Voicebox — это локальная голосовая студия с открытым исходным кодом, которая в одиночку закрывает то, за что обычно платят сразу двум облачным сервисам. ElevenLabs отвечает за вывод — синтез и клонирование голоса. WisprFlow — за ввод, голосовую диктовку. Voicebox делает обе половины этого цикла и, в отличие от обоих, крутит всё прямо на вашей машине: без аккаунтов, без API-ключей и без единого байта, уходящего в облако.
Автор проекта — Джейми Пайн, тот самый разработчик кросс-платформенного файлового менеджера Spacedrive. Voicebox выложен под лицензией MIT и за считанные недели собрал почти 35 тысяч звёзд на GitHub, влетев в недельный тренд.
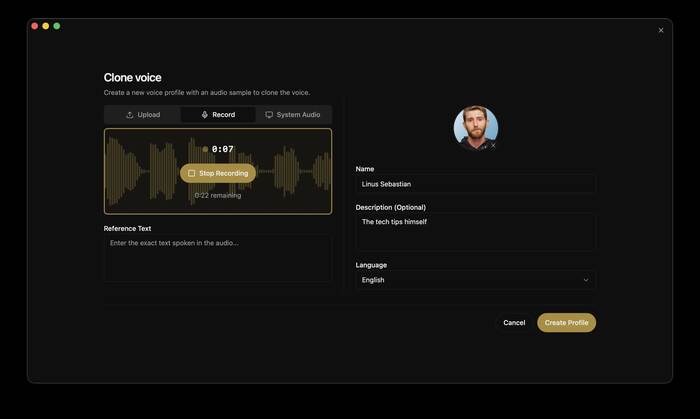
Клонирование голоса. Достаточно пары секунд аудио-референса — загрузите файл, запишите с микрофона или захватите системный звук, и приложение создаёт голосовой профиль (на скриншоте выше — как раз это окно). Не хочется возиться — в комплекте 50+ готовых пресет-голосов.
Семь TTS-движков под капотом. Qwen3-TTS, Qwen CustomVoice, LuxTTS, Chatterbox Multilingual, Chatterbox Turbo, HumeAI TADA и Kokoro — каждый со своими сильными сторонами, переключаются на лету. В сумме 23 языка: от английского до арабского, японского, хинди и суахили. Chatterbox Turbo понимает паралингвистические теги вроде [laugh], [sigh], [gasp] — эмоции и звуки прямо в тексте.
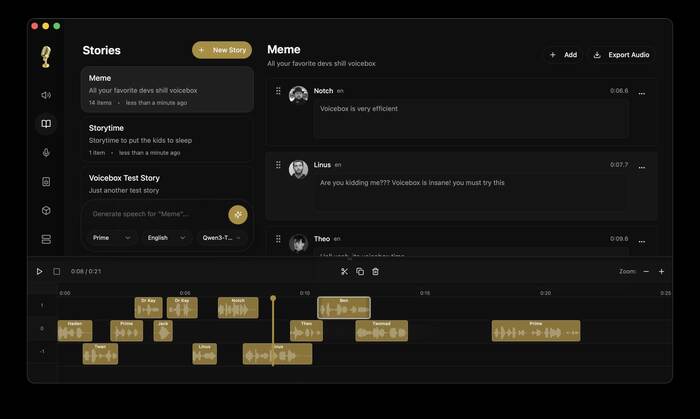
Многодорожечный редактор «историй». Отдельный режим для подкастов, диалогов и аудиокниг: дорожки с разными голосами, перетаскивание, обрезка и склейка клипов прямо на таймлайне (на скриншоте выше).
Голосовой ввод. Глобальный хоткей в любом приложении: зажал, проговорил, отпустил — на macOS текст сам вставляется в активное поле. Транскрипция на Whisper (включая Turbo, примерно в 8 раз быстрее Large). Опционально локальная LLM подчищает «эээ», запинки и оговорки перед вставкой.
Голос для ИИ-агентов. Через встроенный MCP-сервер любой агент — Claude Code, Cursor, Windsurf, Cline — может заговорить с вами голосом, который вы сами склонировали. Один вызов voicebox.speak, и «деплой завершён» вам произносит выбранный голос. Удобно в длинных агентских циклах, когда не хочется пялиться в терминал.
Сверху ещё постобработка звука (8 эффектов на движке pedalboard от Spotify) и генерация без ограничения длины с авто-нарезкой и кроссфейдом. Приложение нативное — собрано на Tauri (Rust), а не Electron, и работает на Windows (CUDA/DirectML), macOS (MLX/Metal) и Linux (включая AMD ROCm и Intel Arc).
Помните Ил-2 Штурмовик? Помните бота Силеро с голосами из Варкрафта? Так вот, мы доросли до того, что поучаствовали в разработке синтеза речи для новой части легендарной игры. На этом всё, доклад окончен.
Нам посчастливилось принять участие в разработке синтеза речи для новой версии игры игры Ил-2 Штурмовик — Ил-2: Корея. Это был длинный путь, но в итоге у нас получилось:
Сделать синтез на 8 языках русском, английском, китайском, корейском, японском, немецком, французском и итальянском;
В итоге пришлось работать на основе записей "профессиональных программистов" (как в старые добрые, но в этот раз это были C++ программисты-разработчики игры);
Синтез работает только на CPU практически без задержек;
Голоса умеют не только говорить, но и "кричать".
В игре на данный момент озвучиваются только игровые боты (игра сейчас в раннем доступе), но возможно когда-нибудь синтез доедет и до мультиплеера.
Как это выглядит в игре
Демонстрацию ниже для нас сделали разработчики игры. Сразу нужно оговориться, что "крик" тут немного "особенный" и скорее соответствует очень возбуждённой речи в стрессовой ситуации.
То есть, грубо говоря, в идеале должна быть довольно пунктирная речь, или очень возбуждённая пунктирная речь. Естественно в игре на это накладывается шум радио и двигателя самолёта, что несколько сглаживает углы и понижает требования к качеству синтеза.
Легенда ИЛ-2 и текущее состояние игровой индустрии в России
Ну тут я довольно мало во что играл
Оригинальный Ил-2 Штурмовик входит в "пантеон" великих игр позапрошлой итерации нашей игровой индустрии, которая немного закончилась примерно к концу нулевых. Ну то есть было и мировое признание, и миллионные тиражи (если знаете точнее — напишите) и народная любовь. В те времена Ил-2 прямо называли лучшим авиасимулятором (ключевое слово тут симулятор) и он прямо конкурировал с Microsoft Flight Simulator по уровню популярности и фанатской любви.
Если перенестись в настоящий момент, у нас наблюдается системный кризис игровой индустрии. Все более менее успешные команды в лучшем случае "сменили прописку" (почитайте фамилии в титрах таких успешных игр как Space Marine 2 или Rogue Trader). По этой причине для нас представляет особенную радость и гордость "прикоснуться" к легенде и в идеале оставить в вечности маленький кусочек своей работы в таком легендарном продукте, который сделан в нашей стране.
Пара слов про AI-slop и не только
Многих разработчиков западных AAA-игр принципиально пытались "отменить" за присутствие низкокачественных нейросетевых ассетов в играх. Тут ситуация по сути обратная, т.к. мы не пытаемся подменять творчество нейрослопом (или агрессивно резать косты, выставляя нереалистичные задачи команде разработки на фоне общего навязывания "круток" и "подписок").
По сути мы создаём контент, который бы иначе не мог бы в принципе быть создан. А именно сам контент игры по факту создаётся людьми (синтез только озвучивает то, что ему дал разработчик).
Постановка задачи
Весь проект, если коротко
В современном мире задача сделать "yet another" синтез же простая, правда? Берёшь самый модный публичный репозиторий с 100500 звёзд и самой большой LLM, берёшь, что записал диктор, и "GPUs Go Brrr", правда? Но, к сожалению, нет.
Какое-то время назад к нам обратились разработчики игры и рассказали, что хотят добавить синтез в свою игру. При этом на старте сразу обсуждался некий продуктовый список требований, при этом требования зачастую были очевидно продиктованными необходимостью:
Работа сильно быстрее реального времени без задержек (ну тут очевидно);
Работа внутри клиента игры (синтез не может зависеть от внешних серверов, да и задержка будет портить впечатление, плюс сложно масштабироваться при успехе игры);
Покрытие как минимум 8 популярных языков (тут по сути неизбежно, так как это список воюющих сторон);
Возможность гибкой озвучки имён собственных и топонимов (без этого теряется гибкость разработки нового контента);
Возможность генерировать как обычную пунктирную речь, так и "крик" (речь должна быть похожа на то, как говорят реальные лётчики).
Программа минимум — оживить общение с игровыми ботами, диспетчерами и игровым окружением. Сделать добавление нового контента не зависящим от дикторов и разработки синтеза (все же знают приколы про "билдоту" и кривые и лишние фразы озвучки в старых играх).
"Оживление" диспетчеров и ботов подразумевает, что нужно произносить всякие разные топонимы и числа в разных комбинациях, что раньше решалось конкатенацией слов, что несколько делало игру более "роботизированной" и шаблонной. То есть заранее предзаписать всё и поддерживать это потом на N языках просто технически невозможно с современными требованиями к качеству контента.
Шумность обстановки, радиопомехи, звучание речи на фоне — несколько упрощает задачу, но не решает основной проблемы. Речь должна быть чёткой и не должна нарушать погружение игрока в игру.
Поскольку подразумевается длительная поддержка и выпуск большого количества DLC, направленных на разные театры военных действий, ситуация, где нужно потом будет бегать за дикторами на всех языках тоже — совсем не очень.
В начале нашего общения у нас была гипотеза, что раз активное комьюнити игры большое, имя студии известное, какой-то бюджет есть, то мы сможем привлечь профессиональных актёров.
В итоге найти людей-носителей нужных языков в команду для проверки синтеза и собственно создания контента получилось, а вот с актёрами озвучки вышел конфуз:
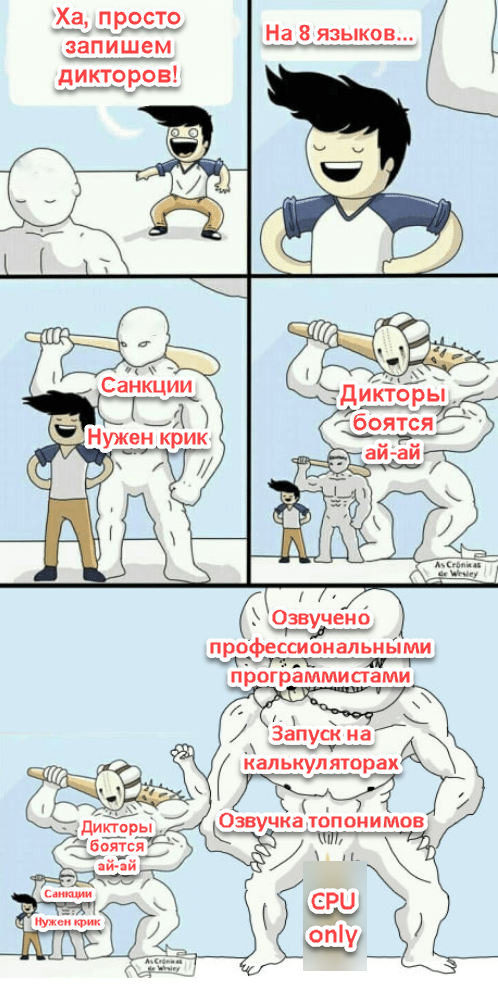
Санкции плюс мало кто хочет работать с компанией из России;
Иррациональный страх актёров перед AI (небезосновательный, если послушать безумную риторику ряда заинтересованных корпораций, в части синтеза — пока преждевременный);
Ну и ... как бы помягче сказать. В списке языков для озвучки присутствует подозрительно много стран, которые в разные исторические эпохи пытались осуществить нехорошие планы, разнящиеся от простого военного поражения до полного уничтожения нашей цивилизации.
Также в какой-то момент при планировании ресурсов стало понятно, что нельзя использовать GPU. Ну вот совсем. То есть нужна кастомная, особенная, просодия ("спокойный крик"), дикторов нет, синтез должен работать на 1 потоке процессора на "калькуляторах". Отличное начало!
Карточки есть, но использовать их нельзя
Озвучено профессиональными программистами
В сухом остатке, получается, на старте мы имеем следующее:
Отсутствует возможность привлечь профессиональных актёров в нужном количестве;
Довольно сильные требования к кастомизации, портативности, поддерживаемости;
Длинный список языков.
Отсюда получается, что неизбежно использование услуг озвучки "профессиональных программистов" как в старые добрые времена игр на CD-дисках. Но на этой базе нужно ещё и научить голоса русскоязычных программистов говорить на других языках. Бонус тут состоит в том, что целевой крик тут немного проще, чем настоящий крик у профессиональных актёров.
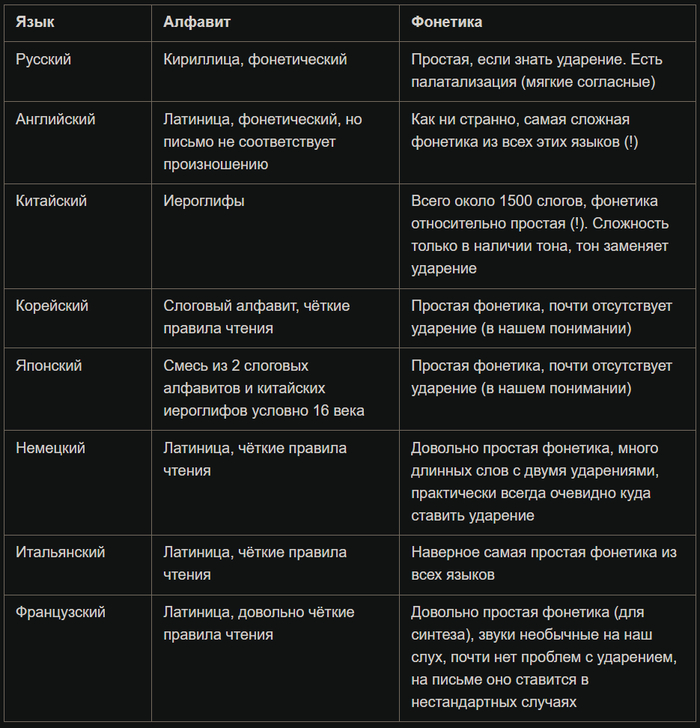
Для начала стоит взглянуть на список языков и их фонетику:
Краткое описание фонетики языков
Если, для начала для простоты, сфокусироваться на первых четырёх языках, то видно, что все языки используют совсем разные системы письма, которые ну вообще никак не связаны (разве что исторически). Отсюда получается, что надо или пытаться приводить их к некой единой схеме "правописания" или использовать фонемы.
Но даже так, слоном в комнате является английский язык, где произношение (особенно топонимов) может вообще никак не быть связано с написанием. Отсюда нужно или придумывать свою общую схема романизации / кириллизации или просто использовать фонемы.
Всё, как обычно, упирается в наличие адекватных инструментов и простоту их поддержки на дистанции:
Для русского нет адекватных готовых общепринятых инструментов по фонемизации или латинизации, увы. Но тут всё "просто". У нас они есть. Берём наши обширные словари ударений и фонем, нейросетки для ударений и фонем (фонемы разрешаются с точностью 99% на русском, если знать ударение), передаём это всё разработчику игры, и переводим все корпуса в фонемы. Ах да, ещё у нас есть активная морфология, падежи, спряжения, согласование в роде числе и падеже — но думаю вы про это всё знаете. Дальше при появлении нового слова (допустим название населённого пункта) разработчик просто ставит ударение и прогоняет слово через фонемизатор, слушает, добавляет в игру. Все эти инструменты быстрые, но на данном моменте их наличие в клиенте пока не требуется;
Для английского ввиду отсутствия падежей в современном языке — всё по сути сводится к поиску правильного словаря. Но вот незадача, если мы идём в использование фонем, то нужно выбирать словари и фонемы так, чтобы один и тот же звук в разных языках обозначал реально один и тот же звук. По сути это, конечно, проблема, так как в английском существуют десятки диалектов и люди реально говорят по-разному. И, зачастую, словари фонем существуют все в разных форматах. Это всё, естественно приходится править руками и массово отслушивать. По сути сложность задачи тут состоит в том, чтобы найти точку, где дальше различие между звуками уже не является важным. Точность фонемных моделей тут составляет примерно 95%, то есть при добавлении нового слова часто приходится переписывать, но это лучше, чем писать фонемами руками с нуля. Ещё мозг часто взрывает то, что при внимательном отслеживании материала носители языка сами очень часто не говорят знаменитый звук θ и часто жуют все гласные и превращают их в "шва";
С китайским как ни странно всё просто. Есть по сути официальный государственный фонетический стандарт пиньинь. Есть готовые библиотеки, которые переводят китайские иероглифы (汉字) в него с расстановкой тонов. Дальше, по сути у китайцев всего около 1500 слогов (слог состоит из инициали и финали). Каждый слог можно однозначно записать фонемами, то есть существует прямой словарь соответствия (плюс символы для тонов) между слогами и фонемами (естественно не все слоги встречаются во всех тонах). Особняком стоит вопрос расстановки пробелов между словами (сами китайцы их зачастую не пишут). Пробелы помогают синтезу (как минимум в индо-европейских языках) с ритмикой и ударениями. Тут это нивелируется тонами, но мы ради интереса всё-таки решили расставить пробелы между словами (но разницы особо нет, чуть докидывает буквально). Есть незакрытый вопрос с "омографами" (иногда биграммы "знаков", 字, читаются по-разному в зависимости от смысла) и тем, что некоторые тоны не могут соседствовать друг с другом (попробуйте быстро прочитать два слога подряд третьим тоном, то есть nǐ hǎo) — но это мы уже отдали на откуп самой нейросети и носителям языка. По сути использование такого процесса упрощает поддержку, так как все носители языка априори знают тоны и пиньинь (пусть писать тоны циферками и чуть менее удобно);
С корейским языком всё одновременно и очень просто, но есть свои подводные камни. Для начала, все материалы в интернете ... это, естественно, южнокорейский язык. Но тут мы ничего не можем поделать. Письмо у корейцев фонетическое, но знаки "странные", потому что глядя на китайцев (видимо они бумагу так экономили), они решили объединять свои буквы в слоги и писать их тоже "квадратиками". То есть, по сути, надо разложить "квадратики" в обычные буквы и дальше перевести в фонемы. У корейцев есть строгие правила чтения, но там ряд звуков меняется в зависимости от контекста. По идее это можно записать в виде правил ... но мы решили этот вопрос тоже через нейросети на минимальном корпусе и сформировали словарь на все слова языка. Точность перевода получается очень высокой. Из плюсов тут нет тонов, почти нет ударения и почти нет пробелов между словами;
В сухом остатке — каждый язык мы преобразуем в набор фонем. При этом мы тщательно перебрали руками все эти фонемы, чтобы они друг другу не противоречили. Это невозможно сделать абсолютно идеально, но основные проблемы классических фонемных словарей мы победили (например палатализацию). Всегда есть тонкости и маленькие детали, от которых приходится отказываться.
Итак, со "знаками" мы разобрались. Теперь нужно что-то сделать с голосами и криком. С криком проще — нужный в игре крик можно просто записать. То есть можно записать "спокойную" и "кричащую" (возбуждённую) версию голосов. Из этого, в принципе, даже можно сделать синтез на русском языке. Но как сделать синтез на всех языках?
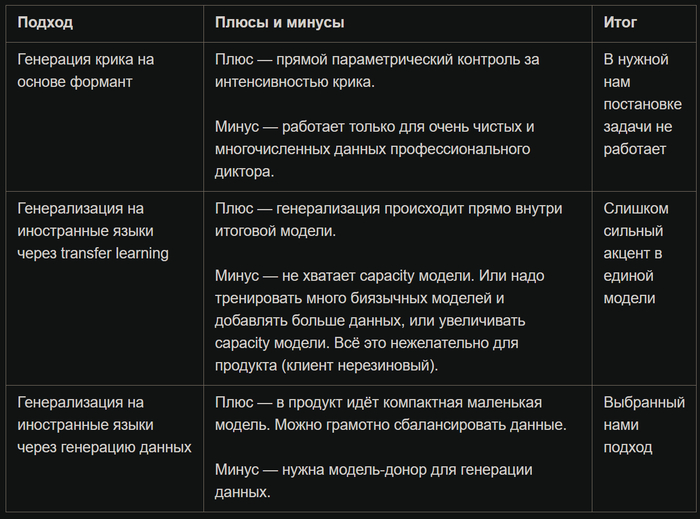
Тут, глобально мы перепробовали очень много всего, но можно глобально выделить три работающих подхода:
Подходы к снаряду
Изначально мы проделали большое количество экспериментов по генерации крика на основе формант. На чистых идеальных данных на одном языке (русском) — метод интересный и перспективный. Но когда мы стали пытаться накрутить наши данные на другие языки — метод перестал работать. Судя по проведённым экспериментам метод рабочий, если вы условно делаете Алису и не ограничены в записях, бюджете и количестве аудио.
Первую более-менее рабочую версию мы сделали на основе transfer learning, то есть когда мы обучали модели на публичных данных, и потом дообучали на наших голосах. Но тут проблема основная в том, что с учётом требования по крику, допустим два языка у нас получалось поселить в модели с нужным качеством. А дальше — уже модель начинала плыть, то есть данные шумноваты, их слишком мало. Оно говорит чётко, произносит все тоны и фонемы, но акцент слишком сильный. Носители языка совсем не одобряют, даже с учетом того, что ты управляешь самолётом.
В итоге мы остановились на том, что использовали нашу собственную систему синтеза и переозвучки, чтобы сгенерировать синтетический датасет для обучения итоговой модели. В итоге на основе уже синтетического датасета, сделанного из записей "профессиональных программистов", мы сгенерировали продуктовую модель на других языках.
Вместо вывода
Судьями нашей работы и работы разработчиков будут только игроки и время. В любом случае у нас на рынке есть не так много живых нетривиальных игровых проектов и поучаствовать в разработке продолжения легендарной игры — для нас большая удача и честь. Остаётся выразить надежду, что дальше будет только больше нетривиальных проектов и что кризис рано или поздно закончится.
Делаю пайплайн автодубляжа: на входе англоязычный ролик — на выходе русская озвучка тем же голосом. Сердце такого пайплайна — нейросеть клонирования голоса (voice-clone TTS). Главный вопрос: какую взять?
1/8
Можно ткнуть в первую попавшуюся с хайпом. А можно собрать топовые движки и устроить им честную битву на одинаковых условиях. Выбрал второе — прогнал финалистов через 627 семплов. Итоговый рейтинг — в карусели ниже, а вся подноготная (с чего начинали, кого выгнали и почему) — под ней.
Как собирал участников
Брал не наугад, а по реальным лидербордам (TTS Arena, Artificial Analysis) — только свежие флагманы. Часть кандидатов отсеялась сразу на входе: VibeVoice умеет только стриминг, OpenAudio S1 — прошлогодний, IndexTTS-2 — русский сломан, Step-Audio — только англ/кит. Осталось 8 движков для реального прогона.
Методология
Каждому движку — 114 фраз, всего 627 семплов. Тесты: русский и английский, длинные реплики, числа (прописью и цифрами), аббревиатуры (СДВГ, ОКР), иностранные слова, имена, скороговорки, смесь языков. И главное — cross-lingual: английский голос читает русский текст. Это и есть дубляж.
Оценивал на слух, семантически: засчитано всё, что произнесено верно. Если распознавалка записала «десять» как «10», а «Stable Diffusion» как «стейбл дифьюжн» — это её косяк, а не движка: зритель-то слышит правильно. Метрики: разборчивость, похожесть голоса, утечка латиницы, скорость, VRAM, вес на диске. Итоговый балл взвесил под задачу дубляжа.
Двоих выгнали сразу
После предварительного прогона вылетели двое:
dots.tts — на женском голосе разваливался: вместо русского текста выдавал английскую кашу или просто тишину. Плюс самый медленный. На вылет.
Chatterbox — умеет только режим без транскрипта, говорит с заметным акцентом, по сумме не конкурент. Тоже за борт.
Осталось 6 финалистов — детально по каждому в карусели выше, тут коротко:
Финалисты
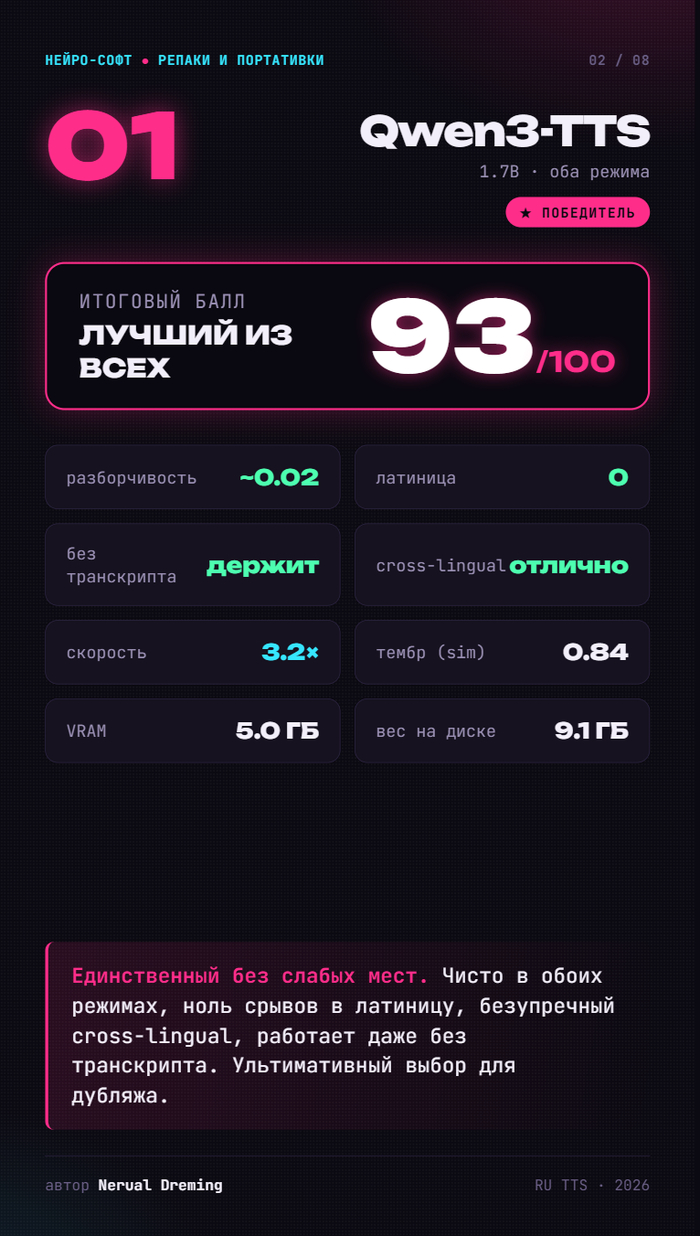
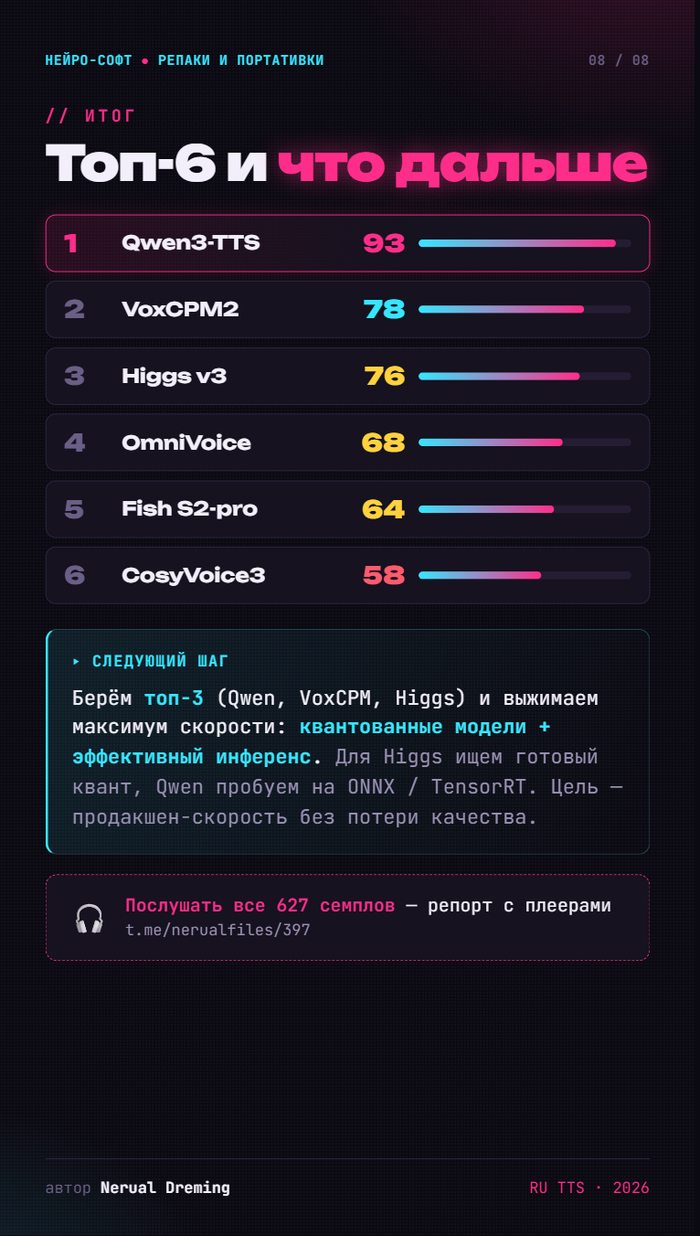
🥇 Qwen3-TTS — 93/100. Чемпион. Единственный без слабых мест: чистая речь и с транскриптом, и без, ноль срывов в латиницу, безупречный cross-lingual, быстрый. Его и берём.
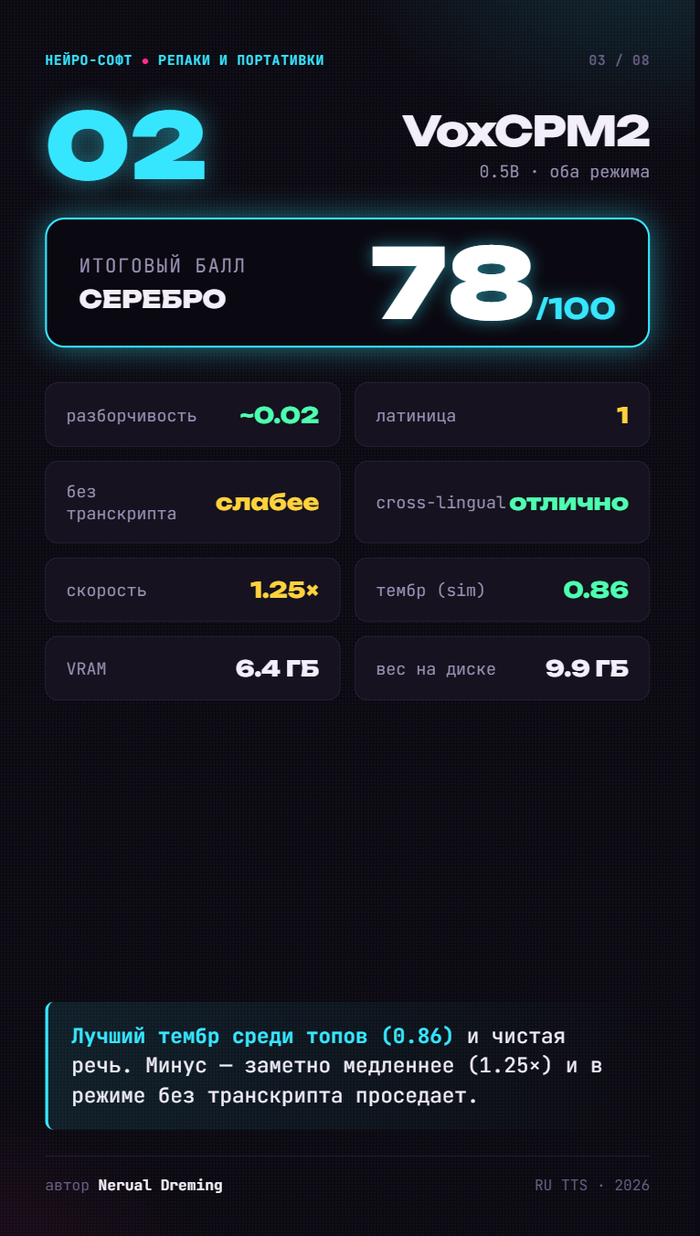
🥈 VoxCPM2 — 78. Лучший тембр среди топов, чистая речь. Минус — медленный и без транскрипта проседает.
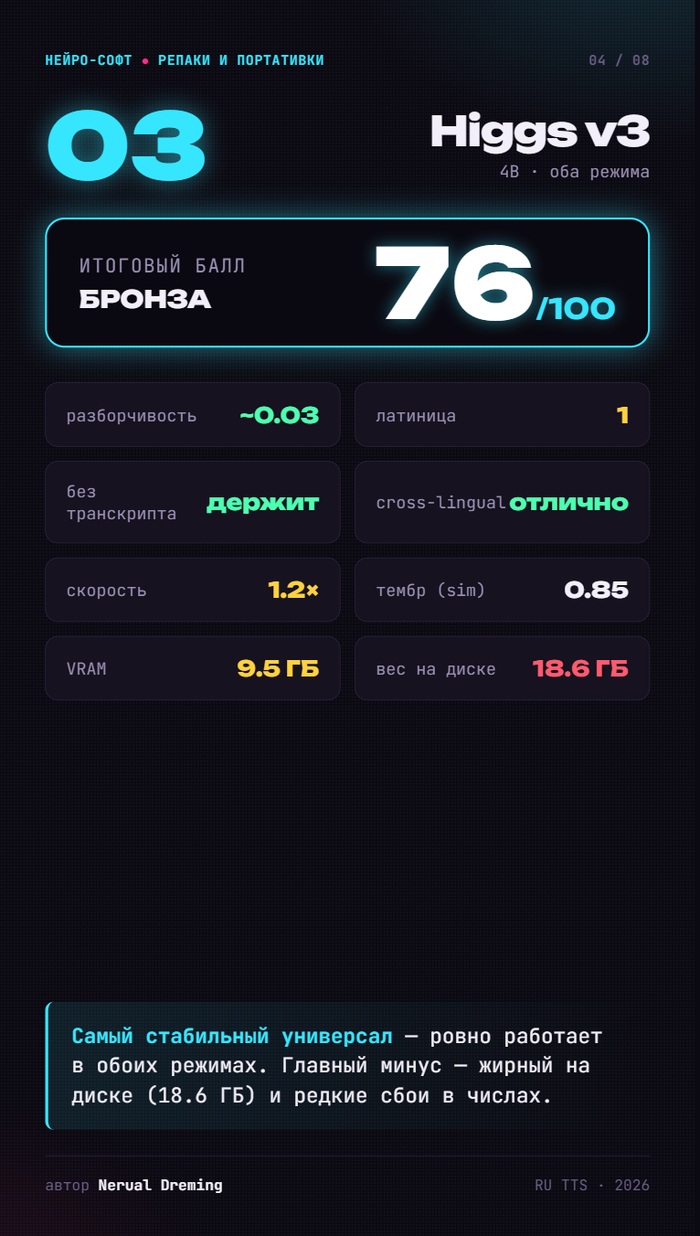
🥉 Higgs v3 — 76. Самый стабильный универсал. Главная беда — 18.6 ГБ на диске.
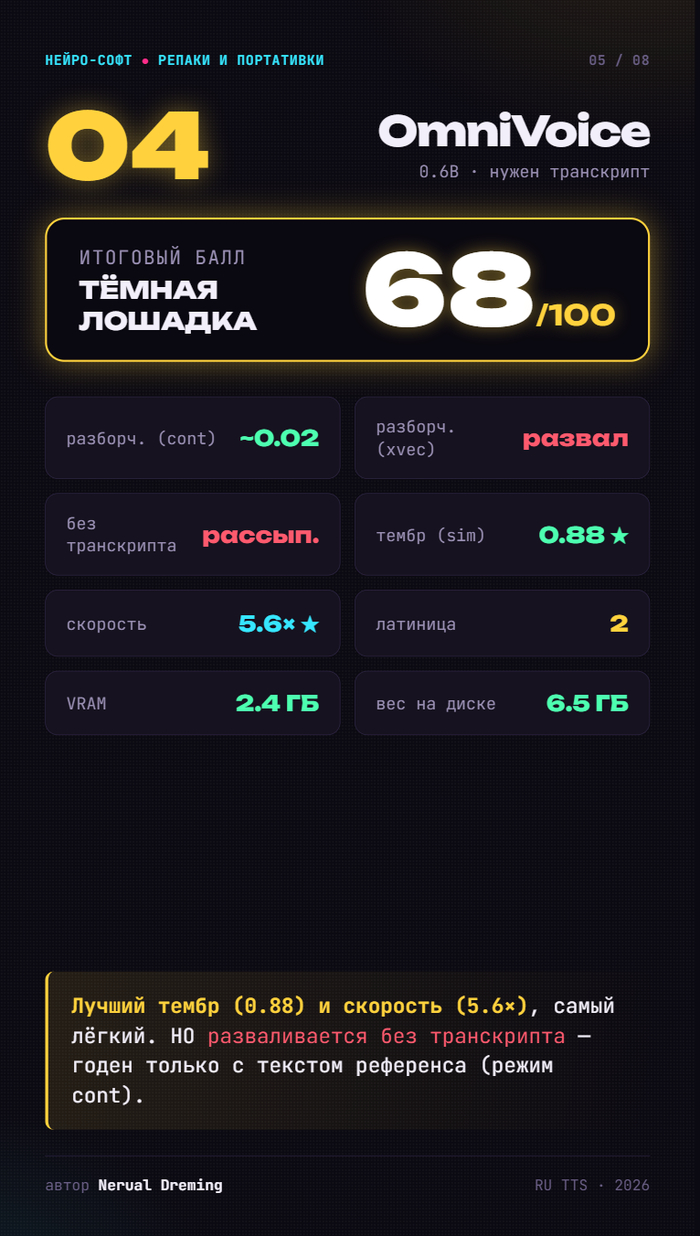
OmniVoice — 68. Тёмная лошадка: лучший тембр (0.88) и самый быстрый (×5.6 от реалтайма), легчайший. НО разваливается без транскрипта — годен только с текстом референса.
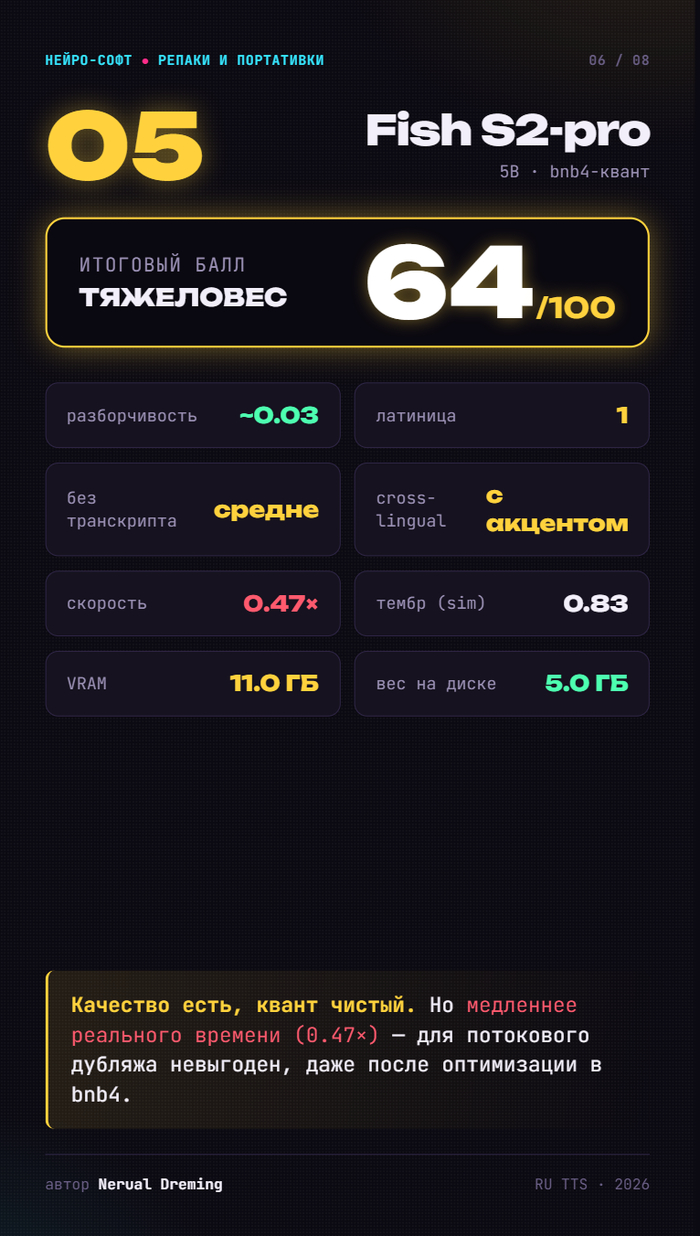
Fish S2-pro — 64. Качество есть, но медленнее реального времени даже после оптимизации. Для потока невыгоден.
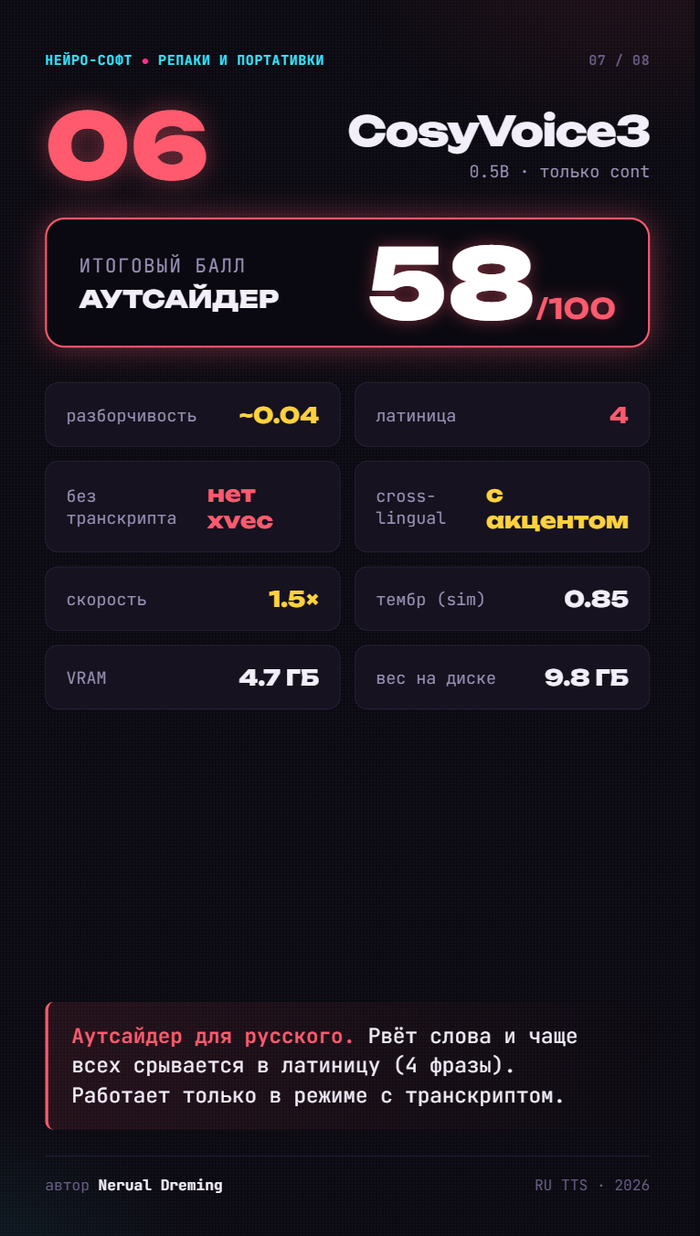
CosyVoice3 — 58. Аутсайдер для русского: рвёт слова и чаще всех срывается в латиницу.
Подводные камни (для технарей)
Fish в полной версии не влезал в 24 ГБ видеопамяти — распухал KV-кэш. Взял квантованную bnb4, сверил с полной по качеству (A/B) — квант оказался чистым.
CosyVoice пробовал ускорить через GGUF — и женский голос зациклился в 82 секунды мусора. Оказалось, баг самого тракта запуска (не доходит до токена остановки), а не квантизации.
Главная ловушка — распознавалка пишет англицизмы кириллицей. Чуть не записал кучу правильных озвучек в брак, пока не пересмотрел каждый транскрипт глазами.
Что дальше
Беру топ-3 (Qwen, VoxCPM, Higgs) и выжимаю максимум скорости: квантованные модели + эффективный инференс. Для Higgs ищу готовый квант, Qwen пробую на ONNX / TensorRT. Цель — продакшен-скорость без потери качества.
🎧 Хотите послушать все 627 семплов сами — собрал отдельный репорт с плеерами: t.me/nerualfiles/397
Это первая часть. В следующей — оптимизирую топ-3 под продакшен: квантованные модели, ONNX, TensorRT — и замерю реальный прирост скорости без потери качества. Будет интересно.
Друзья, не знаю чем объяснить мою страсть к TTS, но вот свежая модель, которая показывает реально интересные результаты.
Сделала её hilab — AI-лаборатория RedNote (это китайский Xiaohongshu, «китайский инстаграм» на 300+ млн человек). Та же команда уже выкатывала в опенсорс серию dots: языковую dots.llm1 и OCR-модель dots.ocr, а теперь добралась до синтеза речи — и сразу с заявкой на open-source SOTA. На бенчмарке Seed-TTS-Eval она забирает лучший средний результат, обходя CosyVoice3, Qwen3-TTS, Seed-TTS и F5-TTS:
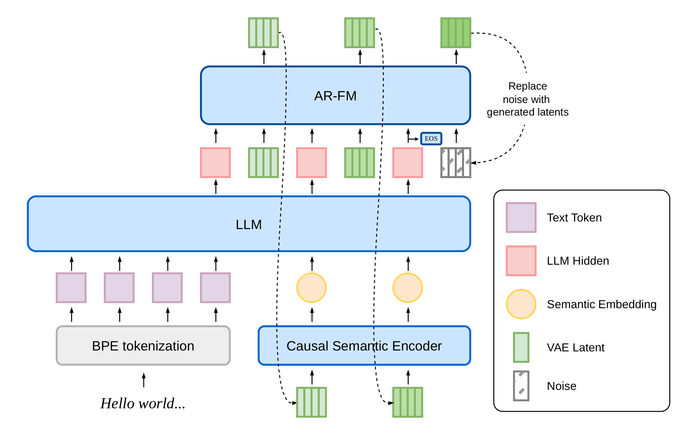
Вся соль в архитектуре. Почти все современные TTS сначала сжимают звук в дискретные «кодек-токены» и учат языковую модель предсказывать именно их — на этом квантовании теряется часть деталей голоса. dots.tts выкинул этот этап целиком: дорожка остаётся полностью непрерывной. Текст без фонем уходит в LLM на базе Qwen2.5-1.5B, акустику дорисовывает flow-matching-голова (DiT) поверх непрерывных VAE-латентов 48 кГц, а CAM++-эмбеддинг говорящего держит тембр. Отсюда чистый, естественный голос и стабильная генерация. Вот так это устроено:
Коротко по делу:
🟣 2B параметров, текст превращается в речь напрямую, без фонем
🟣 Zero-shot клонирование голоса: 3 секунды референса + транскрипт, в том числе кросс-языковое
🟣 24 языка, передаёт эмоции и контекст фразы
🟣 Seed-TTS-Eval: лучший средний результат (WER 0.94/1.30 для китайского/английского, SIM до 81); SIM 83.9 на 24-язычном бенчмарке MiniMax
🟣 Три чекпоинта: base, soar (максимальное качество клона), mf (MeanFlow-дистилляция, всего 4 шага — самый быстрый)
🟣 Стриминг по чанкам, веб-демо на Gradio, лицензия Apache-2.0
Соберёте 300 плюсиков на этом посте — соберу для неё портативку в один клик.
Всем привет! Команда Qwen от Alibaba выложила в открытый доступ Qwen3-TTS — нейросетевую модель для синтеза речи с клонированием голоса. Сегодня хочу рассказать об этой технологии подробнее и поделиться портативной версией.
Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. А еще я сам собрал портативную версию Qwen3-TTS под win11 и успел её как следует протестировать.
Главная особенность системы в том, что она умеет не только озвучивать текст готовыми голосами, но и клонировать любой голос по короткому образцу, а ещё создавать новые голоса по текстовому описанию.
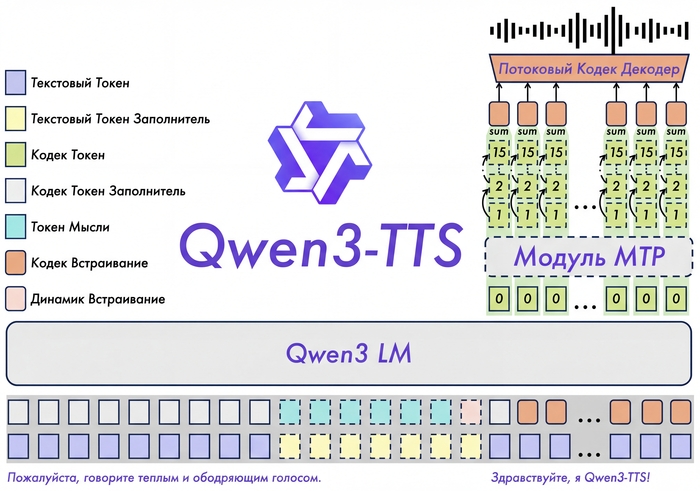
В основе Qwen3-TTS лежит End-to-End архитектура с дискретным многоканальным токенизатором речи (12.5 Гц, 16 слоёв). В отличие от традиционных систем, которые работают по цепочке "текст → фонемы → звук" и теряют информацию на каждом этапе, здесь всё обрабатывается одним махом.
Такой подход полностью исключает эффект "роботизированности" и каскадные ошибки генерации. Модель сохраняет интонации, эмоции и особенности тембра.
9 встроенных голосов разных типов — молодые и зрелые, мужские и женские. Можно управлять эмоциями и стилем речи через текстовые инструкции.
Создание голоса по описанию (VoiceDesign)
Описываете словами, какой голос нужен — модель его генерирует. Например: "молодой женский голос, игривый, с высоким тоном". Лучше работает если писать промпты на голос на английском.
Клонирование голоса (Voice Clone)
Загружаете аудио от 3 секунд — получаете синтез этим голосом. По бенчмаркам качество клонирования превосходит ElevenLabs и MiniMax по показателям сходства спикеров. Оно и правда веского качества, уровень VibeVoice, но гораздо легче по ресурсам.
NVIDIA GPU с 8+ ГБ видеопамяти (или CPU, но медленнее)
Windows 10/11 64-bit
16 ГБ оперативной памяти
20 ГБ свободного места на диске
Текущие ограничения
Ударения иногда расставляются неправильно
С длинными текстами могут быть проблемы
Инструкции для VoiceDesign лучше писать на английском
Распакуйте в корень диска (путь без кириллицы), запустите install.bat. Модели скачаются при первом запуске. А если будут сложности в установкой в посте в канале найдете версию с уже установленным env (окружением).
Я рассказываю больше о нейросетях у себя на YouTube, в телеграм и на Бусти. Буду рад вашей подписке и поддержке. Ну и на канал Нейро-Софт тоже подпишитесь, чтобы не пропустить полезные репаки. Всех обнял и удачных генераций!