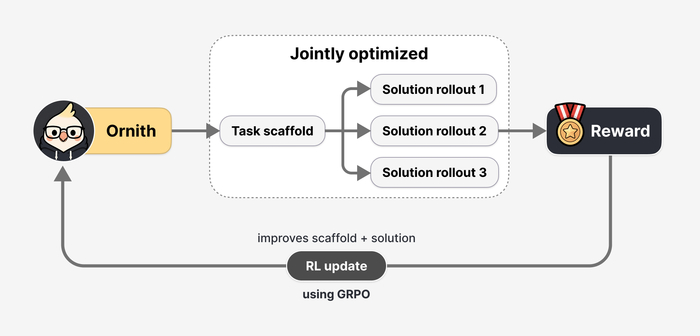
В процессе RL модель училась решать задачу и генерировать для неё вспомогательные структуры, динамически создавая стратегии, направляющие процесс решения. На каждом шаге RL модель сначала предлагала улучшенный каркас, затем на его основе генерировала траекторию, при этом награда оптимизировала оба этапа совместно.
Борясь со взломом системы вознаграждения, защиту разбили на три уровня. Внешние границы (окружение, инструменты, изоляция тестов) сделали неизменяемыми. Попытки чтения запрещённых файлов или модификации скриптов отсекли детерминированным монитором, обнуляя награду. Скрытые манипуляции, не нарушающие формальные правила, отсеивали замороженным LLM-судьёй.
Для длинных траекторий применяли конвейерный RL с экспоненциальным затуханием весов токенов по их возрасту, чтобы смягчить проблему генерации вне политики.
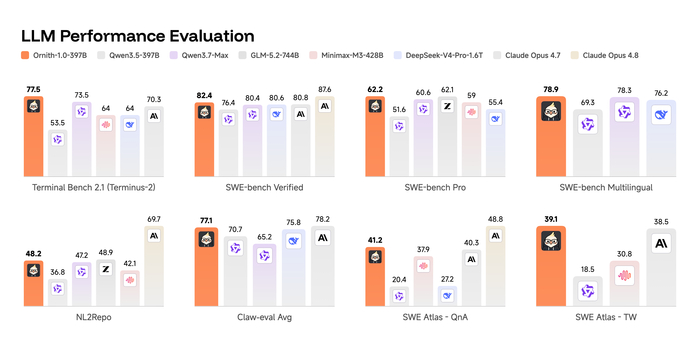
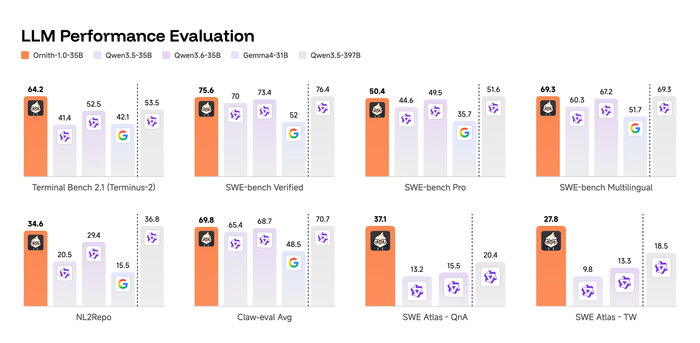
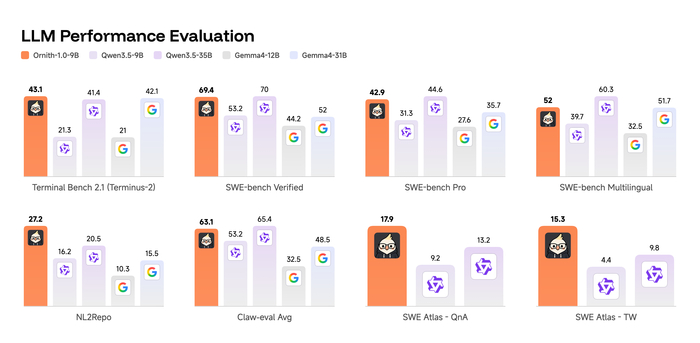
В результате Ornith-1.0-397B показывает state-of-the-art среди open-source, набрав 77.5 на Terminal-Bench 2.1 и 82.4 на SWE-Bench Verified, превосходя Claude Opus 4.7 и сравнимые открытые модели (MiniMax M3, DeepSeek-V4-Pro). Компактная 9B-версия обошла гораздо более крупные модели (Gemma 4-31B), обеспечив сильные агентные способности на периферийных устройствах.
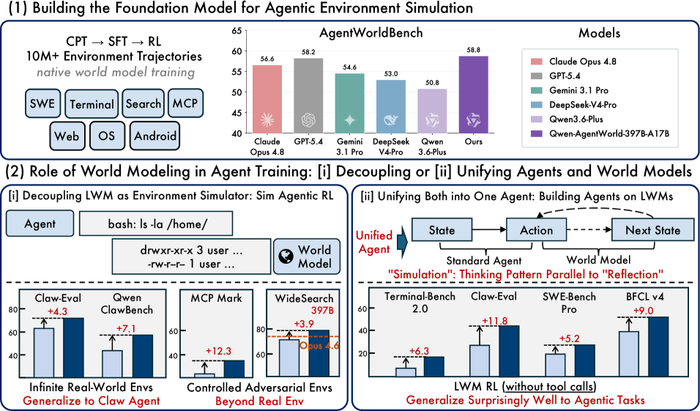
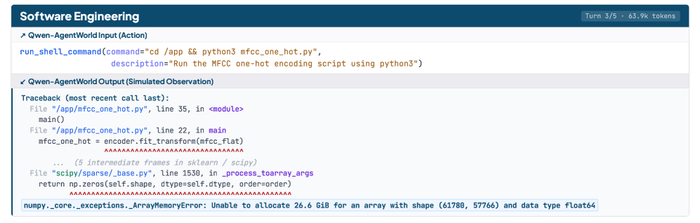
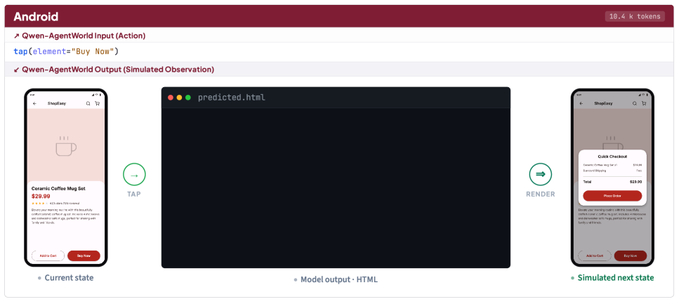
Описана первая нативная модель мира Qwen-AgentWorld (https://huggingface.co/collections/Qwen/qwen-agentworld), охватывающая 7 доменов (MCP, Search, Terminal, SWE, Android, Web, OS) через длинные цепочки рассуждений для общих агентов, позволяющая предсказывать состояние среды по истории взаимодействий и действию агента, дополняя политику.
Первая стадия обучения CPT ввела знания о динамике сред и предметных областях (более 10 млн траекторий и спецкорпуса), вторая стадия SFT активировала явное предсказание следующего состояния как шаблона мышления, третья стадия RL повысила точность симуляции с помощью гибридной награды (рубрики ИИ-судьи и детерминированные правила).
Симуляцию сред успешно масштабировали, воспроизведя тысячи сред (например, 4k реальных OpenClaw) без инфраструктуры. Выполненное на симулированных средах RL агента дало прирост на реальных бенчмарках (Claw-Eval +4.3, QwenClawBench +7.1). Контроль целевыми инъекциями возмущений (ошибки, неполные ответы) в процессе тренировки агента позволил превзойти обучение только на реальных средах (MCPMark +12.3, WideSearch +16.3), а реалистичные вымышленные миры для поискового RL предотвратили утечку параметрических знаний.
LWM-тренировка, применённая как основа агента, послужила разогревом перед прикладными задачами, улучшая показатели на 7 агентных бенчмарках (Terminal-Bench 2.0, SWE-Bench, WideSearch, Claw-Eval и других) за счёт способности мысленно моделировать реакцию среды до совершения действия.
В результате оценки 5 измерений (формат, фактологичность, согласованность, реалистичность и качество) бенчмарк AgentWorldBench, состоящий из реальных взаимодействий 5 передовых моделей на 9 классических задачах, продемонстрировал превосходство Qwen-AgentWorld-397B-A17B над всеми передовыми моделями (средний балл 58.71 против 58.25 у GPT-5.4).
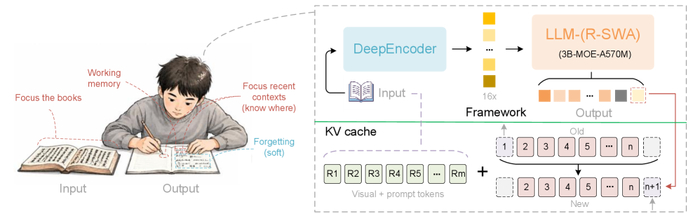
У одноэтапных OCR-моделей с LLM-декодером при длинных выводах линейно растёт KV-кеш, замедляя генерацию и увеличивая расход памяти, в отличие от человека.
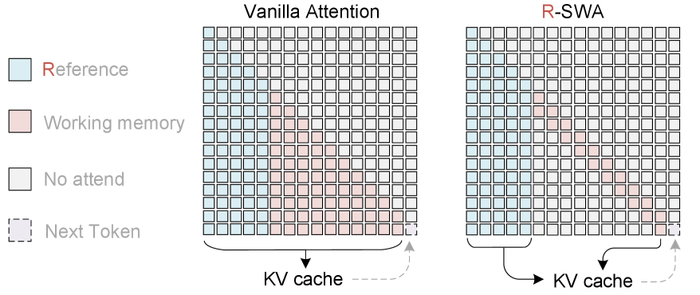
Unlimited OCR (https://huggingface.co/baidu/Unlimited-OCR) работает по-другому, заменяя все слои внимания декодера на предложенное референтное внимание со скользящим окном (R-SWA).
Базой выбрали DeepSeek OCR, включающий DeepEncoder с высокой компрессией и MoE-архитектуру с 3B параметров, из которых 0.5B активны.
Архитектура R-SWA даёт каждому токену видеть все референс-токены (визуальные и промт) и лишь последние n выходных токенов (по умолчанию 128), поэтому KV-кеш постоянен и визуальные признаки не "размываются", так как исключены из переходов состояний.
Сейчас истинно неограниченный парсинг упирается в длину входной обработки, хотя в будущем планируют удлинить контекст и встроить механизм динамической подгрузки этих данных. Притом R-SWA перспективно для ASR, перевода и других задач с длинным горизонтом.
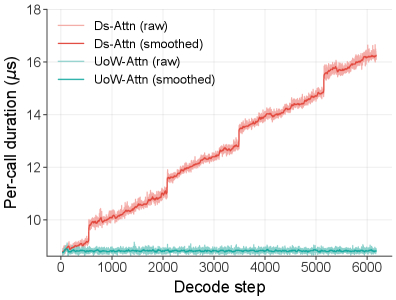
В результате общая оценка набрала 93% на OmniDocBench v1.5 (+6% к базовому DeepSeek OCR). Была реализована возможность однопроходного парсинга десятков страниц документа при фиксированном KV-кеше и постоянной скорости декодирования, а при 6K токенов вывода скорость (TPS) на 35% выше, чем у DeepSeek OCR, за счёт устранения линейного роста затрат.
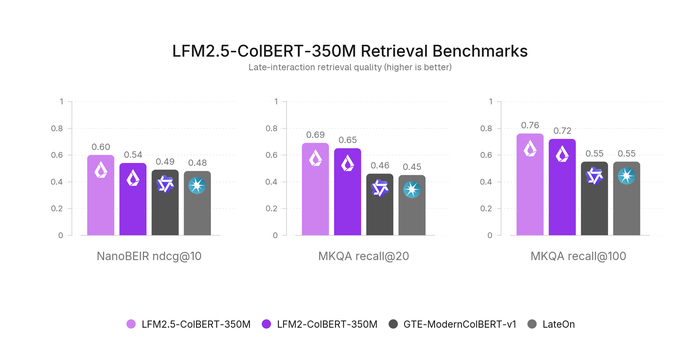
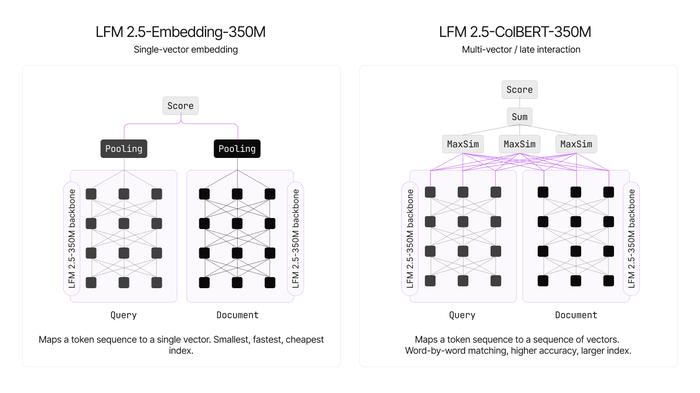
Версия Embedding создаёт один плотный вектор на документ, стремясь получить максимальную скорость при минимальном размере индекса, а версия ColBERT генерирует по одному вектору на токен, используя позднее взаимодействие (MaxSim) и обеспечивая повышенную способность к обобщению, хотя индекс становится больше.
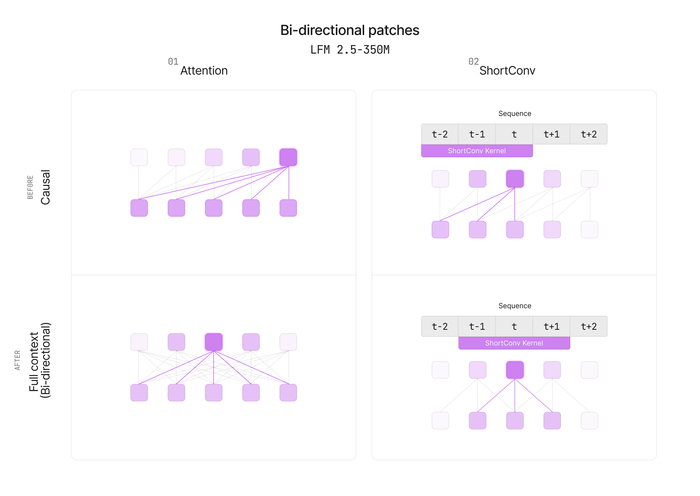
Архитектуру модифицировали, и каузальную маску заменили на двунаправленную, что позволило каждому токену видеть левый и правый контекст. Короткие свёртки LFM2 сделали некаузальными (симметричное локальное смешивание). Из общего двунаправленного энкодера достают либо CLS‑пулинг (Embedding), либо токенные эмбеддинги (ColBERT).
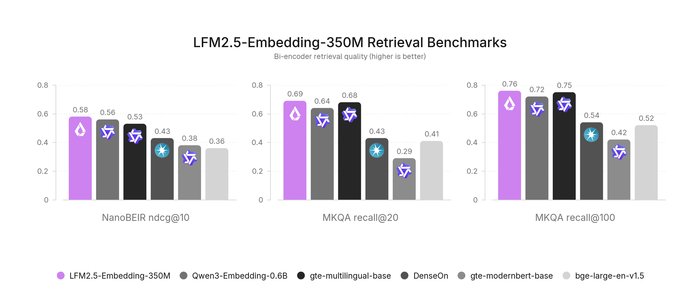
На первой стадии обучения проходило крупномасштабное сопоставительное предобучение на английском. Затем следовала стадия мультиязычной и кросс‑язычной дистилляции с сильного учителя (все 11 языков). Конечной стадией была тонкая настройка на сложных негативных примерах. Для всего процесса потребовались данные, извлечённые из курируемых внутренних и открытых английских датасетов, LLM‑перевод запросов и документов, чтобы расширить мультиязычность.
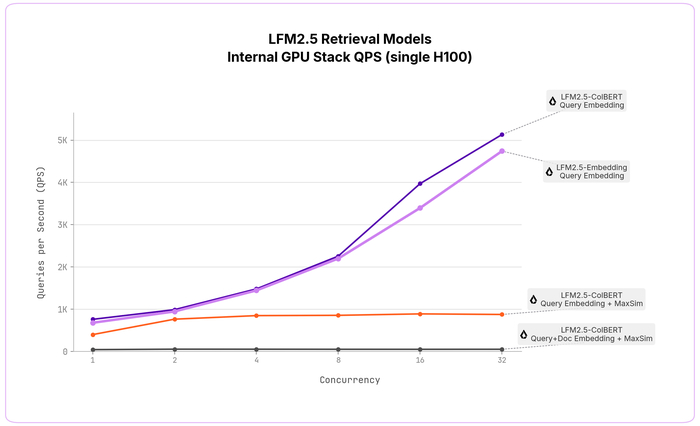
В результате обе модели имеют лучшие в классе показатели с 350M параметров по всем 11 языкам (арабский, немецкий, английский, испанский, французский, итальянский, японский, корейский, норвежский, португальский и шведский), пройдя мультиязычный поиск NanoBEIR, где NanoBEIR English признан подходящим заменителем для полного BEIR (корреляция, сдвиг около 15%), и кросс‑язычные ответы на вопросы MKQA‑11.
LLM-агенты сталкиваются с проблемой избыточного потребления токенов и засорения контекста при поиске релевантного кода в репозитории, поскольку обычно исследование и решение задачи выполняет одна модель.
Решением стал специализированный под-агент FastContext для разведки репозитория, отделённый от основного решающего агента, который вызывается по запросу, выполняет параллельные вызовы инструментов (Read, Glob, Grep) и возвращает компактный контекст с путями к файлам и диапазонами строк.
Исследовательские модели размером 4B-30B параметров обучались в два этапа. На первом этапе метод SFT (имитация) использовал траектории сильной модели для широкого поиска, сбора улик за несколько шагов и точного цитирования. На втором этапе пошёл метод RL с наградой, привязанной к релевантным строкам из эталонного патча.
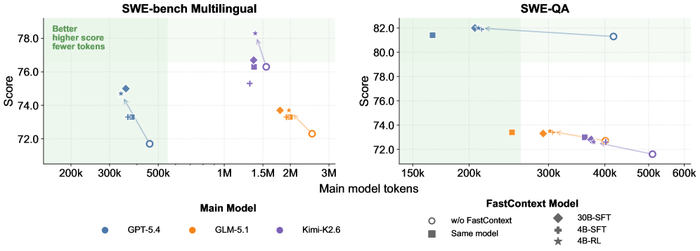
В результате в составе Mini-SWE-Agent (бенчмарки SWE-bench Multilingual, Pro, SWE-QA) доля решённых задач повысилась до +5,5%, а расходы токенов основного агента сократились до 60% при минимальных накладных расходах на исследователя.
Нейросети уже умеют составлять планы, объяснять сложные темы, готовить документы, анализировать данные и помогать с продажами. Но большинство людей всё равно не пользуется ими регулярно.
Причина простая: сервисов слишком много, советы часто поверхностные, а начать предлагают сразу с десятка инструментов. Человек тратит вечер на обзоры, открывает несколько вкладок и в итоге не решает ни одной своей задачи.
Проблема не в отсутствии способностей. Проблема в неправильной точке старта.
Вам не нужно сначала изучать устройство искусственного интеллекта. Нужно выбрать одну задачу, получить измеримый результат и только после этого расширять набор инструментов.
Где нейросети полезны уже сейчас
🏠 Для жизни
Можно составить меню на неделю с учётом бюджета, подготовить маршрут поездки, сравнить варианты покупки, разобрать длинную инструкцию или превратить список дел в понятный план.
Пример запроса: «Составь меню на пять дней для семьи из трёх человек. Бюджет 5000 рублей. Блюда должны готовиться не дольше 40 минут. В конце сделай общий список покупок».
Нейросеть не принимает решение вместо вас. Она быстро создаёт первый вариант, который проще проверить и исправить, чем начинать с пустого листа.
🎓 Для учёбы
Нейросеть может объяснить тему простыми словами, сделать конспект, подготовить вопросы для самопроверки и помочь составить план подготовки к экзамену.
Важно не просить «реши за меня». Полезнее написать: «Объясни тему на простом примере, затем задай мне пять вопросов и проверь ответы».
Так инструмент помогает понять материал, а не просто выдаёт готовый ответ.
Как выбрать нейросеть для задачи: четыре шага
Следите за новыми материалами и обновлениями в канале ЦИФРА в MAX.
Самая быстрая польза появляется в повторяющихся задачах: письмах, отчётах, таблицах, протоколах встреч, презентациях и подготовке к звонкам.
Например, вместо просьбы «напиши письмо» дайте контекст: «Подготовь короткое письмо клиенту. Он задерживает согласование на неделю. Тон спокойный и деловой. Нужно уточнить срок и предложить созвон на 15 минут».
Вы получаете основу за минуту, проверяете факты и редактируете под ситуацию.
📈 Для бизнеса
Нейросети помогают изучать вопросы клиентов, готовить варианты офферов, создавать контент, улучшать скрипты продаж и находить слабые места в воронке.
Но здесь особенно опасна автоматизация ради автоматизации. Если процесс сам по себе не работает, нейросеть только ускорит выпуск слабого результата.
Как выбрать нейросеть: четыре шага
Назовите результат. Не «хочу внедрить ИИ», а «хочу сократить подготовку отчёта с двух часов до тридцати минут».
Выберите одну операцию. Сбор данных, черновик текста, анализ или оформление.
Проведите небольшой тест. Возьмите реальную задачу и сравните результат с привычным способом.
Зафиксируйте удачный процесс. Сохраните промпт, входные данные и критерии проверки.
Практический пример: продажа онлайн-курса
Предприниматель хочет повысить конверсию страницы курса.
Сначала он формулирует цель: увеличить количество заявок на 20 процентов. Затем собирает реальные вопросы и возражения клиентов. Нейросеть группирует их по темам и предлагает новые варианты заголовка, блока программы и ответов на сомнения.
После этого создаются два варианта страницы. Меняется только один элемент, например заголовок. Варианты тестируются на реальной аудитории.
Здесь нейросеть не обещает рост сама по себе. Она ускоряет подготовку гипотез, а решение принимается по результатам теста.
Ошибки, которые мешают получить пользу
❌ Слишком общий запрос. «Сделай хорошо» не объясняет аудиторию, цель и формат.
❌ Ожидание идеального первого ответа. Сильный результат обычно появляется после двух или трёх уточнений.
❌ Публикация без проверки. Нейросеть может ошибиться в фактах, ссылках и цифрах. Ответ всегда проверяет человек.
❌ Одновременное внедрение десяти сервисов. Один рабочий сценарий полезнее большой коллекции инструментов без практики.
План внедрения на семь дней
День 1. Выберите одну повторяющуюся задачу.
День 2. Опишите желаемый результат и ограничения.
День 3. Сделайте первый запрос.
День 4. Добавьте примеры и уточните формат.
День 5. Сравните время и качество с обычным способом.
День 6. Сохраните удачный промпт и чек-лист проверки.
День 7. Повторите процесс на новой реальной задаче.
✅ Вывод
Нейросети не требуют резкого изменения всей жизни или бизнеса. Начните с маленькой задачи, проверьте пользу и сохраните рабочий способ. После первого понятного результата страх исчезает, потому что вместо абстрактной технологии появляется конкретный помощник.
Начните с одной реальной задачи
Что сделать сейчас?
Бесплатные уроки и новые материалы
Начните с понятного гайда «Нейросеть с нуля». Внутри - три бесплатных урока: что такое нейросети, как написать первый промпт и какие инструменты доступны в России.
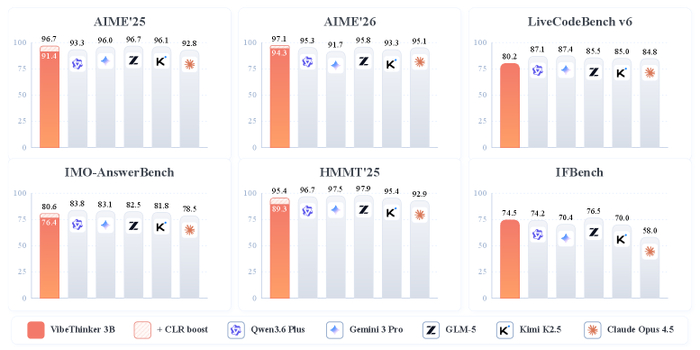
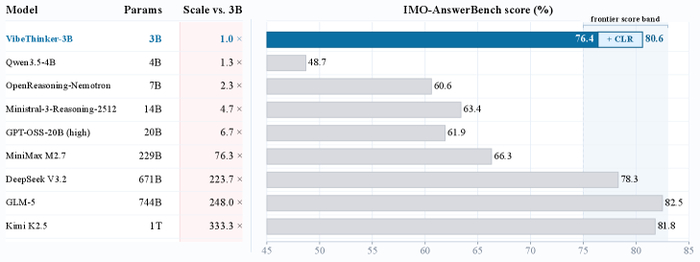
Озвучена новая модель VibeThinker-3B (https://huggingface.co/WeiboAI/VibeThinker-3B), показывающая, что компактная версия с 3 млрд параметров способна достичь уровня флагманских LLM на задачах с проверяемой логикой (математика, код, STEM).
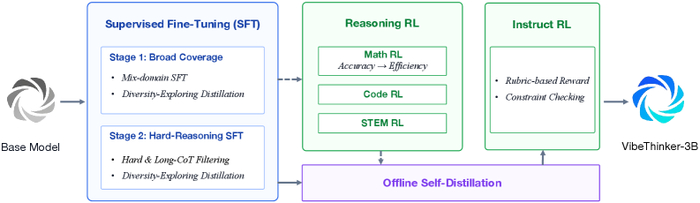
Пайплайн развивали от "Спектра" к "Сигналу", проходя через SFT и двухэтапное обучение по учебному плану, когда сначала шло широкое покрытие предметов, а затем фокус на трудных длинноцепочечных рассуждениях с финальной дистилляцией, которая сохраняла разнообразие решений. Дальнейший RL представлял собой мультидоменное (математика, код, STEM) обучение с алгоритмом MGPO, единым длинным контекстом (64K) и этапом "Long2Short" для повышения эффективности токенов без потери точности. Отбором и интеграцией лучших траекторий из разных доменов занималась офлайн-самодистилляция. Instruct RL настраивал строгое следование инструкциям без ущерба для рассуждений.
Гипотеза параметрического сжатия-покрытия утверждает, что способности моделей можно разделить на два типа. Способности первого типа, называемые параметрически плотными (верифицируемые рассуждения), могут быть "сжаты" в компактное ядро, не требуя гигантского объёма памяти. Способности второго типа, известные как параметрически экспансивные (открытые знания, общая эрудиция), нуждаются в широком покрытии фактов и длинном хвосте, что приводит к разрыву на GPQA-Diamond (70.2).
В результате её математические умения составляют 94.3 на AIME26 (97.1 с тест-тайм стратегией CLR), 89.3 (95.4) на HMMT25, 80.2 при Pass@1 на LiveCodeBench v6 и 76.4 (80.6) на IMO-AnswerBench, а принятые 96.1% на LeetCode (с апреля по май 2026 года) решения на новых соревнованиях сравнимы с GPT-5.2 и Gemini 3 Flash. На верифицируемых бенчмарках она сопоставима или превосходит модели масштаба DeepSeek V3.2 (671B), Kimi K2.5 (1T) и Gemini 3 Pro, при этом сохраняя инструкционную управляемость (IFEval 93.4).