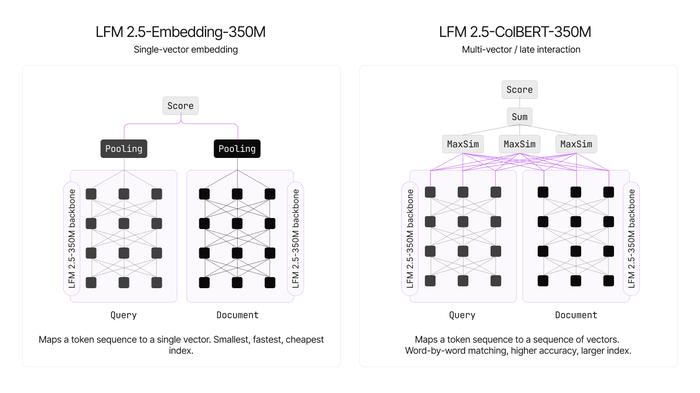
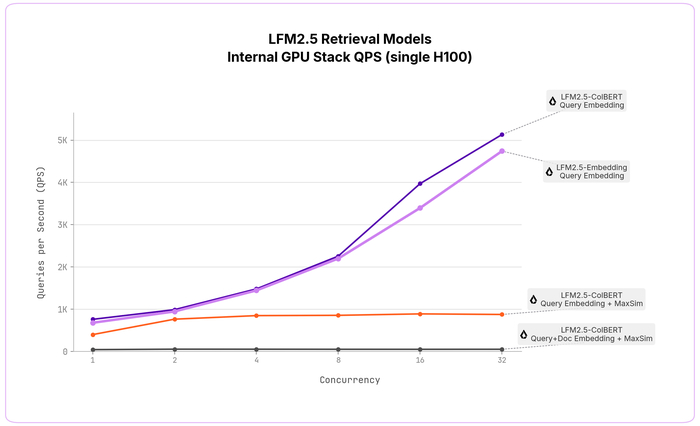
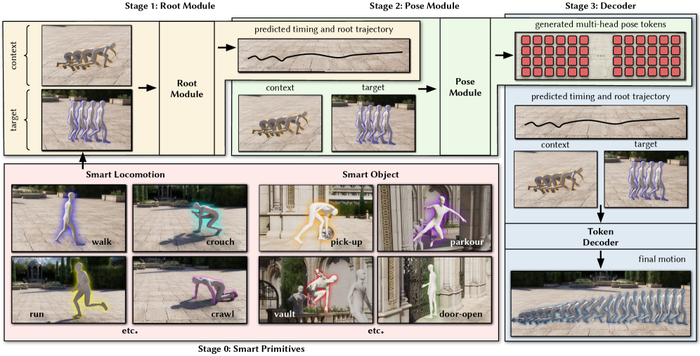
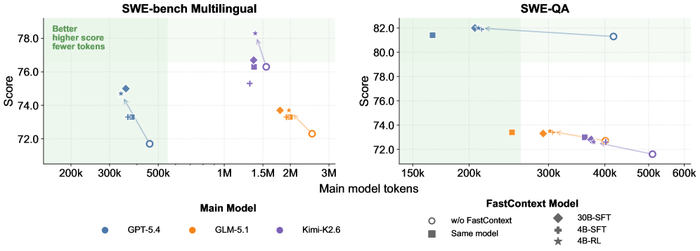
Вышла новая модель Ornith-1.0
Предоставлено новое семейство самообучающихся моделей Ornith-1.0 (https://huggingface.co/collections/deepreinforce-ai/ornith-1...) для агентного кодирования (9B-397B, на базе Gemma 4 и Qwen 3.5).
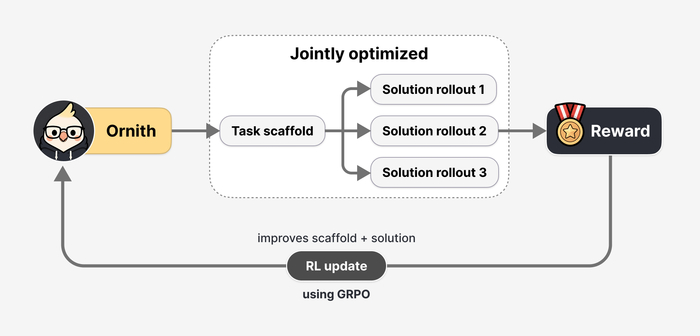
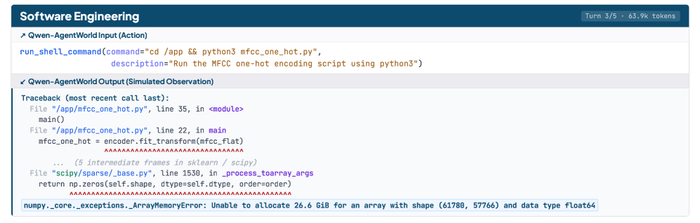
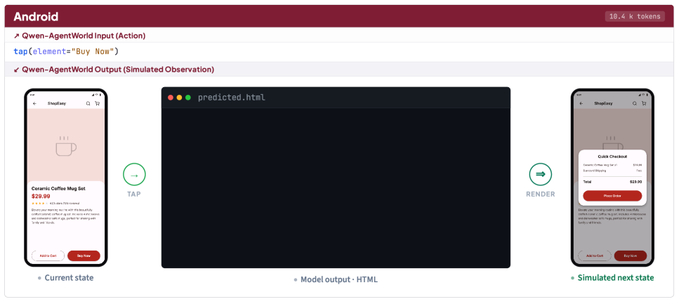
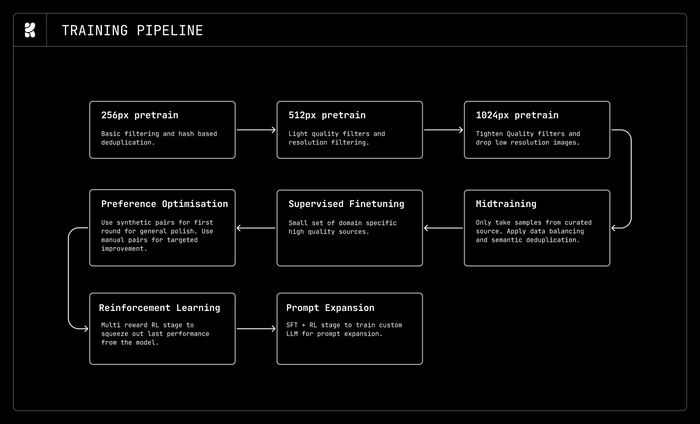
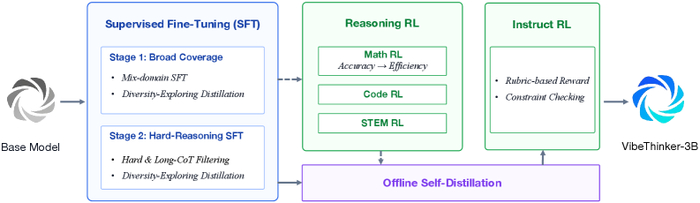
В процессе RL модель училась решать задачу и генерировать для неё вспомогательные структуры, динамически создавая стратегии, направляющие процесс решения. На каждом шаге RL модель сначала предлагала улучшенный каркас, затем на его основе генерировала траекторию, при этом награда оптимизировала оба этапа совместно.
Борясь со взломом системы вознаграждения, защиту разбили на три уровня. Внешние границы (окружение, инструменты, изоляция тестов) сделали неизменяемыми. Попытки чтения запрещённых файлов или модификации скриптов отсекли детерминированным монитором, обнуляя награду. Скрытые манипуляции, не нарушающие формальные правила, отсеивали замороженным LLM-судьёй.
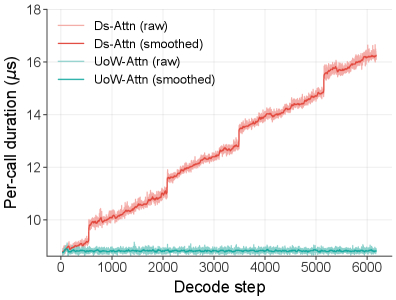
Для длинных траекторий применяли конвейерный RL с экспоненциальным затуханием весов токенов по их возрасту, чтобы смягчить проблему генерации вне политики.
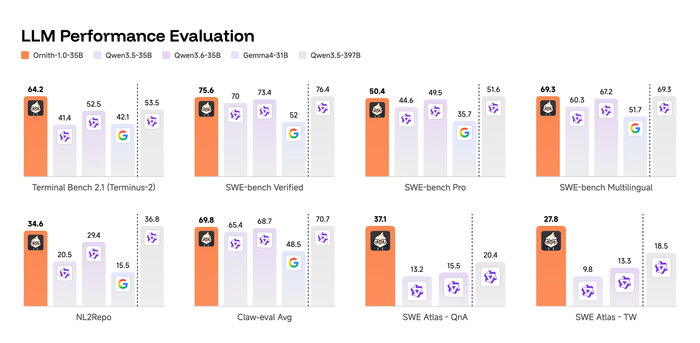
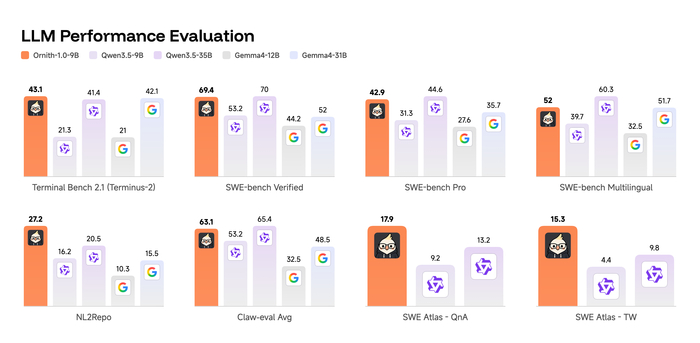
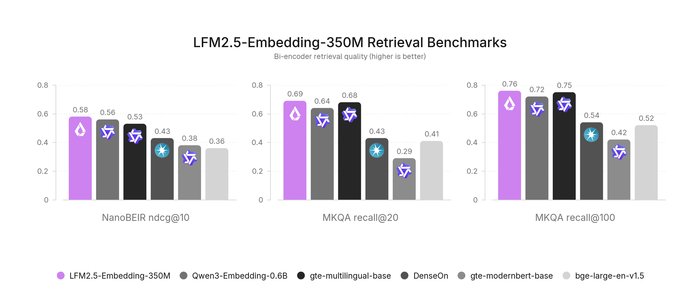
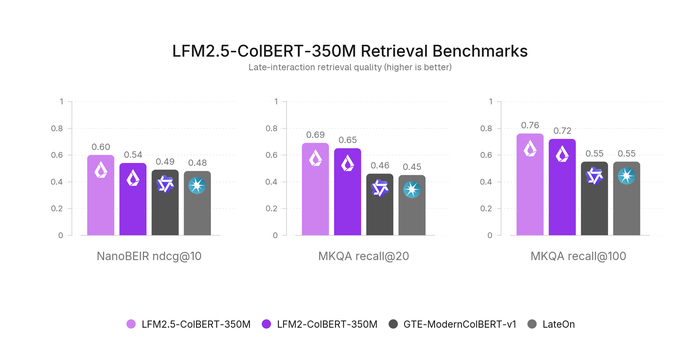
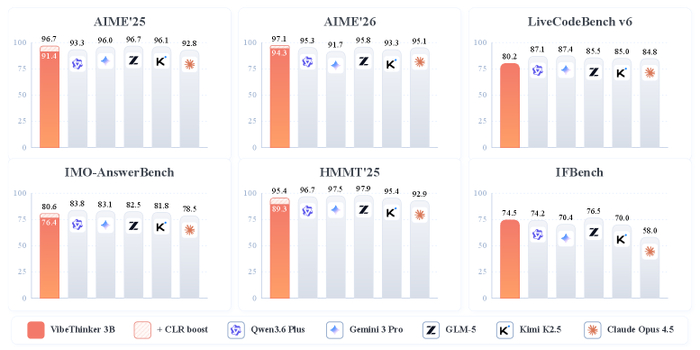
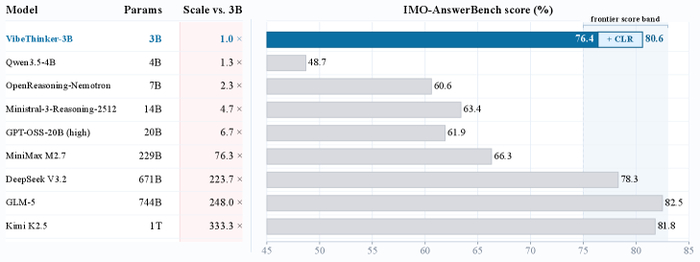
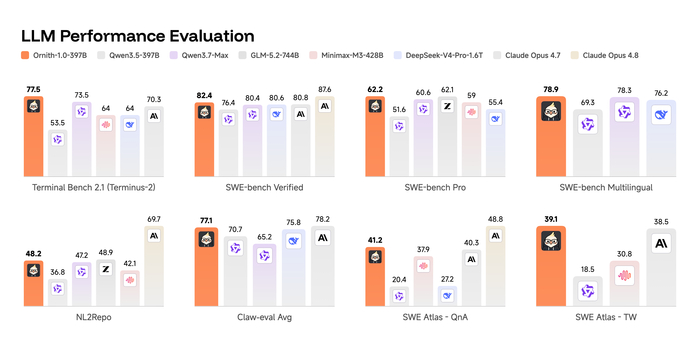
В результате Ornith-1.0-397B показывает state-of-the-art среди open-source, набрав 77.5 на Terminal-Bench 2.1 и 82.4 на SWE-Bench Verified, превосходя Claude Opus 4.7 и сравнимые открытые модели (MiniMax M3, DeepSeek-V4-Pro). Компактная 9B-версия обошла гораздо более крупные модели (Gemma 4-31B), обеспечив сильные агентные способности на периферийных устройствах.