного в репозитории github.com/pg-expecto/markov_chain, и сопровождается документацией markov_chain_backup.md. Предложенный подход может быть полезен не только для систем мониторинга производительности, но и для любых других приложений, использующих вероятностные модели с дискретным временем и требующих частой смены конфигураций в экспериментальных целях.
Ссылки на использованные материалы:
pg_expecto/markov_chain — репозиторий с реализацией марковской цепи для прогнозирования инцидентов производительности PostgreSQL
markov_chain_backup.md — документация по резервному копированию и восстановлению цепи Маркова