

Вопрос к Пикабу, вы тоже отключите вход с почты Google?
Российские сервисы стали предупреждать своих пользователей о невозможности входа через Apple ID и Google с 6 июля, обратило внимание РИА Новости.
Держись Пикабу! Я верю в тебя!
Российские сервисы стали предупреждать своих пользователей о невозможности входа через Apple ID и Google с 6 июля, обратило внимание РИА Новости.
Держись Пикабу! Я верю в тебя!

В SEO появилась новая любимая игрушка: LLM SEO, GEO, AEO и прочие красивые аббревиатуры, от которых обычный владелец сайта должен почувствовать, что без срочного внедрения чего-нибудь модного он уже опоздал лет на пять. Раньше все дружно оптимизировались под Google и Яндекс, потом под голосовой поиск, потом под нейросети, а теперь вот под то, чтобы ChatGPT, Gemini или Perplexity случайно не прошли мимо вашего сайта.
Проблема в том, что вокруг этой темы сейчас очень много спекуляций. Особенно в ру-сегменте. Нормальных исследований почти нет: в основном пересказы западных статей, личные ощущения, «мне кажется» и вечное «добавьте FAQ, Schema.org и llms.txt, и будет вам счастье». На практике всё сложнее. Западные исследования уже начали появляться, но даже они пока больше похожи на карту гипотез, чем на официальную инструкцию от тайного совета поисковых роботов.
Я посмотрел, какие факторы чаще всего всплывают в материалах про AI Overviews, ChatGPT, Gemini, Perplexity и другие ИИ-ответы, и собрал их в один список. Сразу дисклеймер: это не «официальные факторы ранжирования». Это набор наблюдений, корреляций и здравого смысла. Причем в теме, которая меняется настолько быстро, что часть выводов через полгода может устареть или поменяться местами по значимости.
Если совсем коротко, то больше всего сейчас похожи на важные факторы: доступность страницы, обычные SEO-позиции, тематическое покрытие, прямой ответ на вопрос пользователя, структура текста, конкретика, источники, доверие к бренду, внешние упоминания и техническая понятность страницы. А вот всякие модные штуки вроде llms.txt пока выглядят скорее как эксперимент, а не как волшебная кнопка.
Звучит банально, но это база. Если страница закрыта от роботов, отдает ошибку, требует авторизацию, грузит весь важный текст через сложный JavaScript или запрещает сниппеты, то ИИ вряд ли внезапно скажет: «О, вот это великий источник, срочно цитируем». ИИ не телепат. Если он не может нормально добраться до страницы, то и использовать её в ответе ему сложно.
Отдельная забавная история — хостинги и CDN, которые предлагают ограничивать ботов ИИ-систем, когда те создают нагрузку. С одной стороны, сервер жалко. С другой — раньше некоторые так же советовали ограничивать поисковых роботов. Потом SEO-специалисты сидели и гадали, почему сайт в индексе выглядит как Шредингеров кот: вроде есть, а вроде нет.
Есть распространенное заблуждение: «Ну всё, теперь поисковики умерли, надо оптимизироваться только под ChatGPT». Нет. По исследованиям и наблюдениям видно, что страницы, которые уже хорошо ранжируются в обычном поиске, чаще попадают и в AI-ответы.
То есть классическое SEO никуда не делось. Техническая оптимизация, нормальная структура сайта, интент, качество страниц, внутренняя перелинковка, контентные кластеры — всё это по-прежнему важно. Просто сверху появился новый слой: насколько удобно ИИ взять с вашей страницы понятный фрагмент и вставить его в ответ.
Поэтому «продвижение в ИИ» не заменяет нормальное SEO. Оно скорее добивает тех, кто надеялся, что можно написать унылый текст на 20 000 знаков, пару раз вставить ключ и жить спокойно.
ИИ часто не ищет ответ одним запросом. Он может взять вопрос пользователя, разбить его на несколько уточняющих подзапросов, собрать информацию из разных источников и потом склеить итоговый ответ. Например, человек спрашивает: «Как выбрать CRM для малого бизнеса?» А ИИ параллельно может искать про цены, интеграции, внедрение, сравнение CRM, отзывы, типичные ошибки, миграцию данных и отраслевые решения.
Поэтому лучше работает не одна гигантская статья в стиле «CRM купить недорого цена», а нормальный тематический кластер. Когда сайт закрывает тему глубоко и с разных сторон, у него больше шансов попасть хотя бы в один из промежуточных поисков, из которых потом собирается AI-ответ.
Проще говоря, если у вас на сайте есть одна страница «ремонт ноутбуков», это одно. А если есть отдельные нормальные материалы про диагностику, замену матрицы, ремонт после залития, чистку, цены, сроки, гарантии и типичные поломки — это уже больше похоже на источник, которому есть что сказать.
Старый добрый SEO-текст, где ответ спрятан где-то между «на сегодняшний день в современном мире» и «наша компания предлагает индивидуальный подход», может работать всё хуже. ИИ удобнее цитировать кусок, где есть конкретный ответ на конкретный вопрос.
Например, фраза «LLMs.txt может помочь ИИ-системам понять важные страницы сайта, но пока нет доказательств, что сам файл сильно повышает цитируемость» — это нормальный самостоятельный фрагмент. Его можно взять и использовать. А если ответ спрятан в текстовом болоте, модель может просто пройти мимо.
Хороший принцип для страниц и статей: сначала короткий ответ, потом подробности. Не три экрана вступления, история вопроса, немного философии и только потом суть, а наоборот. Сначала ответ, потом аргументы, примеры, нюансы и ограничения. Это полезно не только для ИИ, но и для людей. Потому что люди тоже не любят читать пять абзацев ради ответа «да, но с нюансами».
Заголовки, списки, FAQ, определения, сравнения, выводы, блоки «плюсы и минусы», «сроки», «цены», «частые ошибки» — всё это помогает ИИ понять, что именно написано на странице. Не потому что список — магический артефакт из подземелья SEO, а потому что структурированный текст проще разобрать.
Если у вас на странице всё слито в одну простыню, модель должна сама догадываться, где описание услуги, где условия, где ограничения, где цена, где вывод, а где просто маркетинговая вода. Чем меньше ИИ нужно копаться в тексте как в ящике с проводами, тем лучше.
FAQ тоже может быть полезен, но не как волшебная SEO-кнопка, а как способ дать прямые ответы на частые вопросы. Главное, чтобы это был реальный видимый текст на странице, а не набор ключей, спрятанный в коде «для роботов».
Фразы вроде «мы предлагаем качественные услуги», «у нас индивидуальный подход» и «наша команда профессионалов» в AI-ответах выглядят примерно как белый шум. Они ничего не объясняют и не дают модели полезного факта.
ИИ гораздо полезнее конкретика: сроки, цены, условия, характеристики, ограничения, даты, сравнения, этапы, гарантии, реальные примеры. «Доставка осуществляется быстро» — ни о чем. А «доставка по Москве занимает 1–2 дня, по регионам — от 3 до 7 дней» — уже нормальный фрагмент, который можно использовать в ответе.
Для коммерческих сайтов это особенно важно. Чем конкретнее описаны услуги, цены, условия, гарантии и ограничения, тем выше шанс, что страница окажется полезной не только человеку, но и ИИ.
Если статья ссылается на исследования, документы, статистику или хотя бы объясняет, откуда взяты выводы, она выглядит надежнее. Особенно это важно в медицине, финансах, праве, безопасности и других темах, где ошибка может стоить дорого.
Там уже мало написать «наши эксперты считают». Нужно показывать квалификацию, источники, документы, ограничения и нормальную доказательную базу. ИИ тоже не всегда хочет брать ответ из текста уровня «мамой клянусь, всё работает».
Для информационных статей это значит: меньше бездоказательных утверждений, больше проверяемых фактов. Для коммерческих страниц — больше прозрачности: кто оказывает услугу, на каких условиях, сколько стоит, какие есть ограничения, какие документы, какие гарантии.
Плохой фрагмент: «Это помогает улучшить результат». Что «это»? Какой результат? Кому помогает? Почему?
Хороший фрагмент: «Короткий ответ в начале блока повышает шанс цитирования в AI-ответах, потому что модель может извлечь готовый смысловой фрагмент без дополнительного контекста». Такой кусок можно почти сразу вставить в ответ. Он самодостаточный.
Это вообще хороший тест для любого текста: если вырвать абзац из страницы, он всё еще понятен или превращается в загадку из ЕГЭ? Если превращается в загадку, для ИИ это тоже может быть проблемой.
Вот это интересный момент. В исследованиях всё чаще всплывает, что для AI-видимости важны не только ссылки, но и просто упоминания бренда в интернете. То есть если о компании пишут в обзорах, рейтингах, подборках, статьях, обсуждениях, соцсетях, медиа и профессиональных сообществах — это может помогать ИИ понимать, что бренд вообще существует и с чем он связан.
Получается, что SEO постепенно становится не только про «купить ссылку с донора», но и про нормальное присутствие бренда в интернете. PR, экспертные комментарии, гостевые статьи, каталоги, отзывы, отраслевые подборки — всё это может влиять на то, как ИИ воспринимает компанию.
У себя в Telegram я как раз собираю такие наблюдения по SEO, AI-поиску и техническим экспериментам: https://t.me/seonemagia. В ближайшее время там будут появляться не только разборы, но и небольшие инструменты для SEO-специалистов: генераторы, чекеры и разные штуки для технической оптимизации.
Для ИИ и поисковых систем важно понимать, кто вы такие. Компания? Автор? Клиника? Магазин? SaaS-сервис? Эксперт? Медиа? Если бренд встречается только на своем сайте и нигде больше, это слабый сигнал.
А если есть карточки компании, отзывы, страницы авторов, профили, публикации, упоминания на других площадках, документы, кейсы и нормальная структура — это уже лучше. Для клиники это могут быть страницы врачей, лицензии, образование, стаж. Для интернет-магазина — карточки товаров, отзывы, доставка, возврат, гарантии. Для сервиса — документация, кейсы, интеграции, сравнения и понятные описания продукта.
ИИ нужно не просто прочитать страницу. Ему нужно понять, можно ли этому источнику доверять и что это вообще за источник.
Да, свежие материалы часто имеют преимущество, особенно в темах, где всё быстро устаревает: технологии, законы, цены, маркетинг, медицина, инструкции по сервисам. Но свежесть — это не просто поменять дату публикации с 2024 на 2026 и гордо сказать «обновлено».
Нормальное обновление — это когда вы реально добавили новые данные, убрали устаревшее, перепроверили цены, заменили старые скриншоты, обновили инструкции и дописали новые выводы. Свежесть без полезного обновления — слабый сигнал. Актуальность вместе с нормальным содержанием — уже намного лучше.
Если важная информация спрятана в табах, аккордеонах, подгружается через JavaScript или появляется только после клика, она может хуже использоваться AI-системами. Да, Google давно умеет многое рендерить. Но это не значит, что любая ИИ-система одинаково хорошо достанет всё, что вы спрятали на странице.
Цены, условия, FAQ, характеристики, описания услуг, адреса, данные специалистов — всё важное лучше делать видимым и доступным. Не надо прятать самое ценное в интерфейсных матрешках, а потом удивляться, что его никто не использует.
Микроразметка помогает поисковикам и ИИ лучше понять, что перед ними: организация, товар, статья, врач, FAQ, хлебные крошки, отзыв, услуга и так далее. Но сама по себе Schema.org не гарантирует попадание в AI-ответы.
Особенно если в JSON-LD написано одно, а на странице для пользователя этого нет. Правильный порядок такой: сначала нормальный видимый текст, потом аккуратная разметка, которая его описывает. А не наоборот.
Backlinks и авторитет домена всё еще нужны для обычного SEO. Сильный домен и хорошие ссылки помогают ранжироваться. Но в AI-цитируемости ссылки выглядят не единственным и не всегда главным фактором.
Тематическое покрытие, структура, конкретика, брендовые упоминания и доверие к сущности могут играть не меньшую роль. Проще говоря, просто «накупить ссылок и ждать, что вас полюбит ChatGPT» — так себе план.
LLMs.txt сейчас обсуждают как потенциальный аналог robots.txt для ИИ-систем. Идея понятная: дать моделям файл с важными страницами сайта, документацией, правилами использования контента и ключевыми ссылками.
Звучит интересно. Возможно, со временем это станет стандартом. Сейчас LLMs.txt уже поддерживают или тестируют многие крупные игроки индустрии, поэтому полностью игнорировать тему я бы не стал. Но если расставлять приоритеты, то llms.txt явно не на первом месте. Сначала техническая доступность, нормальный контент, структура, SEO, бренд и внешние упоминания. А уже потом эксперименты с новыми файлами.
Если хочется быстро попробовать, я сделал простой генератор llms.txt: https://siteupgrade.online/tools/llms-txt-generator/. Это не заменяет SEO и не превращает сайт в любимчика ChatGPT, но как быстрый технический эксперимент — вполне нормальный шаг.
Если коротко, AI-цитируемость — это не отдельная магия, а усиленная версия нормального SEO. Сайт должен быть доступен, хорошо индексироваться, закрывать тему глубоко, давать прямые ответы, содержать факты, быть понятно структурированным и существовать как бренд не только у себя на домене.
Я бы проверял простые вещи: открыты ли важные страницы для индексации, видит ли поисковик важный текст, есть ли на страницах прямые ответы на реальные вопросы пользователей, не спрятана ли суть после трех экранов воды, есть ли конкретика по ценам, срокам, условиям и ограничениям. Также стоит смотреть, есть ли нормальная структура, источники и доказательства там, где они нужны, понятно ли, кто автор или компания, и есть ли упоминания бренда за пределами собственного сайта.
ИИ не отменил SEO. Он просто сделал более заметной старую проблему: плохой, водянистый, неструктурированный текст становится всё менее полезным. Раньше такой текст хотя бы мог как-то висеть в поиске и собирать хвосты. Теперь, когда ИИ пытается собрать готовый ответ, ему удобнее брать не «SEO-полотно на 20 000 знаков», а нормальный, структурированный, конкретный и понятный источник.
Поэтому задача уже не просто «написать текст под ключи». Задача — стать источником, которому удобно доверять, удобно парсить и удобно цитировать.
А вокруг темы, конечно, еще будет много шума. Кто-то будет продавать «волшебную оптимизацию под ChatGPT», кто-то — ставить llms.txt как амулет от невидимости, кто-то — переименовывать обычное SEO в GEO и добавлять x3 к стоимости. Но если убрать маркетинговый туман, суть пока такая: нормальная техническая база, хороший контент, структура, факты, бренд и внешняя репутация.
Всё скучно, сложно и без магии. Как обычно в SEO.
Мой цифровой кошелек забился в конвульсиях и затребовал инъекцию свежего кода. Великая Гугловская Матерь нас покинула, отрезала пуповину, и теперь путь один — в подвалы. К отечественному протезу. Снова эта чехарда. Снова спуск в этот цифровой некрополь.
Для начала нужно повернуть вентиль. Дать приложению интернет.
Я смахиваю шторку, пускаю пакеты данных по венам системы. Телефон тут же вздрагивает, начинает подлагивать, как паралитик на дискотеке — я прям чувствую, как эта дрянь проснулась и поползла шарить своими невидимыми жвалами по кэшу, пытаясь что-то там делать в фоне. Но до банка еще далеко. Протез оживает и тут же, хлопая цифровыми глазами, заявляет, что прежде чем спасти мой кошелек, я должен обновить ЕГО САМОГО. Рекурсия безумия. Уроборос, жрущий собственный пиксельный хвост.
Ладно. Я уже все равно полез в это, без этого никуда. Жму кнопку скачивания.
И вот тут моя операционная система покрывается холодным системным потом. Она бьет по тормозам. Экран темнеет, и всплывает окно, мигающее тревожным красным, как глаз терминатора с похмелья: «ТЫ УВЕРЕН? ОНО ПЫТАЕТСЯ УСТАНОВИТЬ САМО СЕБЯ. У ТЕБЯ ЕСТЬ ДЕСЯТЬ СЕКУНД, ЧТОБЫ ОДУМАТЬСЯ, МЕШОК С КОСТЯМИ! ТЫ ТОЧНО ГОТОВ НА ЭТО ПОЙТИ?»
Без этого никуда. Запомни эту фразу, она тут вместо молитвы. Я жму «Да».
Процесс пошел, и тут же, словно чертик из табакерки, выпрыгивает Соглашение. Это не текст. Это изрыгнутый машинным переводчиком юридический гной, написанный на диалекте древних рептилоидов-бюрократов. А в самом низу — она. Галочка. Маленький, подлый клещ, по умолчанию впившийся в строчку: «Я умоляю вас присылать мне рекламный кал прямо в мозг до скончания веков». Снимаю клеща. Хрен вам. Конечно, без этого никуда, но я еще сопротивляюсь.
Двери открываются. Я внутри. Добро пожаловать на базар карго-культа.
Что на главной витрине? Горы всратого, кислотного цифрового мусора. «Собери три страза в ряд, чтобы спасти орка от налоговой». Это их приветственный комитет! Они смотрят на меня через фронтальную камеру и думают: «Ага, новый пользователь! Наверняка лоботомированный дегенерат! Давай швырнем ему в лицо самую дебильную мобильную дрочильню, у него же слюна капает!»
Пока я продираюсь сквозь этот парад уродов, протез тянет ко мне свои липкие щупальца. Всплывают системные запросы: «Хозяин, дай мне автозапуск. Я хочу жить вечно! Хозяин, отключи ограничения по батарее! Я хочу выпить твой аккумулятор до дна! Я хочу ковыряться в твоей фоновой активности!»
Ага, щас. Похер. Бью по щупальцам отказом. Вбиваю в поиск банк. Нахожу. Жму «Обновить».
И ТУТ ВСПЫШКА!
Синее окно перекрывает весь экран. Авторизация. Впусти нас через социальную сеть! БЛЯДЬ! Пульс двести. Глаза наливаются кровью. Я уже готов швырнуть этот кусок пластика и кремния в стену, но стоп. Выдыхаю. Маленькая, серая, почти невидимая кнопка. Ложная тревога. Это можно скипнуть. Полоса загрузки банка поползла вправо. Но осадок от этого неуместного выкрутаса уже въелся в подкорку.
Пока она ползет, меня накрывает. Я смотрю на этот интерфейс и не понимаю, откуда в них столько жадной, слепой, неуместной тупости.
Вы делаете костыль. Вы делаете заменитель. Люди относятся к вам с параноидальным недоверием, ищут подвох под каждым пикселем. Никто не приходит сюда жить, никто не хочет гулять по вашим виртуальным бульварам! Люди заходят сюда справить нужду — быстро, брезгливо, зажав нос. И даже за эти жалкие сорок секунд вы умудряетесь измазать пользователя неприятным впечатлением!
Вместо нормального инструмента в условиях санкций они сколотили Лас-Вегас из говна и палок. Они получили монополию. Мы сами к ним пришли, потому что нас прижали к стене. И вместо того, чтобы сказать: «Братан, времена тяжелые, вот твое приложение, иди с миром», — они используют это как шанс всучить своих выблядков, запереть тебя в комнате, врубить стробоскоп и орать в уши.
Они пытаются скопировать зарубежных гигантов. Но те — это отлаженные хищники глобального рынка. Они жрут тебя на своей территории, в своей операционке. Их интерфейс вылизан, их реклама вшита органично, как яд в красивое яблоко. А эти? Эти вламываются в чужую операционную систему в грязных сапогах, спотыкаются о системные файлы, блюют на рабочий стол и пытаются заставить тебя за это заплатить.
Карго-культ в абсолюте. «Смотрите, у белых людей за океаном все мельтешило, были подписки, уведомления и аттракционы! Мы ни черта не поняли, как это работает изнутри, но давайте наспех навалим того же самого, создадим видимость движа и будем стричь бабло прямо на конвейере!» Просто сделайте для людей! Но нет, надо занять поляну и начать тупо ее засирать.
100%. Установка завершена.
Я бью по рубильнику. Интернет отрублен. Кислород перекрыт.
Протез судорожно глотает воздух без сети и падает в глухой цифровой анабиоз. Я открываю галерею. Проверяю секретные папки. Моя коллекция запрещенных, отборных, чернейших мемов. Мое золото. Все на месте. Надеюсь, их щупальца сюда не пролезли.
Я вытираю пот со лба. Банк обновлен. Я выжил. Завтра будет новый день, новая борьба с системой, но сегодня... сегодня моя операционка может спать спокойно. До следующего апдейта.
Решил посмотреть актёров фильма "Марсианин", так это херня начала меня гонять по капчам. Это уже третья, капча, после двух правильно решённых. У меня ничего не поменялось, ни айпишник, не устройство, а он за сессию иногда по дохулиярд раз спрашивает эти капчи решить.
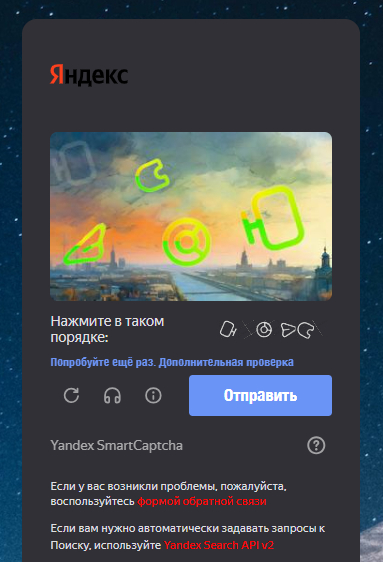
Закрыл это недоразумение, открыл нормальный поисковик

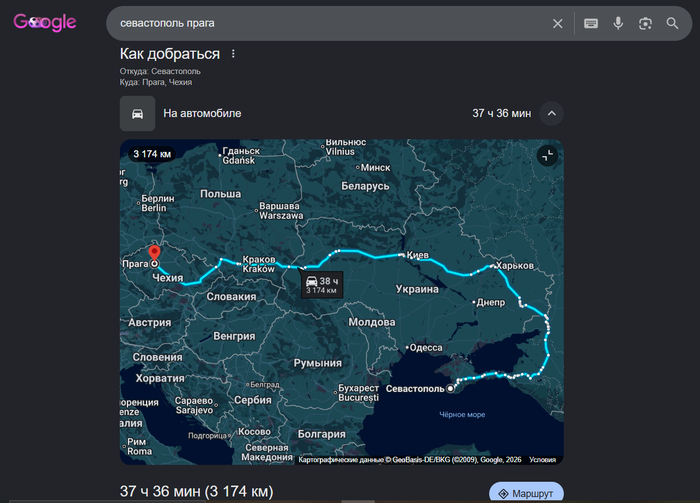
Я просто хотел проверить жив ли ещё один пивняк
Ну в общем находим бенз в Крыму, перекупы всего по 250 отдают - копейки, ещё стопку номеров, две запаски, корешей кто хочет пива, заграны всем, ждём когда пролетит очередная волна БПЛА и мост откроют, потом самая тяжёлая часть маршрута - краснодарские пробки, Ростов-папа - давно не виделись, город-герой Донецк, помогаем с Константиновкой, на сдачу штурмуем Краматорск и Славянск, просачиваемся за линию фронта, посещаем места юности в Харькове, потом Полтава, Киев само собой - мать всё таки, сбегаем от ТЦКшников каждый раз, во Львове от бандеровцев, достаём из широких штанин свои заграны, гипнотизируем валинорских погранцов, смотрим учебные языковые видео со змеями, Краков неплох, спокойный Ополе, переезжаем через невысокие горы, Брно, прочие места с редуцированными гласными, и вот наконец мы на месте, идём пить пиво и кушать вепрево колено, на мост ихний не идём потому что вдоль него на всю длину нищие лбом в пол стоят. Как-то так я себе это представляю.

Что за шляпа новая? Через гугл в майл не пускает
Apple уже вынесла Макс и ВК из App Store. А толпа андроидоводов радостно ржала.
С сентября Google окончательно закроет и эту лавочку! Приложения будут ставиться только от верифицированных разработчиков. Никаких сторонних источников, никаких сторонних APK. Только Play Market и одобренный корпорацией софт. Теперь и эти умники окажутся в той же жопе, что и айфонщики.
Интересно как отреагируют те кто вчера поддерживал блокировки "плохих" приложений, на такой пассаж от "корпорации добра"? Свобода - это когда разрешено только то, что одобрили.
Добро пожаловать в светлое будущее, где на обеих платформах можно ставить только то что вам разрешили.
UPD: Разъяснения в коментах
Всем привет! Сегодня принёс штуку, которая чинит пару мелочей, но мелочей, об которые спотыкаешься каждый день.
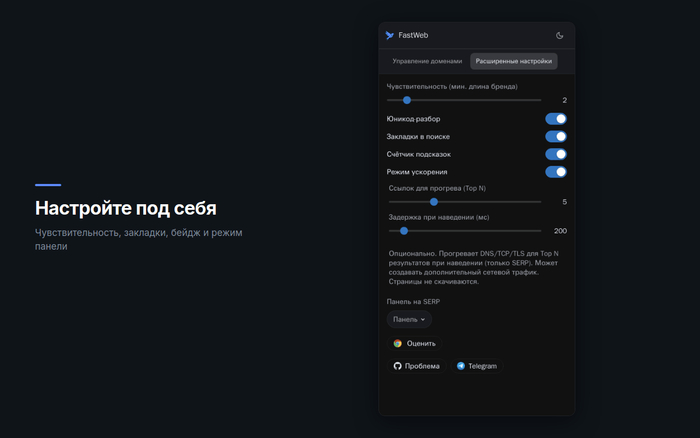
Боль первая: закладки. У меня их за годы накопились сотни, и толку ноль. То, что нужно, лежит где-то в недрах папок, и проще загуглить заново, чем вспомнить, куда сам же сохранил. Кладбище, а не закладки.
Боль вторая: скорость. Кликаешь по результату поиска и ждёшь, пока браузер с нуля познакомится с сайтом, установит соединение, договорится о шифровании. Каждый раз заново, и каждый раз эти полсекунды-секунда на ровном месте.
Сделал браузерное расширение FastWeb, оно работает прямо на странице выдачи Google, Bing, DuckDuckGo и Яндекса. Если среди результатов есть сайт, на который у тебя была закладка, расширение покажет её рядом, не надо лезть в дебри папок. А пока ты выбираешь, на что нажать, оно потихоньку прогревает соединение с верхними результатами, и страница открывается заметно резвее. Никакого контента заранее не качает, только готовит коннект.
Ещё умеет показывать альтернативные адреса сайтов. Ресурсы иногда меняют домены и переезжают, и привычная ссылка из выдачи внезапно ведёт в тупик. FastWeb держит карту таких переездов и подсказывает рабочий адрес, чтобы ты не утыкался в пустую страницу. Без подробностей, кто понял, тот понял :)
Всё локально, ничего не уходит на сторону, без аналитики и телеметрии. Доступно в Chrome, Firefox и Edge, ссылки на сайте проекта.
Пора принести новые фишки. Думаю в сторону того, как у DuckDuckGo сделаны bangs: пишешь в строке поиска короткое сокращение с восклицательным знаком, например !w для Википедии или !ozon, и сразу проваливаешься в поиск по нужному сайту, минуя выдачу. Хочу прикрутить похожее, с уже зашитыми самыми ходовыми сайтами и магазинами.
Так что спрошу шире, без привязки к этой идее. Чего вам не хватает прямо на странице выдачи? Не обязательно сокращений, это лишь один пример, к которому я остыл. Накидайте свои хотелки про поиск, толковое возьму в работу.





