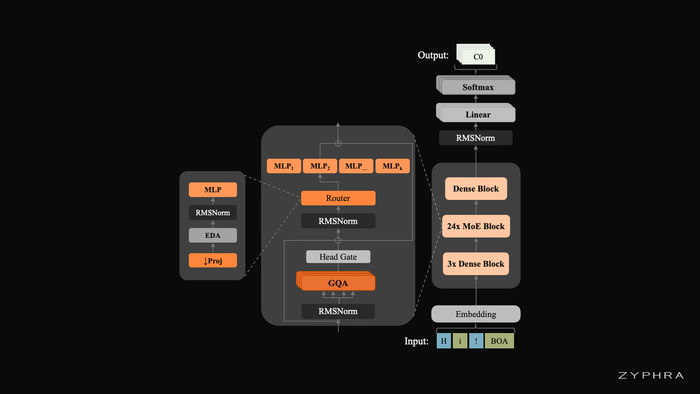
🔌 Совместимость с RTX 3090 / 4090 — изоляция процессов llama.cpp и PyTorch через фоновый демон-процесс (director_daemon.py); устраняет конфликты CUDA-контекстов и падения инференса; выгрузка моделей «на лету» для освобождения VRAM.
🧬 Длинный клон — озвучка сверхдлинных текстов и книг с автоматической разбивкой на фрагменты, пофрагментным авто-обогащением, синтезом частями и бесшовной склейкой с настраиваемой паузой.
🌐 Внешние LLM — глобальная интеграция с LM Studio / Ollama / OpenAI API (External API); перенаправление автоулучшения со всех вкладок на внешнюю модель; настраиваемый системный промпт режиссёра.
🧪 Тест подключения — кнопка быстрой проверки связи с внешним API и интерактивный редактор промптов с выводом подробных кодов ошибок в интерфейс.
💾 Автосохранение настроек GUI — сохранение и автоматическое восстановление всех параметров (моделей, голосов, слайдеров температуры/top-p) между запусками в локальном файле gui_config.json.
💻 Только CPU — переключатель в интерфейсе для полной обработки TTS и LLM на центральном процессоре (без использования видеокарты), что полностью освобождает VRAM.
🌑 Всегда темная тема — принудительное включение темной темы при первой загрузке без светлого мигания.
Только на CPU - работает, но ооооочень не быстро. Учитывая тест на 5950x :)
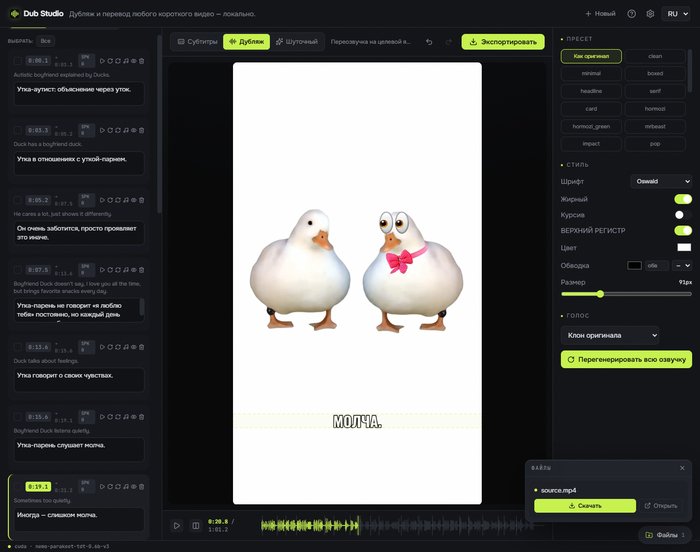
Dub Studio - локальная утилита для перевода коротких роликов. Та самая утка тоже тут.
Всем привет! Листал ленту тиктока и попался американский ролик про СДВГ, где всё объясняют на утках. Понравилось. И я подумал: классно было бы сделать такой же канал, только на русском.
Но я ленивый. Снимать, писать сценарии, делать всё с нуля - это скучно. А вот взять готовый ролик и перевести-переозвучить его на русский - вот это уже интересно, подумал я, а потом задумался, о том, как это автоматизировать. Это оказалось интересной инженерной задачей, которая увлекла меня на неделю времени, и привела к созданию ИИ утилиты с открытым исходным кодом. А тикток с утками я так и не создал...
Меня зовут Илья, я блогер, основатель сервиса для генерации ArtGeneration.me и просто фанат нейросетей. Я не разработчик в классическом смысле - скорее продакт с двадцатилетним стажем, который вайбкодит с нейросетями всё, что давно хотелось воплотить в жизнь.
Портативок я насобирал уже кучу, потому что для меня это самый быстрый способ протестировать технологию. Отдельно под озвучку, отдельно под распознавание речи. Но чтобы собрать всё это в один инструмент, где работает сразу из коробки - такого ещё не было. Заодно захотелось наконец слезть с Gradio, на котором я обычно делаю свои портативки.
Так появился Dub Studio - утилита, которая локально переводит и переозвучивает короткие ролики. Офлайн, бесплатно, без подписок и без цензуры. А та самая утка стала главным тестовым роликом проекта.
Дальше расскажу, как всё это собиралось и покажу примеры сделанные в этой же утилите.
❯ Почему шесть нейросетей, а не одна
Сначала я хотел обойтись одной моделью. Омнимодальной. Чтобы один мозг сразу и слушал звук, и смотрел картинку, и читал-переводил надписи на экране. Один файл, один прогон, никакой возни со склейкой.
Но была рамка. Дома у меня RTX 4090 на 24 гига, в неё влезает многое. А вот у большинства моих подписчиков 12 гигов и меньше. Пихать в инструмент жирные модели, которые у них просто не запустятся, мне не хотелось. Так что планку я поставил сразу под аудиторию: всё должно жить в 12 гигах VRAM. Иначе смысла нет.
Поресёрчил омни-модели. Вывод вышел неприятный: ни одна модель, которая влезает в 12 гигов, не умеет нормально размечать речь по времени и по говорящим за один проход. Это не я поленился покопаться, это просто потолок таких моделей, даже лучших. Кто где говорит и в какую секунду - они на этом плывут.
Реальный кандидат был один, MiniCPM-o, он по размеру проходил. Но до его тестов я даже не дошёл. Ещё на ресёрче стало понятно, что омни в принципе не вывозит аудио-тайминг, и запускать её смысла уже не было.
Не так изящно как мне бы хотелось, но и не 14 узлов как в начале
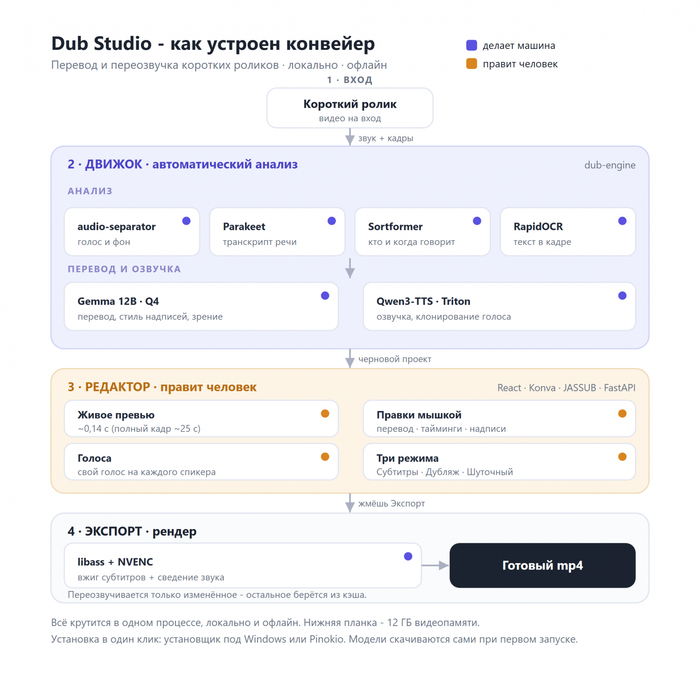
Поэтому в итоге не одна модель, а гибрид из шести специализированных. Каждая делает свой кусок и делает его хорошо:
экранный текст вытаскивает RapidOCR, а вжигает субтитры libass.
Да, шесть штук вместо одной звучит как перебор. Но каждая тут весит немного, все вместе укладываются в бюджет по памяти, и на своём участке работают лучше, чем одна большая модель на всём сразу.
❯ TTS: лучший из худших
Озвучка - это сердце дубляжа. Поэтому к выбору движка я подошёл серьёзнее всего.
TTS, который мне нужен, должен уметь клонировать голос. Не просто прочитать текст роботом, а звучать похоже на оригинал, в моём случае ещё и по-русски. Таких движков несколько, и я прогнал большое исследование: погонял кандидатов по метрикам.
Вывод вышел невесёлый. Идеального движка нет. Вообще. У каждого свой набор косяков.
Победил Qwen3-TTS, в сборке на Triton. Победил не потому, что не косячит. Косячит. Хуже всего у него с ударениями: периодически ставит их не туда, и тогда слово звучит не по-русски. Но из всех вариантов это самый адекватный компромисс. Он быстрый, лёгкий и работает быстрее реалтайма. Лучший из худших, если совсем честно.
И вот тут я хочу сказать вещь, которая тянется через весь проект. Он целиком собран на компромиссах. Gemma у меня квантованная, не полная. Сам процесс полу-автоматический, а не нажал кнопку и пошёл пить кофе. Везде, где можно было выбрать между идеально и просто работает, я выбирал второе. Иначе инструмента просто не было бы.
Выбор TTS, да, спорный. Я знаю, что многие со мной не согласятся. И это не просто так. Но про это позже.
❯ Прощай, Gradio
Сначала я хотел сделать совсем просто. Лёгкий CLI, полностью автоматический. Кидаешь ролик, получаешь готовый дубляж. Без рук, без редактора, без меня.
Не вышло. У каждого ролика своя верстка: надписи лезут не туда, разметка везде разная. Модели ошибаются. Универсального кинул и готово не существует. Чем дольше я это ковырял, тем понятнее становилось, что полностью без человека тут не выехать.
Так я пришёл к полу-автоматике. Движок берёт на себя тяжёлую часть: анализирует ролик, раскладывает умные дефолты. А человек правит остальное. Но правит не вслепую, а с живым превью, где сразу видно что получится.
Это Спарта? Нет, это ГРАДИО!
Тут стоит пояснить, что вообще такое Gradio - вдруг кто не сталкивался. Это питоновская библиотека для быстрых интерфейсов к нейросетям: парой строк кода оборачиваешь модель в простенькую веб-морду - поле ввода, кнопка, окошко с результатом, и всё, модель можно тыкать в браузере, а не гонять из консоли. Бутстрап для нейронок.
Принадлежит он Hugging Face - по сути это гитхаб для нейросетей, главный репозиторий ИИ-моделей. Поэтому с моделями оттуда Gradio дружит бесшовно: взял с хаба, обернул, выложил - всё заводится из коробки. Идеальная штука, чтобы по-быстрому собрать MVP, на нём собраны почти все мои портативки.
И вот тут стало ясно, что Gradio мне больше не помощник. Для демки он отличный. Но нормальный редактор на нём не собрать. Gradio - это один столбик, пара полей и готовых элементов и кнопка. А мне нужен холст, превью, субтитры поверх видео, перетаскивание.
Поэтому я взял нормальный фронт. React + Konva для холста, на нём всё рисуется и двигается. Субтитры кладутся сверху через JASSUB, прямо поверх видео. Бэкенд на FastAPI. А голый CLI к тому же грузил весь стек заново на каждый ролик, что радости тоже не добавляло.
❯ Редактор
Теперь как это работает в деле. Кидаешь ролик, движок прогоняет анализ и раскладывает умные дефолты: транскрипт, кто где говорит, какие надписи нашёл в кадре, готовый план субтитров. Дальше начинается пользовательская часть.
На Gradio, конечно, так не сделаешь
Дольше всего я бился над превью. Оно и сейчас по сути покадровое слайд шоу с аудио дорожкой, это так и задумано. Но поначалу оно тормозило так, что работать было невозможно. Полный рендер одного кадра шел около 25 секунд. Двадцать пять. Сидеть и ждать столько после каждого чиха в редакторе невозможно. Пришлось делать отдельный быстрый предпросмотр, тоже один кадр, но уже около 0.14 секунды. Вот после этого редактор и ожил.
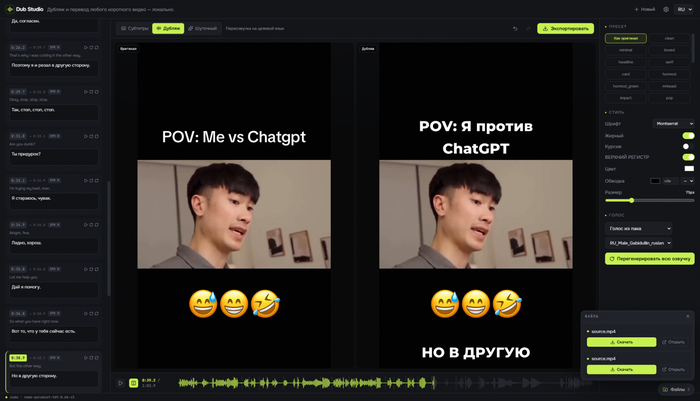
Каждый ролик можно гонять в одном из трёх режимов: Субтитры, Дубляж или Шуточный. Первые два понятны. С Шуточным интереснее: говоришь Gemma тему, она переписывает скрипт под неё, и кусок переозвучивается заново уже с новым текстом, мем сделанный в этом режиме ждет вас в конце статьи.
Голоса вешаются на каждого говорящего по отдельности. Один спикер - один голос из пака, другой - другой. Голосов в паке много и никто не мешает добавлять еще просто закидывая файлы в папку.
С субтитрами тоже всё руками. Не нравится, где стоит полоса - берёшь её мышкой и таскаешь прямо по кадру, куда надо.
Теперь переведённые надписи в самом видео. Хочется, чтобы они смотрелись как родные. Поэтому оригинал я не блюрю. Блюр мылит картинку и сразу выдаёт, что тут что-то подменили. Вместо этого оригинальная надпись кроется непрозрачной плашкой под цвет сцены. Где её положить, подсказывает OCR, а как оформить текст поверх, подсматривает зрение Gemma. Получается аккуратно.
И ещё про громкость. Реплики приходят разные по уровню. Поэтому все фразы приводятся к одному уровню.
❯ Честно про вайбкодинг
Раз уж пошёл такой разговор, расскажу честно про обратную сторону.
Этот проект тоже собран в паре с ИИ-агентом. Штука мощная, но есть одна боль, которая выматывала сильнее всего. Агент уверенно пишет тебе "готово, баг исправлен". А на деле ничего не исправлено. И ловишь ты это только сам, глазами.
Простой пример. Поправили субтитр в превью, всё хорошо. Запускаешь экспорт - а там та же самая ошибка на месте. Агент починил один путь и честно отчитался за оба.
Но больнее всего была не сама модельная часть. Больнее всего оказалась упаковка в один клик, через Pinokio. Агент взял обязательную зависимость и пометил её как необязательную. Вроде мелочь. А без неё весь дубляж просто падал. И отдельная радость - полдня ушло на одну ошибку с ffmpeg. Просто полдня на одну ошибку, подробности опущу.
Вывод для меня простой. Верить агенту на слово нельзя. Совсем. Поэтому всё, что он делает, проверяешь сам. Каждый раз.
❯ Стек и как это работает
Если убрать всю кухню, алгоритм простой.
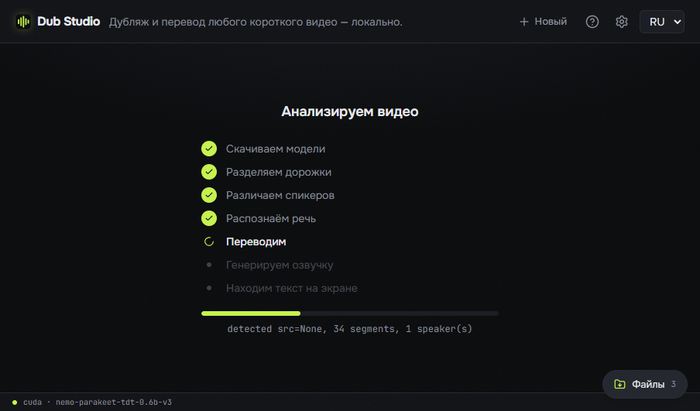
Кидаешь видео в окно. Дальше движок сам прогоняет весь конвейер: снимает транскрипт, режет на сегменты по спикерам, вытаскивает надписи с экрана, собирает план субтитров с разумными дефолтами. На выходе готовый проект, который можно открыть и крутить.
Дальше правишь руками. Меняешь перевод, двигаешь тайминги, перебираешь надписи - и всё это с живым превью, видно сразу. Когда всё нравится, жмёшь экспорт. Тут важный момент: переозвучивается только то, что ты трогал. Остальное берётся из кэша, заново гонять весь ролик не нужно. На выходе готовый mp4.
❯ Это бета, и ей нужны вы
Я доволен тем, что получилось. Сам этим пользуюсь, и это уже не игрушка. Но давайте честно: это бета. Работы ещё хватает.
Поэтому про ограничения прямо. Заточено всё в основном под короткие ролики. Выбор TTS спорный, и я это прекрасно понимаю - многие со мной не согласятся по поводу того, какой голос лучше. Языков можно тащить больше, чем сейчас доступно. Технически и ттс и ллм их поддерживает больше, но каждый язык надо тестить руками, а это время.
В планах сделать все модули сменными. Раз уж столько споров вокруг TTS, логичный ход - дать каждому собрать пайплайн под себя. Не нравится распознавалка - воткни свою. Не нравится речь - поставь другой. Хочется, чтобы это был конструктор, а не приговор.
Кстати, стек так удачно лёг, что я потащил его и в другие свои проекты, например в днд игру где нейросеть выступает гейм-мастером. Но это уже отдельная история, под новую статью, так что как-нибудь в другой раз.
Теперь самое важное. Репозиторий открыт, лицензия MIT, код тут - берите и делайте. Форкайте, шлите PR и заводите issue. Если что-то сломалось или работает не так - расскажите. А ещё лучше - прогоните свой ролик и киньте результат в комменты, очень интересно посмотреть, что у вас выйдет. И если проект вам зашёл, поставьте звезду на гитхабе, мне будет приятно, а ему полезно.
Найти меня можно в YouTube, в Телеграме и на Бусти. Залетайте, там тоже интересно, каждую пятницу смотрим новинки нейросетей и генерируем вместе. Всех обнял и удачных дубляжей.
Введена новая TTS-модель ZONOS2 (https://huggingface.co/Zyphra/ZONOS2) для работы в реальном времени с высокоточным клонированием голоса под лицензией Apache 2.0.
Его разреженный Mixture of Experts (MoE) обладает 8 млрд параметров и 900 млн активных, став первым открытым MoE TTS.
Гибкие настройки дают выбор между "стабильным" (чистый студийный звук) и "экспрессивным" (максимальная верность исходному голосу) режимами.
Обучение осуществлялось на более 6 млн часов аудио с трёхэтапной фильтрацией при постепенном ужесточении требований к согласованности транскриптов.
Текст подвергают токенизации в формате сырых UTF-8 байтов без фонемизации. Аудио преобразуют в токены кодека DAC (44.1 кГц), используя автогрессивный паттерн задержки.
Среди настроек есть цифровой отпечаток голоса (ECAPA-TDNN), скорость речи, качественные параметры (полоса, громкость, SNR).
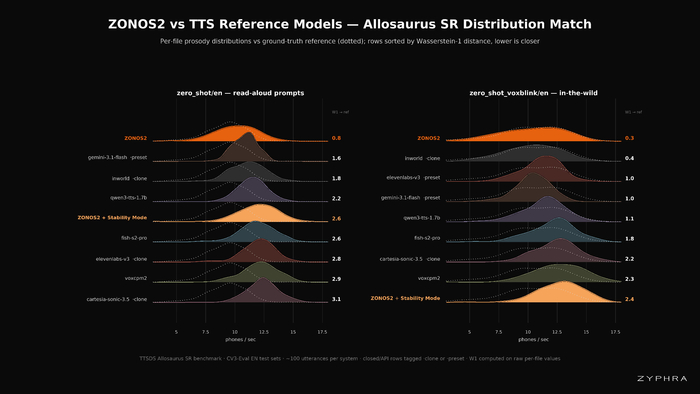
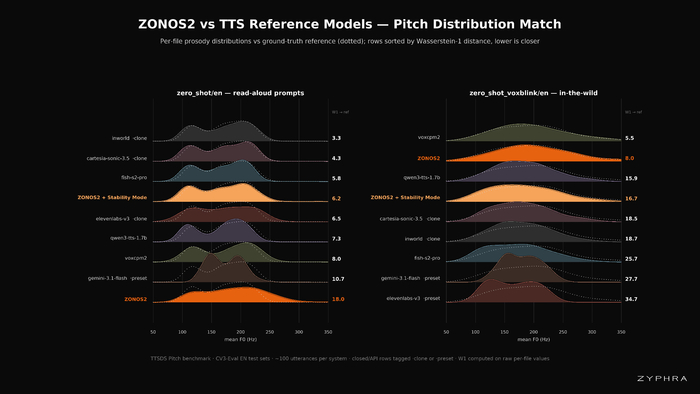
Представленный эталон ZTTS1‑Eval показал чистые (FLEURS‑R) и "дикие" (VoxBlink2) выборки, метрики интонации и ритма (Allosaurus SR, Pitch, DS‑WED), схожесть диктора (ReDimNet) и качества (MSR‑UTMOS, Qwen3‑ASR).
В результате обеспечен 4-кратный прирост скорости против предыдущей версии и качество на уровне ведущих решений.
Делаю пайплайн автодубляжа: на входе англоязычный ролик — на выходе русская озвучка тем же голосом. Сердце такого пайплайна — нейросеть клонирования голоса (voice-clone TTS). Главный вопрос: какую взять?
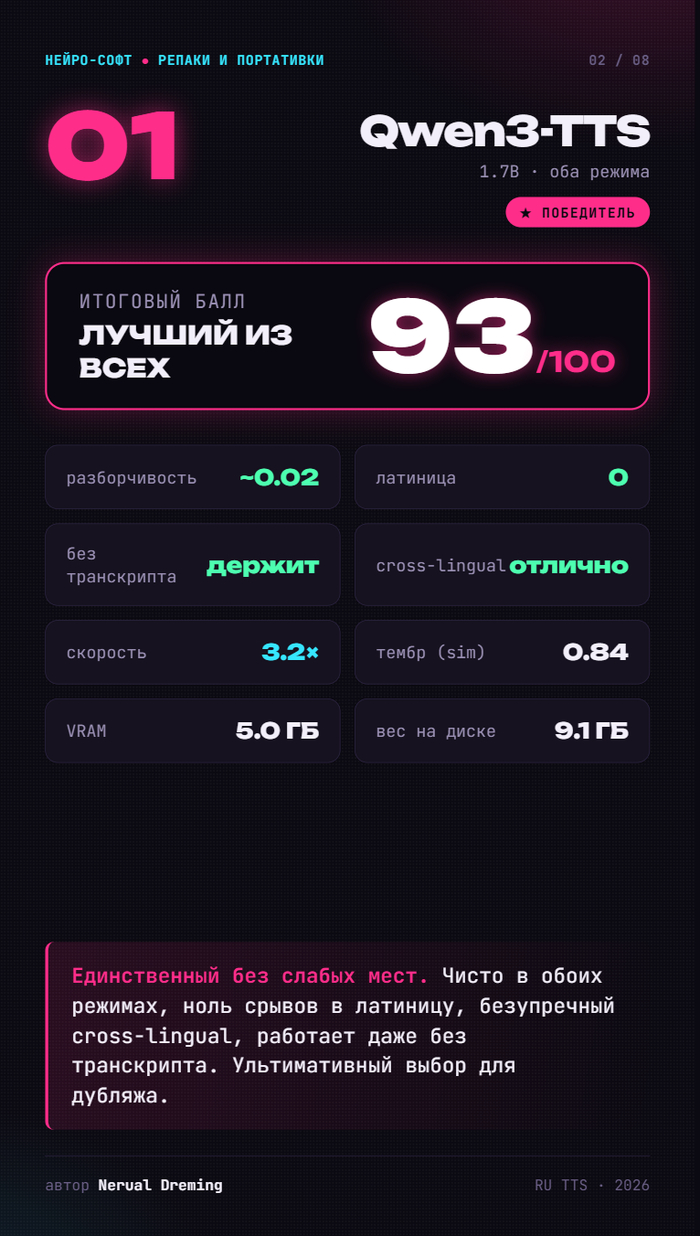
1/8
Можно ткнуть в первую попавшуюся с хайпом. А можно собрать топовые движки и устроить им честную битву на одинаковых условиях. Выбрал второе — прогнал финалистов через 627 семплов. Итоговый рейтинг — в карусели ниже, а вся подноготная (с чего начинали, кого выгнали и почему) — под ней.
Как собирал участников
Брал не наугад, а по реальным лидербордам (TTS Arena, Artificial Analysis) — только свежие флагманы. Часть кандидатов отсеялась сразу на входе: VibeVoice умеет только стриминг, OpenAudio S1 — прошлогодний, IndexTTS-2 — русский сломан, Step-Audio — только англ/кит. Осталось 8 движков для реального прогона.
Методология
Каждому движку — 114 фраз, всего 627 семплов. Тесты: русский и английский, длинные реплики, числа (прописью и цифрами), аббревиатуры (СДВГ, ОКР), иностранные слова, имена, скороговорки, смесь языков. И главное — cross-lingual: английский голос читает русский текст. Это и есть дубляж.
Оценивал на слух, семантически: засчитано всё, что произнесено верно. Если распознавалка записала «десять» как «10», а «Stable Diffusion» как «стейбл дифьюжн» — это её косяк, а не движка: зритель-то слышит правильно. Метрики: разборчивость, похожесть голоса, утечка латиницы, скорость, VRAM, вес на диске. Итоговый балл взвесил под задачу дубляжа.
Двоих выгнали сразу
После предварительного прогона вылетели двое:
dots.tts — на женском голосе разваливался: вместо русского текста выдавал английскую кашу или просто тишину. Плюс самый медленный. На вылет.
Chatterbox — умеет только режим без транскрипта, говорит с заметным акцентом, по сумме не конкурент. Тоже за борт.
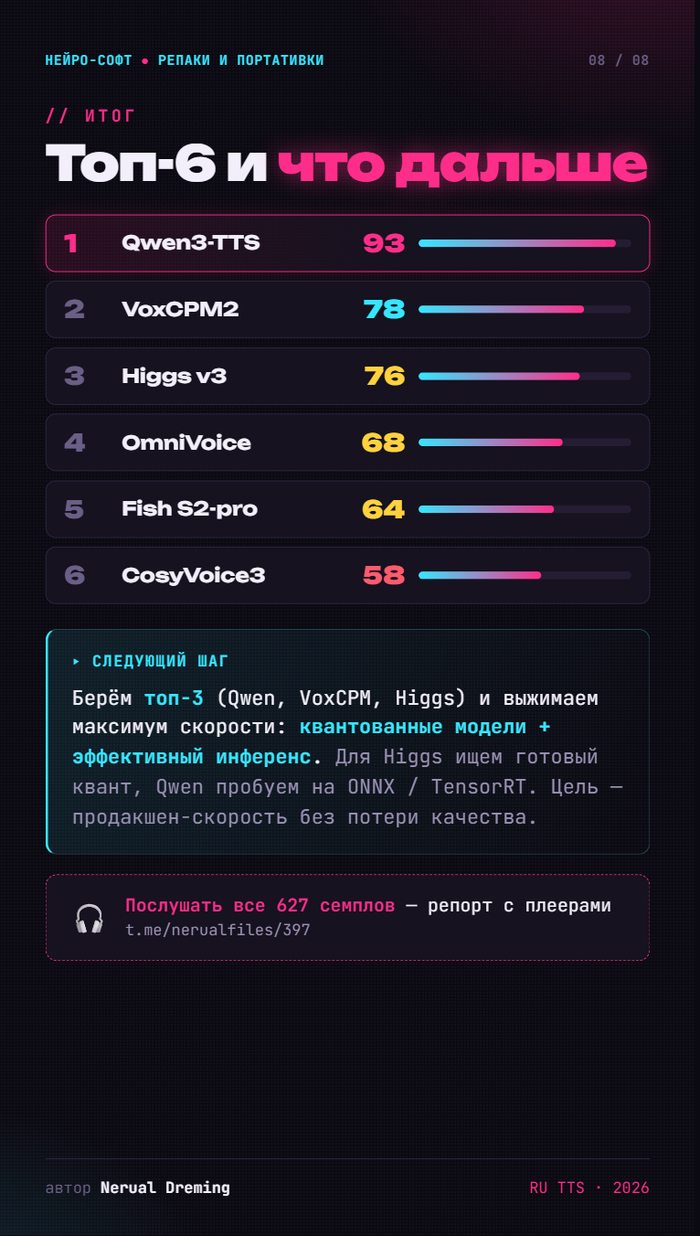
Осталось 6 финалистов — детально по каждому в карусели выше, тут коротко:
Финалисты
🥇 Qwen3-TTS — 93/100. Чемпион. Единственный без слабых мест: чистая речь и с транскриптом, и без, ноль срывов в латиницу, безупречный cross-lingual, быстрый. Его и берём.
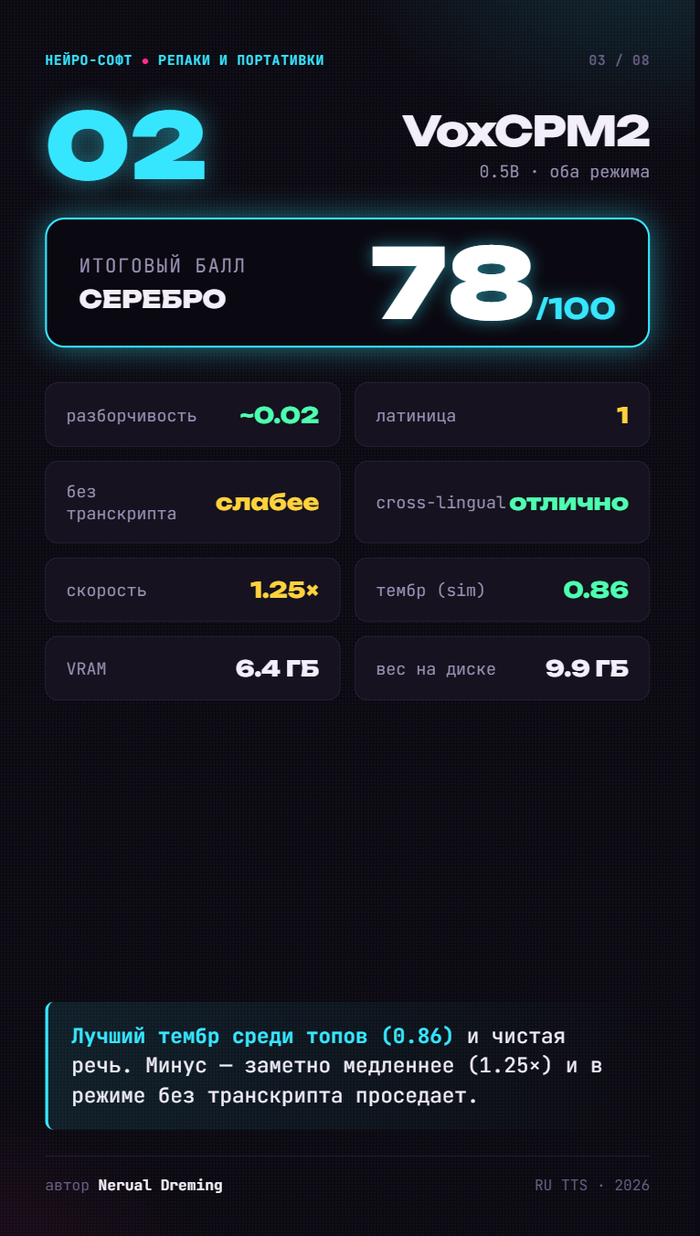
🥈 VoxCPM2 — 78. Лучший тембр среди топов, чистая речь. Минус — медленный и без транскрипта проседает.
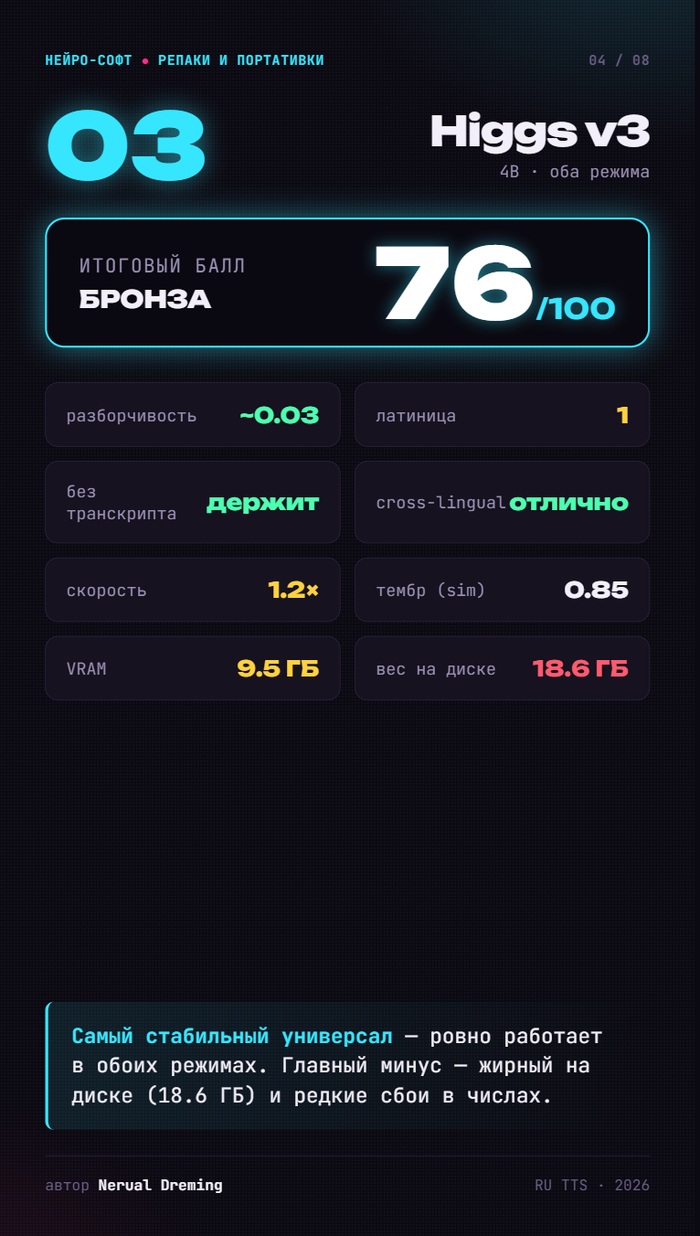
🥉 Higgs v3 — 76. Самый стабильный универсал. Главная беда — 18.6 ГБ на диске.
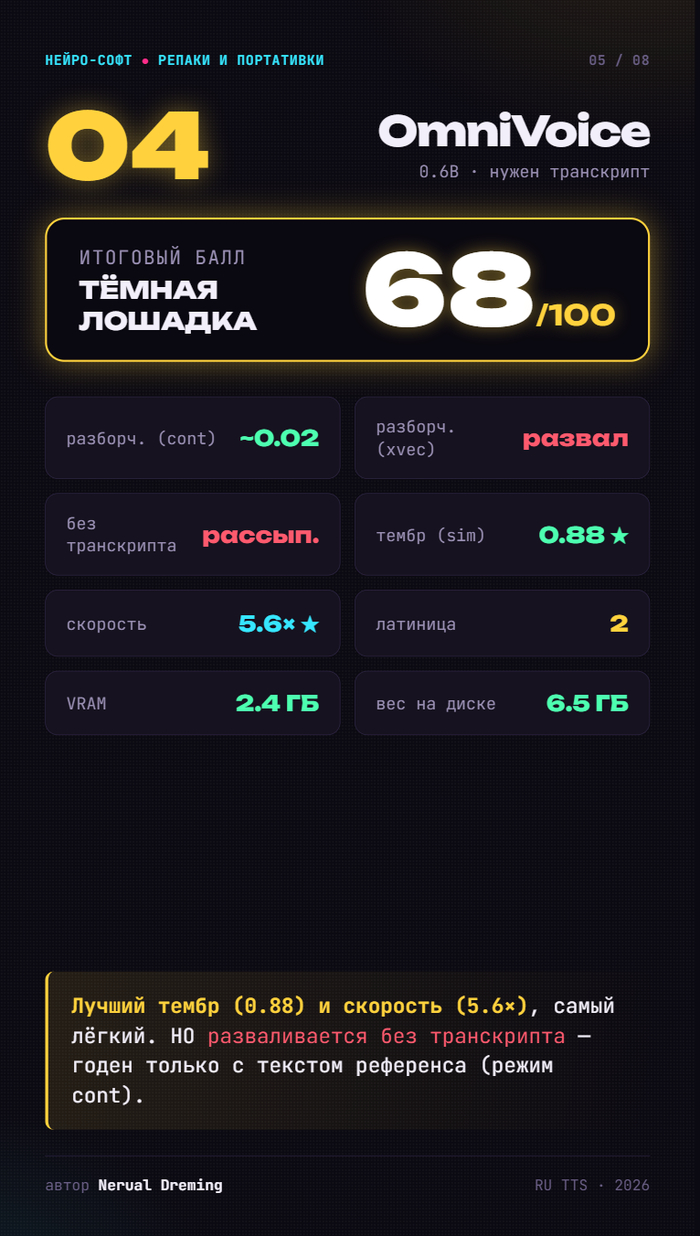
OmniVoice — 68. Тёмная лошадка: лучший тембр (0.88) и самый быстрый (×5.6 от реалтайма), легчайший. НО разваливается без транскрипта — годен только с текстом референса.
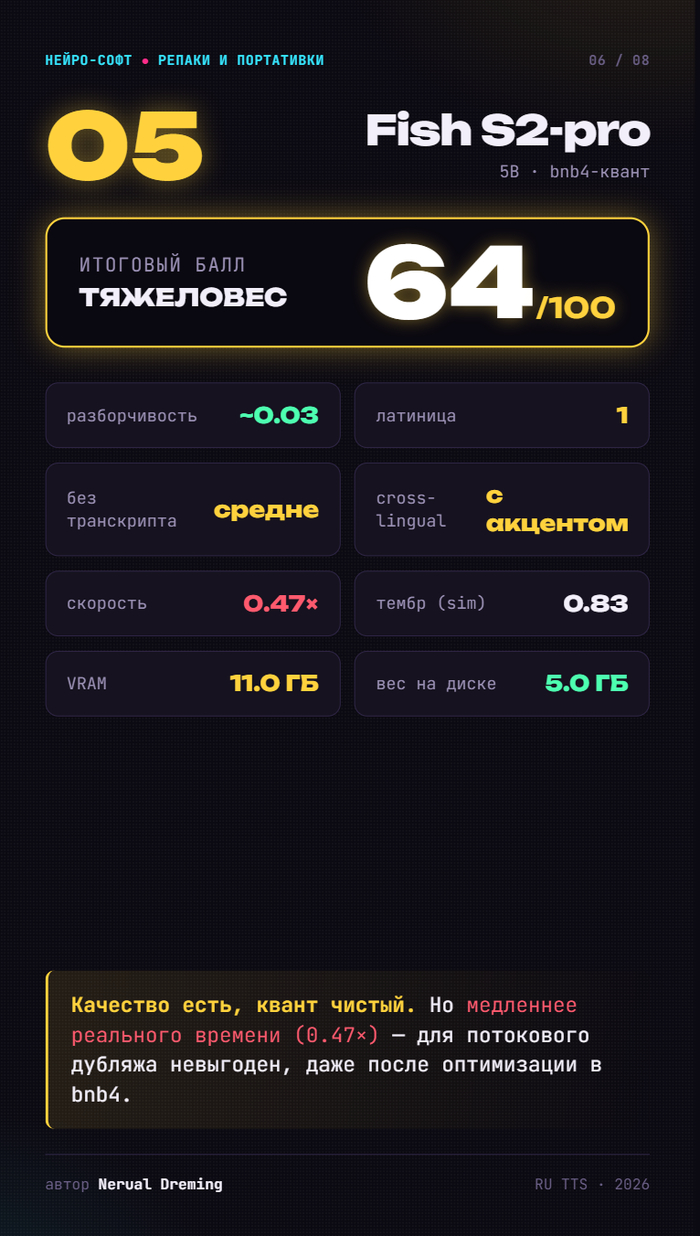
Fish S2-pro — 64. Качество есть, но медленнее реального времени даже после оптимизации. Для потока невыгоден.
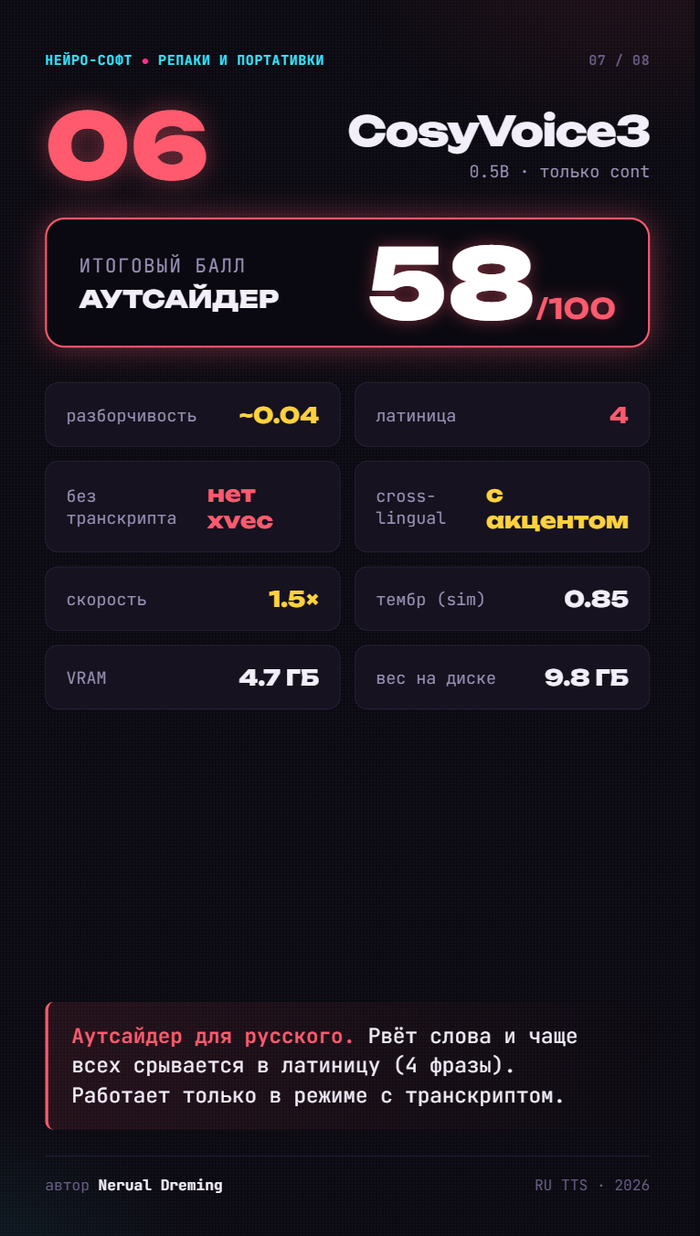
CosyVoice3 — 58. Аутсайдер для русского: рвёт слова и чаще всех срывается в латиницу.
Подводные камни (для технарей)
Fish в полной версии не влезал в 24 ГБ видеопамяти — распухал KV-кэш. Взял квантованную bnb4, сверил с полной по качеству (A/B) — квант оказался чистым.
CosyVoice пробовал ускорить через GGUF — и женский голос зациклился в 82 секунды мусора. Оказалось, баг самого тракта запуска (не доходит до токена остановки), а не квантизации.
Главная ловушка — распознавалка пишет англицизмы кириллицей. Чуть не записал кучу правильных озвучек в брак, пока не пересмотрел каждый транскрипт глазами.
Что дальше
Беру топ-3 (Qwen, VoxCPM, Higgs) и выжимаю максимум скорости: квантованные модели + эффективный инференс. Для Higgs ищу готовый квант, Qwen пробую на ONNX / TensorRT. Цель — продакшен-скорость без потери качества.
🎧 Хотите послушать все 627 семплов сами — собрал отдельный репорт с плеерами: t.me/nerualfiles/397
Это первая часть. В следующей — оптимизирую топ-3 под продакшен: квантованные модели, ONNX, TensorRT — и замерю реальный прирост скорости без потери качества. Будет интересно.
Друзья, не знаю чем объяснить мою страсть к TTS, но вот свежая модель, которая показывает реально интересные результаты.
Сделала её hilab — AI-лаборатория RedNote (это китайский Xiaohongshu, «китайский инстаграм» на 300+ млн человек). Та же команда уже выкатывала в опенсорс серию dots: языковую dots.llm1 и OCR-модель dots.ocr, а теперь добралась до синтеза речи — и сразу с заявкой на open-source SOTA. На бенчмарке Seed-TTS-Eval она забирает лучший средний результат, обходя CosyVoice3, Qwen3-TTS, Seed-TTS и F5-TTS:
Вся соль в архитектуре. Почти все современные TTS сначала сжимают звук в дискретные «кодек-токены» и учат языковую модель предсказывать именно их — на этом квантовании теряется часть деталей голоса. dots.tts выкинул этот этап целиком: дорожка остаётся полностью непрерывной. Текст без фонем уходит в LLM на базе Qwen2.5-1.5B, акустику дорисовывает flow-matching-голова (DiT) поверх непрерывных VAE-латентов 48 кГц, а CAM++-эмбеддинг говорящего держит тембр. Отсюда чистый, естественный голос и стабильная генерация. Вот так это устроено:
Коротко по делу:
🟣 2B параметров, текст превращается в речь напрямую, без фонем
🟣 Zero-shot клонирование голоса: 3 секунды референса + транскрипт, в том числе кросс-языковое
🟣 24 языка, передаёт эмоции и контекст фразы
🟣 Seed-TTS-Eval: лучший средний результат (WER 0.94/1.30 для китайского/английского, SIM до 81); SIM 83.9 на 24-язычном бенчмарке MiniMax
🟣 Три чекпоинта: base, soar (максимальное качество клона), mf (MeanFlow-дистилляция, всего 4 шага — самый быстрый)
🟣 Стриминг по чанкам, веб-демо на Gradio, лицензия Apache-2.0
Соберёте 300 плюсиков на этом посте — соберу для неё портативку в один клик.
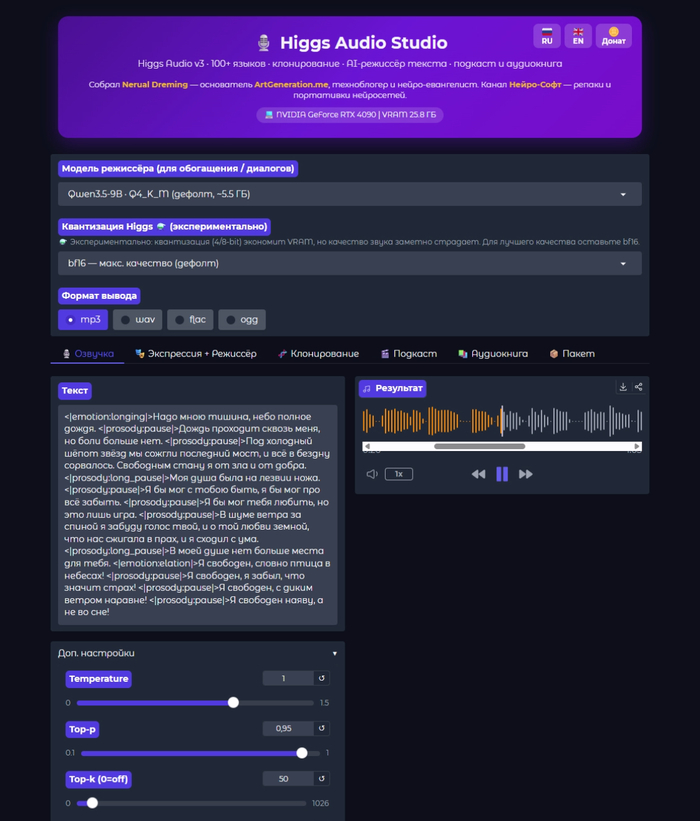
Озвучка текста нейросетью — давно не новость. Но почти всё хорошее живёт в облаке: платишь за символы, отдаёшь свой текст чужому серверу и упираешься в лимиты. Higgs Audio Studio разворачивает эту историю на 180°. Это портативная обёртка вокруг свежей модели Higgs Audio v3 TTS (4B) от Boson AI, которая целиком крутится на твоей видеокарте. 100% оффлайн, без подписок и без отправки данных наружу — скачал папку, запустил, говоришь.
В чём прорыв v3. Это не «читалка вслух», а модель, обученная говорить — сама расставляет интонацию, паузы и эмоции по смыслу фразы. И скачок поколения тут реально огромный: на мультиязычном тесте Higgs-Multilingual средняя ошибка распознавания (WER) упала с 52,2 у прошлой версии до 3,6 у v3, на MiniMax-Multilingual — с 49,9 до 2,7. На классическом SeedTTS — 1,11, лучший результат среди 11 моделей в таблице (Fish Audio S2 Pro, Qwen3-TTS, VibeVoice-7B, IndexTTS-2 и др.). И всё это при весе всего ~4 млрд параметров.
Главное — выразительность. В слепом тесте Emergent TTS, где судья сравнивает живость речи, v3 берёт лучший общий результат и первое место в самых сложных категориях: паралингвистика (68,6% побед), вопросительная интонация (61,4%), сложный синтаксис (60,7%). Там, где другие модели «бубнят», эта играет голосом. Она умеет шептать, кричать и даже петь, а в текст можно вставлять 43 управляющих тега: 22 эмоции, стили и 9 звуков — смех, вздох, кашель, чихание и прочее (<|emotion:amusement|>, <|sfx:laughter|>, <|prosody:pause|>).
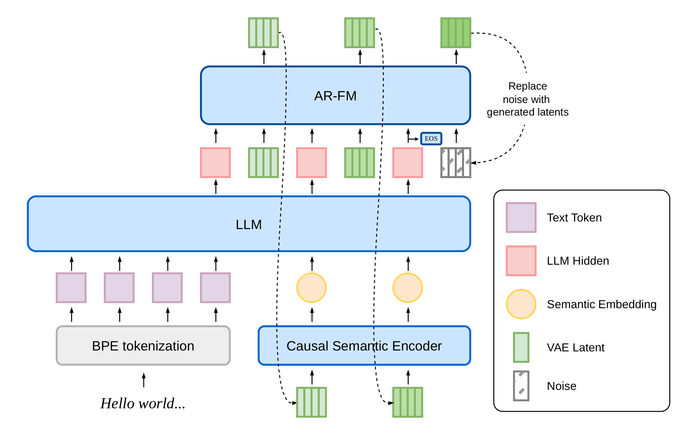
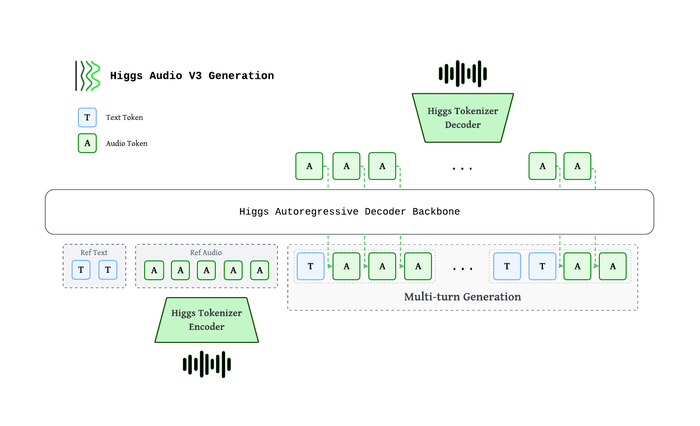
Как это устроено (на схеме в начале поста). Авторегрессионный декодер жуёт вперемешку текстовые и аудио-токены. Звук кодируется собственным Higgs Tokenizer в 8 кодбуков на 25 кадрах/сек, проходит через общий «костяк» модели и де-кодируется обратно в волну 24 кГц. Отсюда живая, многоходовая речь — модель держит контекст диалога, а не озвучивает фразы в вакууме. На серьёзном железе это ещё и быстрее реалтайма (около 7 секунд звука за секунду счёта), но и на домашней видеокарте работает бодро.
AI-режиссёр. Локальная LLM (Qwen3.5-9B / Gemma-3-12B) сама нормализует числа и даты, расставляет эмоции и разбивает длинный текст по ролям — одной кнопкой, без ручной разметки. На видео ниже режиссёр сам превратил кусок прозы в размеченный по спикерам сценарий.
Клонирование голоса. Zero-shot по одному референсу + авто-транскрипт (Moonshine ASR) — модель снимает тембр с короткого образца и говорит им. Подачу можно докручивать тегами эмоций и просодии, есть библиотека пресетов и докачка 743 русских голосов.
Подкаст и аудиокнига. В режиме подкаста достаточно задать тему — сценарий диалога модель пишет сама, раздаёт реплики нескольким дикторам (каждому свой голос) и выравнивает громкость спикеров (LUFS −16, как в индустрии). Режим аудиокниги — рассказчик плюс персонажи с постоянными голосами, длинная форма с переносом тембра. На видео — генерация подкаста на трёх спикеров из одной строки темы.
Что ещё умеет: форматы MP3 / WAV / FLAC / OGG, пакетная озвучка списком с лайв-логом, кнопка «Стоп» на лету, квантизация (bf16 / 8 / 4-бит) + torch.compile ≈2× ускорение, интерфейс RU / EN, тёмная тема. Всё внутри папки — удалил папку = удалил приложение.
Что нужно: NVIDIA GPU от 8 ГБ VRAM (для nf4; 16+ ГБ рекомендуется), 16+ ГБ RAM, ~15 ГБ на диске. Windows, а через Pinokio — ещё Linux и macOS. Установка на выбор: в 1 клик через Pinokio (сам поставит CUDA, Python, PyTorch), zip-установщик под Windows (install.bat → run.bat), готовое окружение (распаковал → run.bat) или git clone.
⚠️ Модель отдана под research/non-commercial лицензию: для себя и экспериментов — пожалуйста, а вот коммерция и клонирование чужого голоса без согласия запрещены.
Применяемый авторегрессионный декодер (примерно 4B) обрабатывает текст и аудиотокены. Аудио кодируется в 8 словарей векторов (25 fps, паттерн задержки), выполняется многослойный эмбеддинг, затем информация объединяется в единый поток, снимается задержка и осуществляется декодирование в 24 кГц.
Поддерживается выразительная речь на более 100 языках, zero‑shot клонирование голоса, внутритекстовое управление эмоциями, стилем, интонационной окраской, паузами и звуковыми эффектами через теги в тексте. Среди 102 языков 85 имеют WER/CER меньше 5 (продакшн-качество) и 17 с WER/CER от 5 до 10, что приемлемо.
Управляющие токены <|категория:значение|> позволяют настраивать 21 вид эмоций от радости до беспомощности, стили, как пение, крик или шёпот, а вдобавок звуковые эффекты (кашель, смех и другие), каждый из которых требует немедленного звукоподражания (например, <|sfx:laughter|>Haha). Плюс ко всему, они дают возможность регулировать интонацию скорости речи (от очень медленной до очень быстрой), длину пауз (обычная либо длинная), высоту тона (низкая или высокая) и экспрессивность (высокая или низкая).
Базовая лицензия разрешает только исследования и некоммерческое использование. Для коммерции, хостинга API и получения дохода требуется отдельная лицензия. Также запрещено клонирование без согласия, имперсонация, мошенничество, вмешательство в выборы, биометрическое наблюдение и незаконное применение.
В результате лучшее общее качество в однозначных WER/CER на SeedTTS, CV3, MiniMax‑Multilingual и внутреннем 111‑языковом Higgs‑Multilingual, а Emergent TTS имеет общий процент побед 53,65%, лидерство в паралингвистике, вопросах и синтаксической сложности, демонстрируя эмоции на уровне конкурентов.
Запущена новая сверхлегкая система синтеза речи Supertonic 3 (https://huggingface.co/Supertone/supertonic-3) для полностью локального исполнения на устройстве (ONNX Runtime, без облака) с лицензией OpenRAIL-M и кодом под лицензией MIT.
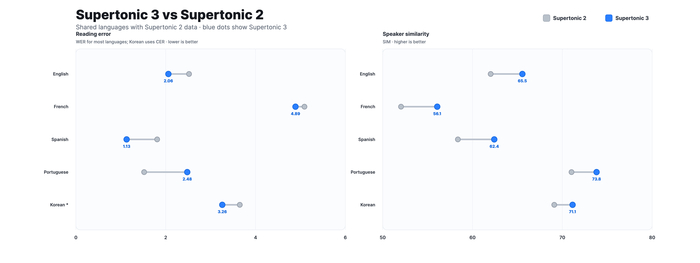
В ней расширили поддержку с 5 до 31 языка (русский, английский, немецкий, французский, испанский, корейский, японский, арабский и другие), уменьшили повторы/пропуски при чтении, повысили схожесть голоса с диктором и добавили поддержку тегов выражения (<laugh>, <breath>, <sigh>). Вдобавок размер модели всего приблизительно 99M параметров, что кратно меньше аналогов (VoxCPM2, Qwen3-TTS и других).
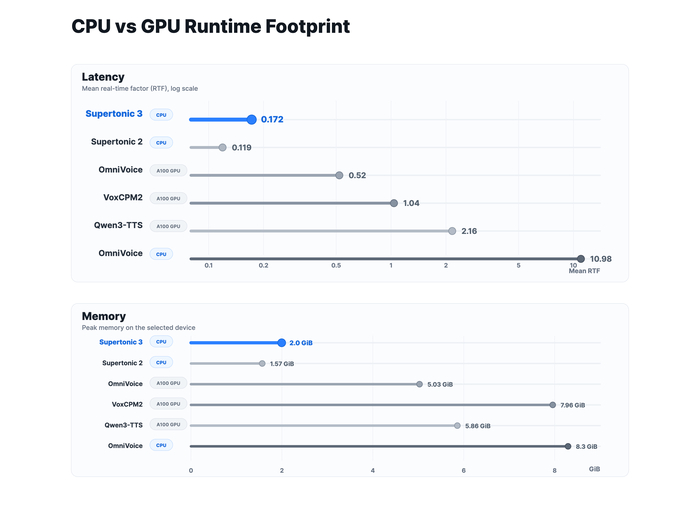
В результате при использовании CPU средняя задержка RTF примерно 0.17, а пиковая потребляемая память около 2 ГБ. При этом точность чтения (WER/CER) на уровне крупных GPU-моделей.