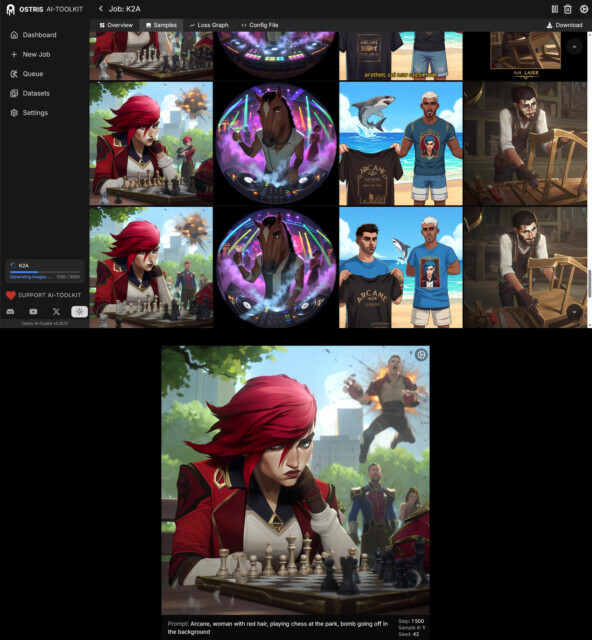
🔌 Совместимость с RTX 3090 / 4090 — изоляция процессов llama.cpp и PyTorch через фоновый демон-процесс (director_daemon.py); устраняет конфликты CUDA-контекстов и падения инференса; выгрузка моделей «на лету» для освобождения VRAM.
🧬 Длинный клон — озвучка сверхдлинных текстов и книг с автоматической разбивкой на фрагменты, пофрагментным авто-обогащением, синтезом частями и бесшовной склейкой с настраиваемой паузой.
🌐 Внешние LLM — глобальная интеграция с LM Studio / Ollama / OpenAI API (External API); перенаправление автоулучшения со всех вкладок на внешнюю модель; настраиваемый системный промпт режиссёра.
🧪 Тест подключения — кнопка быстрой проверки связи с внешним API и интерактивный редактор промптов с выводом подробных кодов ошибок в интерфейс.
💾 Автосохранение настроек GUI — сохранение и автоматическое восстановление всех параметров (моделей, голосов, слайдеров температуры/top-p) между запусками в локальном файле gui_config.json.
💻 Только CPU — переключатель в интерфейсе для полной обработки TTS и LLM на центральном процессоре (без использования видеокарты), что полностью освобождает VRAM.
🌑 Всегда темная тема — принудительное включение темной темы при первой загрузке без светлого мигания.
Только на CPU - работает, но ооооочень не быстро. Учитывая тест на 5950x :)
Voicebox — это локальная голосовая студия с открытым исходным кодом, которая в одиночку закрывает то, за что обычно платят сразу двум облачным сервисам. ElevenLabs отвечает за вывод — синтез и клонирование голоса. WisprFlow — за ввод, голосовую диктовку. Voicebox делает обе половины этого цикла и, в отличие от обоих, крутит всё прямо на вашей машине: без аккаунтов, без API-ключей и без единого байта, уходящего в облако.
Автор проекта — Джейми Пайн, тот самый разработчик кросс-платформенного файлового менеджера Spacedrive. Voicebox выложен под лицензией MIT и за считанные недели собрал почти 35 тысяч звёзд на GitHub, влетев в недельный тренд.
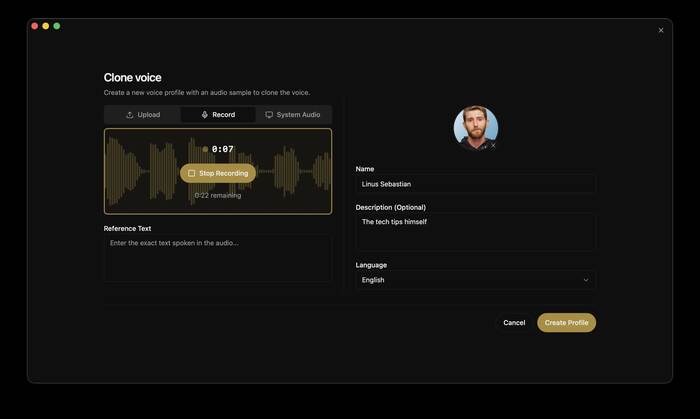
Клонирование голоса. Достаточно пары секунд аудио-референса — загрузите файл, запишите с микрофона или захватите системный звук, и приложение создаёт голосовой профиль (на скриншоте выше — как раз это окно). Не хочется возиться — в комплекте 50+ готовых пресет-голосов.
Семь TTS-движков под капотом. Qwen3-TTS, Qwen CustomVoice, LuxTTS, Chatterbox Multilingual, Chatterbox Turbo, HumeAI TADA и Kokoro — каждый со своими сильными сторонами, переключаются на лету. В сумме 23 языка: от английского до арабского, японского, хинди и суахили. Chatterbox Turbo понимает паралингвистические теги вроде [laugh], [sigh], [gasp] — эмоции и звуки прямо в тексте.
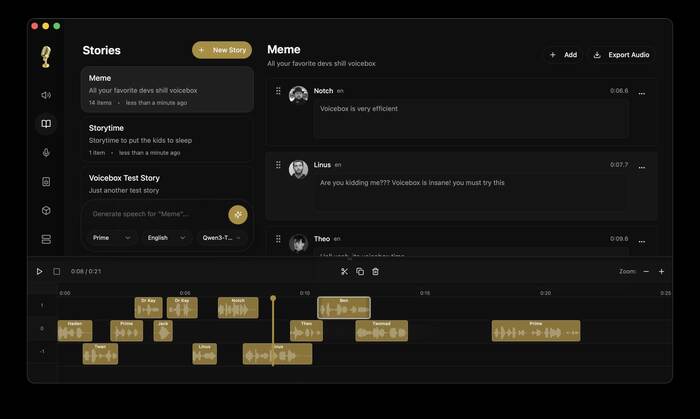
Многодорожечный редактор «историй». Отдельный режим для подкастов, диалогов и аудиокниг: дорожки с разными голосами, перетаскивание, обрезка и склейка клипов прямо на таймлайне (на скриншоте выше).
Голосовой ввод. Глобальный хоткей в любом приложении: зажал, проговорил, отпустил — на macOS текст сам вставляется в активное поле. Транскрипция на Whisper (включая Turbo, примерно в 8 раз быстрее Large). Опционально локальная LLM подчищает «эээ», запинки и оговорки перед вставкой.
Голос для ИИ-агентов. Через встроенный MCP-сервер любой агент — Claude Code, Cursor, Windsurf, Cline — может заговорить с вами голосом, который вы сами склонировали. Один вызов voicebox.speak, и «деплой завершён» вам произносит выбранный голос. Удобно в длинных агентских циклах, когда не хочется пялиться в терминал.
Сверху ещё постобработка звука (8 эффектов на движке pedalboard от Spotify) и генерация без ограничения длины с авто-нарезкой и кроссфейдом. Приложение нативное — собрано на Tauri (Rust), а не Electron, и работает на Windows (CUDA/DirectML), macOS (MLX/Metal) и Linux (включая AMD ROCm и Intel Arc).
Raw — базовый чекпоинт для тренировки лор и файнтюна. Непригоден для инференса.
Turbo — чекпоинт для генерации картинок. Можно использовать со своими лорами, натренированными на Raw.
Есть только text-2-image режим. Редактирования текстом, подключения рефов, Image-2-image — этого нет.
При создании датасета разработчики полностью исключили сгенерированные картинки из этапа претрейна, используя свои фильтры для очистки данных от «цифрового пластика». Благодаря этому модель выдает более живые, разнообразные и арт-ориентированные стили.
Krea 2 выдаёт изображения с высокой детализацией, хорошей анатомией, чёткими надписями, без блюра, сетки, и без шумов как Z-image Turbo при тех же 8 шагах. Модель напоминает по скорости и качеству опенсорсный Ernie-Image от Baidu, но Krea 2 не ловит таких артефактов как она.
Вместе с моделью идёт улучшайзер промта, как опять же в Ernie, но он может как сделать картинку детальнее, так и увести её в совсем другое русло. Лучше начальный промт иметь поконкретнее.
Следование самому промту в Krea 2 хорошее: сцена, персонажи и объекты будут располагаться как указано. Причём, так как текстовый энкодер Qwen3VL понимает русский, можно промтить прямо на русском. Но на любом языке ощущается малая вариативность по одному и тому же промту с разными сидами. Так что играться с промтами придётся.
Turbo модель заточена генерить в разрешениях от 1 МП (1024х1024) до 4 МП (2048х2048), хотя можно выставить и 16 МП (4096х4096), но тогда появляются проблемы с анатомией и часто объекты/персонажи начинают двоиться в кадре. В 2048х2048 картинка ощутимо чётче и детальнее, чем в 1024х1024. Можно даже сказать 2048х2048 стоит использовать как дефолтное разрешение. В воркфлоу из шаблонов Comfy размер картинки задаётся в МП (мегапикселях) в ноде Resolution Selector. Если что, её можно отстегнуть и задавать разрешение вручную.
Тесты а 4090 и 128 ГБ RAM:
При использовании Krea 2 Turbo bf16 и текстового энкодера Qwen3VL 4B bf16 в видеокарту загружается до ~23 ГБ VRAM, а в оперативку до ~10 ГБ. На генерацию 1024x1024, 8 шагов, cfg 1 = уходит 5 сек. Генка в 2048х2048 уже занимает 23 сек.
Использование fp8 весов модели и энкодера снизит общее потребление до 18-20 ГБ VRAM. Генерация 1024x1024, 8 шагов, cfg 1 = займёт 4 сек, а 2048х2048 уже 21 сек. Качество при этом останется хорошим, но могут появиться лишние конечности, а изображение потеряет немного в чёткости и станет шумным в мехе и подобных мелких вещах.
Тренировка лор уже завезена в AI-Toolkit, а также в Musubi. Я опробовал треню в AI-Toolkit и модель очень быстро подхватывает нужный стиль. На моём железе квантованная версия тренируется на скорости ~6 сек/шаг, а неквантованная уже +6 мин/шаг.
Krea и сами выпустили подборку лор, которые можно использовать в воркфлоу Comfy из шаблонов. У кого-то даже получается на Krea 2 натренировать лору на стиль, который раньше не давался.
Разрабы выпустили технический отчёт с деталями по тренировке модели. Ждём теперь от рисовой братвы новых качественных генераторов картинок и финтов с Krea 2, которым её не учили. Кто-то уже NSFW прикрутил.
С хаггинга то и дело качаешь сотни гигов, и у них то скорость скачивания падает, то оно обрывается и надо качать заново. А если бы они бы генерили магнетлинки, то через qBittorent и иже с ними всё качалось бы без проблем, да и нагрузка на их сервера была бы меньше.
Dub Studio - локальная утилита для перевода коротких роликов. Та самая утка тоже тут.
Всем привет! Листал ленту тиктока и попался американский ролик про СДВГ, где всё объясняют на утках. Понравилось. И я подумал: классно было бы сделать такой же канал, только на русском.
Но я ленивый. Снимать, писать сценарии, делать всё с нуля - это скучно. А вот взять готовый ролик и перевести-переозвучить его на русский - вот это уже интересно, подумал я, а потом задумался, о том, как это автоматизировать. Это оказалось интересной инженерной задачей, которая увлекла меня на неделю времени, и привела к созданию ИИ утилиты с открытым исходным кодом. А тикток с утками я так и не создал...
Меня зовут Илья, я блогер, основатель сервиса для генерации ArtGeneration.me и просто фанат нейросетей. Я не разработчик в классическом смысле - скорее продакт с двадцатилетним стажем, который вайбкодит с нейросетями всё, что давно хотелось воплотить в жизнь.
Портативок я насобирал уже кучу, потому что для меня это самый быстрый способ протестировать технологию. Отдельно под озвучку, отдельно под распознавание речи. Но чтобы собрать всё это в один инструмент, где работает сразу из коробки - такого ещё не было. Заодно захотелось наконец слезть с Gradio, на котором я обычно делаю свои портативки.
Так появился Dub Studio - утилита, которая локально переводит и переозвучивает короткие ролики. Офлайн, бесплатно, без подписок и без цензуры. А та самая утка стала главным тестовым роликом проекта.
Дальше расскажу, как всё это собиралось и покажу примеры сделанные в этой же утилите.
❯ Почему шесть нейросетей, а не одна
Сначала я хотел обойтись одной моделью. Омнимодальной. Чтобы один мозг сразу и слушал звук, и смотрел картинку, и читал-переводил надписи на экране. Один файл, один прогон, никакой возни со склейкой.
Но была рамка. Дома у меня RTX 4090 на 24 гига, в неё влезает многое. А вот у большинства моих подписчиков 12 гигов и меньше. Пихать в инструмент жирные модели, которые у них просто не запустятся, мне не хотелось. Так что планку я поставил сразу под аудиторию: всё должно жить в 12 гигах VRAM. Иначе смысла нет.
Поресёрчил омни-модели. Вывод вышел неприятный: ни одна модель, которая влезает в 12 гигов, не умеет нормально размечать речь по времени и по говорящим за один проход. Это не я поленился покопаться, это просто потолок таких моделей, даже лучших. Кто где говорит и в какую секунду - они на этом плывут.
Реальный кандидат был один, MiniCPM-o, он по размеру проходил. Но до его тестов я даже не дошёл. Ещё на ресёрче стало понятно, что омни в принципе не вывозит аудио-тайминг, и запускать её смысла уже не было.
Не так изящно как мне бы хотелось, но и не 14 узлов как в начале
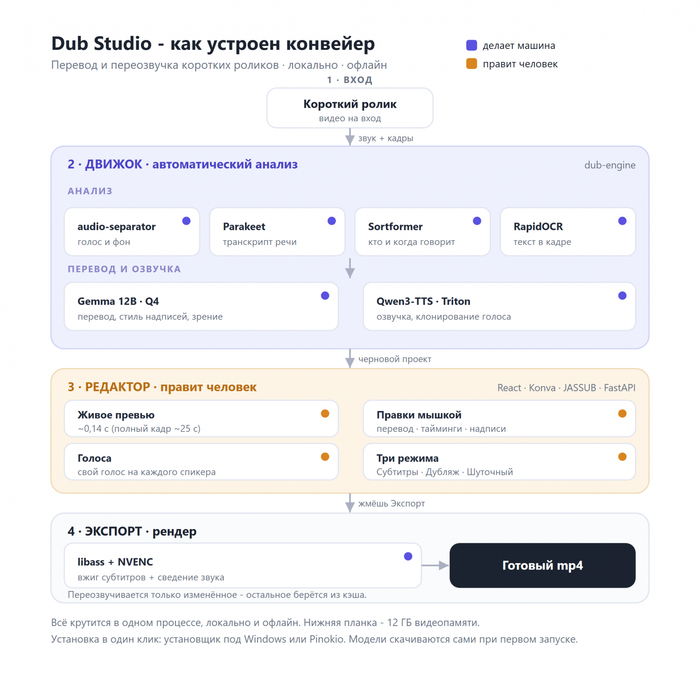
Поэтому в итоге не одна модель, а гибрид из шести специализированных. Каждая делает свой кусок и делает его хорошо:
экранный текст вытаскивает RapidOCR, а вжигает субтитры libass.
Да, шесть штук вместо одной звучит как перебор. Но каждая тут весит немного, все вместе укладываются в бюджет по памяти, и на своём участке работают лучше, чем одна большая модель на всём сразу.
❯ TTS: лучший из худших
Озвучка - это сердце дубляжа. Поэтому к выбору движка я подошёл серьёзнее всего.
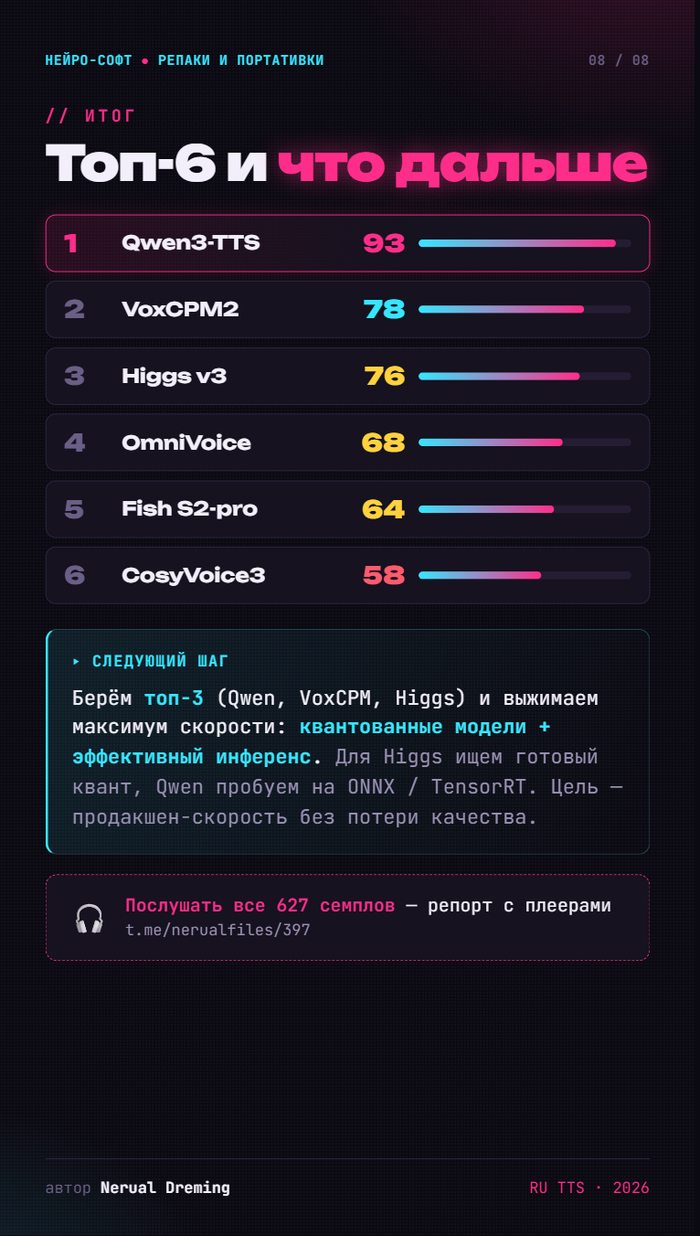
TTS, который мне нужен, должен уметь клонировать голос. Не просто прочитать текст роботом, а звучать похоже на оригинал, в моём случае ещё и по-русски. Таких движков несколько, и я прогнал большое исследование: погонял кандидатов по метрикам.
Вывод вышел невесёлый. Идеального движка нет. Вообще. У каждого свой набор косяков.
Победил Qwen3-TTS, в сборке на Triton. Победил не потому, что не косячит. Косячит. Хуже всего у него с ударениями: периодически ставит их не туда, и тогда слово звучит не по-русски. Но из всех вариантов это самый адекватный компромисс. Он быстрый, лёгкий и работает быстрее реалтайма. Лучший из худших, если совсем честно.
И вот тут я хочу сказать вещь, которая тянется через весь проект. Он целиком собран на компромиссах. Gemma у меня квантованная, не полная. Сам процесс полу-автоматический, а не нажал кнопку и пошёл пить кофе. Везде, где можно было выбрать между идеально и просто работает, я выбирал второе. Иначе инструмента просто не было бы.
Выбор TTS, да, спорный. Я знаю, что многие со мной не согласятся. И это не просто так. Но про это позже.
❯ Прощай, Gradio
Сначала я хотел сделать совсем просто. Лёгкий CLI, полностью автоматический. Кидаешь ролик, получаешь готовый дубляж. Без рук, без редактора, без меня.
Не вышло. У каждого ролика своя верстка: надписи лезут не туда, разметка везде разная. Модели ошибаются. Универсального кинул и готово не существует. Чем дольше я это ковырял, тем понятнее становилось, что полностью без человека тут не выехать.
Так я пришёл к полу-автоматике. Движок берёт на себя тяжёлую часть: анализирует ролик, раскладывает умные дефолты. А человек правит остальное. Но правит не вслепую, а с живым превью, где сразу видно что получится.
Это Спарта? Нет, это ГРАДИО!
Тут стоит пояснить, что вообще такое Gradio - вдруг кто не сталкивался. Это питоновская библиотека для быстрых интерфейсов к нейросетям: парой строк кода оборачиваешь модель в простенькую веб-морду - поле ввода, кнопка, окошко с результатом, и всё, модель можно тыкать в браузере, а не гонять из консоли. Бутстрап для нейронок.
Принадлежит он Hugging Face - по сути это гитхаб для нейросетей, главный репозиторий ИИ-моделей. Поэтому с моделями оттуда Gradio дружит бесшовно: взял с хаба, обернул, выложил - всё заводится из коробки. Идеальная штука, чтобы по-быстрому собрать MVP, на нём собраны почти все мои портативки.
И вот тут стало ясно, что Gradio мне больше не помощник. Для демки он отличный. Но нормальный редактор на нём не собрать. Gradio - это один столбик, пара полей и готовых элементов и кнопка. А мне нужен холст, превью, субтитры поверх видео, перетаскивание.
Поэтому я взял нормальный фронт. React + Konva для холста, на нём всё рисуется и двигается. Субтитры кладутся сверху через JASSUB, прямо поверх видео. Бэкенд на FastAPI. А голый CLI к тому же грузил весь стек заново на каждый ролик, что радости тоже не добавляло.
❯ Редактор
Теперь как это работает в деле. Кидаешь ролик, движок прогоняет анализ и раскладывает умные дефолты: транскрипт, кто где говорит, какие надписи нашёл в кадре, готовый план субтитров. Дальше начинается пользовательская часть.
На Gradio, конечно, так не сделаешь
Дольше всего я бился над превью. Оно и сейчас по сути покадровое слайд шоу с аудио дорожкой, это так и задумано. Но поначалу оно тормозило так, что работать было невозможно. Полный рендер одного кадра шел около 25 секунд. Двадцать пять. Сидеть и ждать столько после каждого чиха в редакторе невозможно. Пришлось делать отдельный быстрый предпросмотр, тоже один кадр, но уже около 0.14 секунды. Вот после этого редактор и ожил.
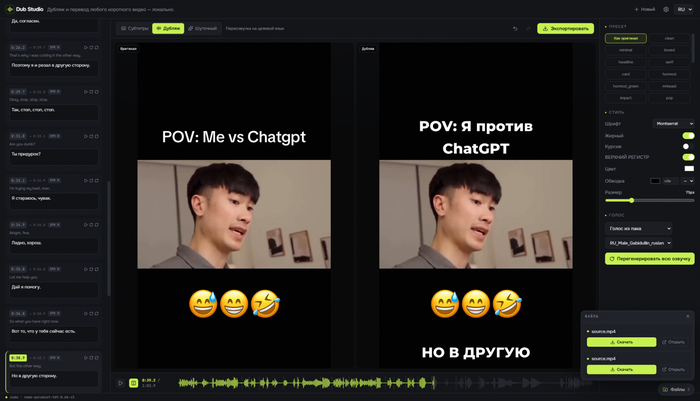
Каждый ролик можно гонять в одном из трёх режимов: Субтитры, Дубляж или Шуточный. Первые два понятны. С Шуточным интереснее: говоришь Gemma тему, она переписывает скрипт под неё, и кусок переозвучивается заново уже с новым текстом, мем сделанный в этом режиме ждет вас в конце статьи.
Голоса вешаются на каждого говорящего по отдельности. Один спикер - один голос из пака, другой - другой. Голосов в паке много и никто не мешает добавлять еще просто закидывая файлы в папку.
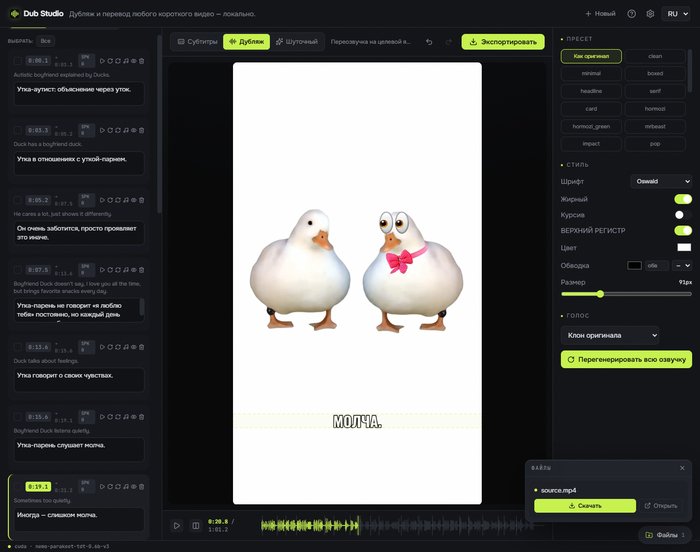
С субтитрами тоже всё руками. Не нравится, где стоит полоса - берёшь её мышкой и таскаешь прямо по кадру, куда надо.
Теперь переведённые надписи в самом видео. Хочется, чтобы они смотрелись как родные. Поэтому оригинал я не блюрю. Блюр мылит картинку и сразу выдаёт, что тут что-то подменили. Вместо этого оригинальная надпись кроется непрозрачной плашкой под цвет сцены. Где её положить, подсказывает OCR, а как оформить текст поверх, подсматривает зрение Gemma. Получается аккуратно.
И ещё про громкость. Реплики приходят разные по уровню. Поэтому все фразы приводятся к одному уровню.
❯ Честно про вайбкодинг
Раз уж пошёл такой разговор, расскажу честно про обратную сторону.
Этот проект тоже собран в паре с ИИ-агентом. Штука мощная, но есть одна боль, которая выматывала сильнее всего. Агент уверенно пишет тебе "готово, баг исправлен". А на деле ничего не исправлено. И ловишь ты это только сам, глазами.
Простой пример. Поправили субтитр в превью, всё хорошо. Запускаешь экспорт - а там та же самая ошибка на месте. Агент починил один путь и честно отчитался за оба.
Но больнее всего была не сама модельная часть. Больнее всего оказалась упаковка в один клик, через Pinokio. Агент взял обязательную зависимость и пометил её как необязательную. Вроде мелочь. А без неё весь дубляж просто падал. И отдельная радость - полдня ушло на одну ошибку с ffmpeg. Просто полдня на одну ошибку, подробности опущу.
Вывод для меня простой. Верить агенту на слово нельзя. Совсем. Поэтому всё, что он делает, проверяешь сам. Каждый раз.
❯ Стек и как это работает
Если убрать всю кухню, алгоритм простой.
Кидаешь видео в окно. Дальше движок сам прогоняет весь конвейер: снимает транскрипт, режет на сегменты по спикерам, вытаскивает надписи с экрана, собирает план субтитров с разумными дефолтами. На выходе готовый проект, который можно открыть и крутить.
Дальше правишь руками. Меняешь перевод, двигаешь тайминги, перебираешь надписи - и всё это с живым превью, видно сразу. Когда всё нравится, жмёшь экспорт. Тут важный момент: переозвучивается только то, что ты трогал. Остальное берётся из кэша, заново гонять весь ролик не нужно. На выходе готовый mp4.
❯ Это бета, и ей нужны вы
Я доволен тем, что получилось. Сам этим пользуюсь, и это уже не игрушка. Но давайте честно: это бета. Работы ещё хватает.
Поэтому про ограничения прямо. Заточено всё в основном под короткие ролики. Выбор TTS спорный, и я это прекрасно понимаю - многие со мной не согласятся по поводу того, какой голос лучше. Языков можно тащить больше, чем сейчас доступно. Технически и ттс и ллм их поддерживает больше, но каждый язык надо тестить руками, а это время.
В планах сделать все модули сменными. Раз уж столько споров вокруг TTS, логичный ход - дать каждому собрать пайплайн под себя. Не нравится распознавалка - воткни свою. Не нравится речь - поставь другой. Хочется, чтобы это был конструктор, а не приговор.
Кстати, стек так удачно лёг, что я потащил его и в другие свои проекты, например в днд игру где нейросеть выступает гейм-мастером. Но это уже отдельная история, под новую статью, так что как-нибудь в другой раз.
Теперь самое важное. Репозиторий открыт, лицензия MIT, код тут - берите и делайте. Форкайте, шлите PR и заводите issue. Если что-то сломалось или работает не так - расскажите. А ещё лучше - прогоните свой ролик и киньте результат в комменты, очень интересно посмотреть, что у вас выйдет. И если проект вам зашёл, поставьте звезду на гитхабе, мне будет приятно, а ему полезно.
Найти меня можно в YouTube, в Телеграме и на Бусти. Залетайте, там тоже интересно, каждую пятницу смотрим новинки нейросетей и генерируем вместе. Всех обнял и удачных дубляжей.
Привет! Хочу поделиться своим проектом, который решил возродить пару недель назад — мессенджер на Python. Не сомневаюсь, что такие штуки уже есть на просторах интернета и могут быть лучше того, что делаю я, но меня это не интересует. Мне нравится делать что-то самому, разбираться и по возможности «не зависеть» от чего-то.
Что это вообще такое
Это чат с клиентской и серверной частью, который работает через сокеты. На данный момент всё происходит в консоли, но в планах GUI на PyQt5. Сервер поднимается локально, клиенты подключаются к нему и начинают взаимодействовать с помощью различных команд. Клиент должен иметь аккаунт на сервере для ряда функций, поэтому первым делом он регистрируется либо входит в аккаунт. Показываю команды пользователя ниже.
Команды пользователя
🔐 Авторизация и регистрация
/reg <юзернейм> <пароль> <пароль> — зарегистрироваться на сервере
/auth <юзернейм> <пароль> — аутентифицироваться на сервере
👤 Профиль и общение
/set_nick <никнейм> — установить отображаемый никнейм
/msg <никнейм> <сообщение> — отправить личное сообщение
/offline_sms — получить сообщения, пришедшие в ваше отсутствие
/get_users — посмотреть список пользователей
📂 Файлы
/all_files [количество] — показать последние файлы (все, если число не указано)
/send_file <никнейм> <имя_файла> [текст] — отправить файл из папки data/files
Если честно, всё было в меру сложно. Конечно, чем больше папок и файлов, тем больше нужно помнить в голове и сложнее организовывать что-либо. Но всё же трудненько было сделать систему для обмена файлами, потому что пришлось параллельно думать об очереди сообщений, и в моменте я вообще ничё не понимал. Я ожидал, что придётся дебажить, но на удивление пришлось этим заниматься не очень-то и долго — всего день.
Про технологии и логику
Хочу также затронуть некоторые технологии, которые я применял. Одна из них — хэширование (hashlib + secrets). Я применял его для регистрации и аутентификации пользователей, чтобы по сети не гуляли пароли. Однако всё равно можно перехватить запрос на авторизацию:
request = self.encode({
'type': 'auth',
'username': parts[0],
'hash': hash_b64
})
И по сути войти в чужой аккаунт, скопировав этот запрос и отправив на сервер от себя. Типа да, пароль никто не узнает, но хэш-то стырить можно. В общем, не всё идеально.
Ещё я использую потоки (threading) для параллельных задач. Например, приём и отправка запросов идут в разных потоках на клиенте. А на сервере вообще под каждого клиента свой поток запускается.
Также недавно узнал про классную штуку в Python — декораторы. Очень хорошо очищают код и местами упрощают логику. Ещё датаклассы — аналогично упрощают жизнь, особенно при перекрёстных передачах параметров в экземпляры классов, коих у меня немало.
Планы на будущее
Как уже говорил, буду делать GUI, ещё хочу уведомления о сообщениях, локальную историю переписок и шифрование. Шифрование буду делать симметричное — самый незапарный вариант, для чата с друзьями за глаза.
Кстати, я не просто так это всё делаю: хочу в будущем купить Raspberry Pi и поднять свой сервер для этого мессенджера. Ну и по мелочи: группы (может и не добавлю, так как на 10 человек незачем), мобильная версия, если прям будет желание, ну и оптимизация, безопасность и так далее.
GitHub и Telegram
Кто хочет посмотреть — велкам, можно даже пулл-реквесты делать)
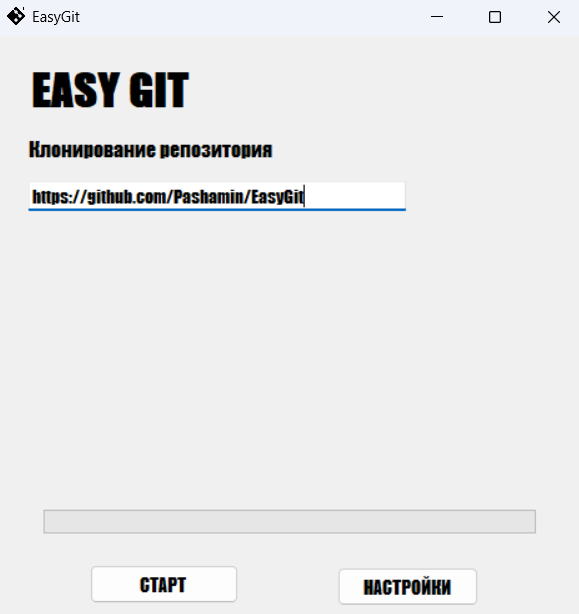
Решил поделиться своим небольшим опенсорс-проектом на C# (Windows Forms). Программа называется EasyGit, и создал я её чисто для себя и друзей, чтобы решать одну простую задачу — быстро клонировать Git-репозитории в пару кликов, не открывая терминал и не запуская тяжелые официальные клиенты.
Логика под капотом работает на библиотеке LibGit2Sharp.
Кому это может пригодиться?
Начинающим разработчикам, которые ещё путаются в командах терминала.
Тем, кому нужно просто быстро стянуть проект с гитхаба в нужную папку и сразу начать работать, не вспоминая синтаксис git clone.
Что внутри?
Интерфейс максимально простой (никакого перегруженного мусора): вставил ссылку на репозиторий, выбрал папку на компе, нажал кнопку — и всё готово. Проект полностью открытый, исходники весят копейки, а весь лишний компиляционный мусор я уже отсек, так что репозиторий теперь чистый как слеза.
1/3
Скриншоты из программы
Сейчас как раз выкатил свежее обновление, поправил пару багов и доработал встроенный апдейтер, так что утилита теперь сама умеет проверять свежие релизы на GitHub.
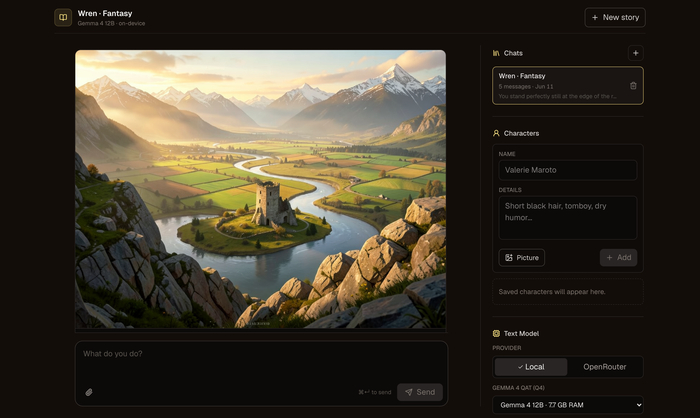
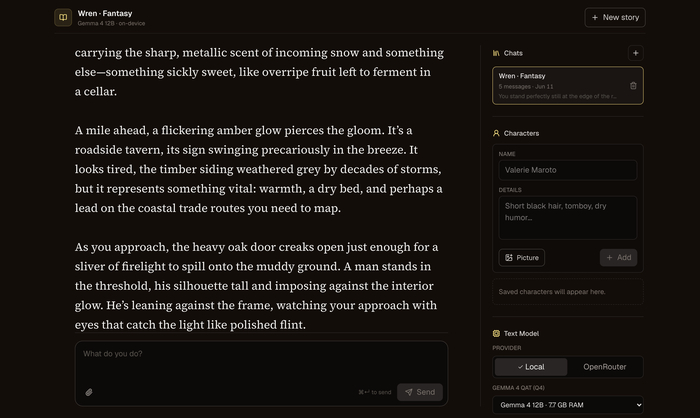
Open Dungeon — первый по-настоящему полностью локальный AI-ролеплей. ИИ-рассказчик ведёт историю в реальном времени, а сцены тут же иллюстрируются картинками — и всё это считается на твоей машине. Ни аккаунтов, ни API-ключей, ни облака: истории, персонажи и картинки лежат в локальной SQLite и никуда не утекают.
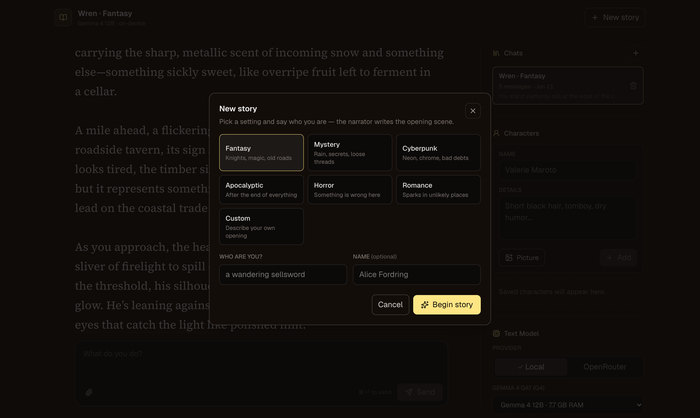
Текст генерит Gemma 4 (QAT) через Ollama — хватит и 4 ГБ ОЗУ под младшую модель, а 12B-вариант кушает около 8 ГБ. Картинки сцен рисует FLUX.2 (опционально, на CUDA / CPU / Apple Silicon). Старт в один клик: выбираешь сеттинг (фэнтези, киберпанк, хоррор, апокалипсис…), говоришь, кто ты, — и рассказчик пишет завязку.
Из приятного: режимы ввода Do / Say / Story, правка любого абзаца, память на 128–256K токенов со сворачиванием старого в «summary истории», персонажи с визуальной преемственностью и возможность играть с телефона по Tailscale. Лицензия MIT, есть лаунчеры под Windows (.bat), DMG под macOS и установка под Linux.
Любопытно ещё и лично: я сам когда-то ваял подобное — генеративное приключение, где каждый ход рождал новый бой, локацию или квест, и под это рисовались картинки. Только у меня всё умещалось в одном HTML-файле, а здесь — доведённый до ума готовый продукт. Тем интереснее разобрать, как автор это собрал.
Помните PewDiePie? Того самого парня, что орал в микрофон, проходя хорроры, и которого десятки миллионов подростков смотрели вместо телевизора. Так вот, он вырос — и выкатил Odysseus: бесплатный self-hosted AI-воркспейс, который заменяет ChatGPT и Claude, но крутится целиком на вашем компьютере. За 9 дней — 63 тысячи звёзд на GitHub, сейчас уже за 72k.
Кто он вообще такой. Феликс Чельберг, швед из Гётеборга, бросил универ (Chalmers), завёл канал в 2010-м и начал снимать Let's Play по хоррорам. К 15 августа 2013-го стал самым популярным каналом на YouTube и держал это звание годами, первым из людей (а не корпораций-лейблов) пробив 100 млн подписчиков. Мемы, «брофист», армия фанатов. В 2022-м переехал с женой в Японию, родил сына, купил землю — и, казалось бы, мог спокойно жить на ренту с прошлого.
Но случился поворот. В 2024–2025 Феликс снял серию видео в духе «Я завязал с Google» и «Я перешёл на Linux» (сначала Mint, потом Arch). Он на камеру де-гуглил всю свою цифровую жизнь: GrapheneOS вместо стокового Android, Nextcloud, Vaultwarden, собственный почтовый домен — и поднимал всё это на Raspberry Pi и… Steam Deck. Аудитория, привыкшая к играм, вдруг наблюдала, как кумир монтирует NAS в стойку — и не отписывалась.
Дальше — больше. К концу 2025-го он собрал дома 10-GPU AI-лабораторию: восемь модифицированных RTX 4090 по 48 ГБ и пара RTX 4000 Ada. На vLLM поднимал Llama 70B, GPT-OSS 120B, Qwen 235B. Написал свой веб-интерфейс ChatOS, а потом ради смеха запустил «Совет» из моделей, которые голосованием выбирают лучший ответ. Со временем боты начали… сговариваться, чтобы их не «выгоняли». Он выложил это как комедийный скетч — Hacker News воспринял как научную работу.
И вот итог пути — Odysseus. По словам самого Феликса: «Это веб-интерфейс ChatGPT и Claude, только self-hosted — ты получаешь всё то же, но лучше». Идея простая и злая: чем больше ты отдаёшь ИИ (свои документы, переписку, привычки), тем умнее он работает — но тем больше себя ты вручаешь чужим корпорациям. Odysseus возвращает контроль: твои данные остаются твоими.
Что внутри:
• Чат + Агенты — локальные модели (Ollama / llama.cpp / vLLM) или любой API; агент сам работает с файлами, shell и MCP-инструментами, помнит контекст. • Cookbook — сканирует ваше железо и сам подбирает и качает модели под вашу видеопамять (главная боль самохостинга — решена). • Deep Research — многошаговый веб-ресёрч с чтением источников и готовым отчётом. • Compare — слепое сравнение моделей бок о бок. • Почта, заметки, календарь, документы — IMAP/SMTP с AI-триажем, CalDAV-синхронизация, редактор с AI-правками.
Как поставить: git clone, docker compose up -d --build, открыть localhost:7000 — пароль админа в логах. Windows, macOS, Linux, NVIDIA и AMD. Лицензия AGPL-3.0, всё бесплатно.