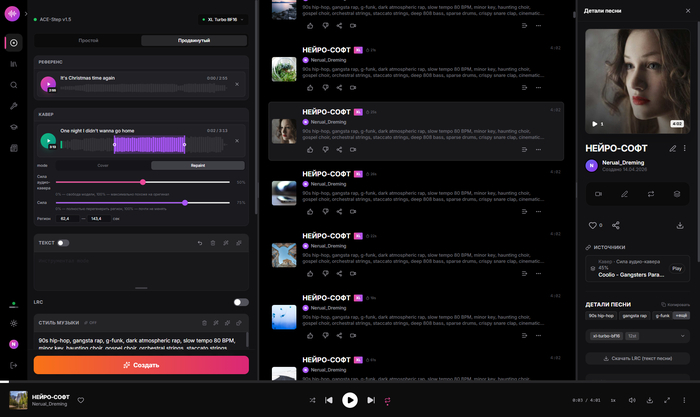
Я конечно плохо разбираюсь во всем, что касается цифровой сферы, но нейромузыка стала для меня отдушиной и способом пережить самые черные времена моей жизни.
Сейчас, придя в себя, я захотела поделиться тем, что сделала. Да, мои здесь только тексты, но к сожалению ни петь, ни сочинять музыку я не умею(хотя и представляю, как должна звучать та или иная песня, я не могу написать музыку сама).
Если кому-то понравится, будет круто.
Не понравится - так хотя бы это будет где-то кроме моей личной фонотеки.
Не нашла, как добавить только треки, поэтому быстренько сгенерировала видео.
Залип вечером в Suno, захотел трек, где парень и девушка поют по очереди, а в припеве сходятся вместе. И вот засада: нейросеть упорно лепила всё одним голосом, как бы я ни расставлял куплеты. Психанул, полез на Reddit, наткнулся на трюк от чувака под ником Grenar. Сработало с первого раза. Рассказываю, в чём подвох.
Подвох в одном слове
Оказалось, Suno просто не догадывается, что тебе нужны два певца. Пока ты сам в поле стиля не напишешь слово Duet, она будет петь одним голосом, хоть ты тресни. Это вообще главное условие, без него остальное бесполезно.
А дальше работают метки прямо в тексте песни. Перед куском пишешь, кто поёт, и нейронка отдаёт партию нужному голосу. Набор простой: Male Vocal - мужской, Female Vocal - женский, Both Vocals - оба разом, Duet - оба в балансе. Есть ещё варианты с ведущим и подпевкой, но для начала хватит этих.
Готовый текст, копируй и вставляй
Сделал русскую балладу, чтобы сразу было слышно, как голоса перекидываются строчками. Стиль идёт в поле стиля, текст с метками - в поле текста. Метки оставляй на английском, это команды для нейронки, а сами слова пусть будут русскими.
Стиль: Эмоциональная поп-баллада, Duet, мужской и женский вокал, романтично и душевно, аранжировка на фортепиано, медленный темп 70-80 BPM, кинематографичное нарастание, оркестровые волны, интимные куплеты, мощный гармонизированный припев, modern adult contemporary
Текст песни: [Verse 1: Male Vocal] Я ушёл от всего, что было у нас Бросил тебя под дождём Думал, что справлюсь совсем один Но всё изменилось потом
[Verse 2: Female Vocal] Ты отпустил, не борясь за нас Даже не сказал «прощай» Я стою одна в эту ночь сейчас И не знаю - почему
[Chorus: Both Vocals, Harmony] Но мы всё ещё любим друг друга Не скрыть то, что внутри горит Может, стоит попробовать снова И дать сердцам всё заживить
[Bridge: Female Lead, Male Backing] Если вернёшься ты ко мне (ко мне) Клянусь, я не уйду (не уйду) Мы всё начнём с нуля (с нуля)
Вот что выдала Suno. За одну генерацию она кидает сразу два варианта, так что выбираешь который зашёл.
Если опять поёт одним голосом, смотри сюда. Первое и главное - проверь, есть ли Duet в стиле, обычно дело именно в этом. Второе - не давай обоим певцам одинаковые строки, иначе нейронке нечего различать. Третье - не части с переключениями, четыре-шесть смен голоса на трек максимум, иначе получится каша.
Запускал через нашего бота, там Suno последней версии и сразу два варианта на выходе. Накидайте в комменты, какой жанр прогнать следующим: рок, рэп-баттл или что поспокойнее.
Помню, как ещё в начале 80-х гг. прошлого века, будучи старшеклассниками в школе, впервые услышали корифеев спейс-рока – французско-итальянскую группу Rockets, и всё – запали на «ракеты» (костюмированные под пришельцев).
А время было такое, пока ещё советское, – поголовное увлечение темой космоса, научных открытий и, конечно же, НФ (по-западному – сай-фай) в литературе и кинематографе. Ну, у нас-то кроме громких имён нф-шной отечественной культуры особо и не было ничего из того, что наблюдалось во всём мире (о классике жанра, которых издавал в Союзе многотомниками, типа Верна, Уэллса и Конан Дойла речь не идёт). Братья Стругацкие, Ефремов, Парнов, Можейко-Булычев, более древние Беляев и Толстой (который Алексей Николаевич)… Ну и масса менее известных, постоянно публиковавшихся в коллективных нф-шных сборниках и антологиях, особенно в тех, которые выпускало издательство «Молодая гвардия».
Нет, просачивались и забугорные фантасты, типа Азимова, Брэдбери, Саймака и Кларка с Воннегутом в придачу. Это то, что называлось гордо и пафосно – «социальная фантастика». Но вся западная великолепная семерка или даже целая плеяда топовых авторов, как сайенс-фикшн так и фэнтезятины, бывших на слуху во всем мире, – вот такого мы, конечно, до поры не слышали и не видели.
Зато в музыке было как-то полегче и попросторнее, что ли. Так и рокетсы к нам проникли – на плашках, на катушках, на кассетах. Альбом за альбомом – Пластероид, Галактика, Пи 3.14, Атомик… А мы от них торчали и даже фанатели.
Как сейчас говорят, «топили» и за Крафтверк, Спейс, Мородера и, особенно, Жана-Мишеля Жарра. Но Рокетс стоял наособицу. Ни с кем и ни с чем не спутаешь. Потом пошли разные Визиторс, Телекс и т.п., но имхо то больше смахивало на подражание «ракетам». Пожалуй, достойным продолжателем рокетсов можно назвать лишь Дмитрия Нелепина с его каверами и собственным оригинальным творчеством.
Короче, спустя 35 лет чёт ностальгия торкнула, решил отдать дань уважения кумирам молодости и загенерил несколько вариаций своей версии спейс-рока плюс синти-поп. Разместил здесь https://4beat.ru/albums/grimdark-of-space-album-3600
постер альбома "Grimdark of Space" (стиль: Space Rock, Krautrock, Spacesynth, Synthpop)
Нейросети постепенно становятся частью повседневных задач: кто-то генерирует изображения для соцсетей, кто-то просит ИИ написать текст, а кто-то собирает презентации за несколько минут. И всё это теперь можно делать прямо внутри мессенджера MAX.
Главное преимущество такого формата — удобство. Не нужно открывать десятки вкладок, регистрироваться на отдельных сайтах или переключаться между сервисами. Достаточно найти чат-бота в MAX и начать диалог.
Количество ИИ-инструментов в платформе постоянно растет: появляются боты для генерации фото, работы с текстом, создания презентаций и даже музыки. В статье разберем, какие нейросети в MAX стоит попробовать в 2026 году, какие задачи они решают и где доступны бесплатные функции.
Какие бывают ИИ-боты
Чтобы проще ориентироваться среди инструментов, удобно разделить их по задачам.
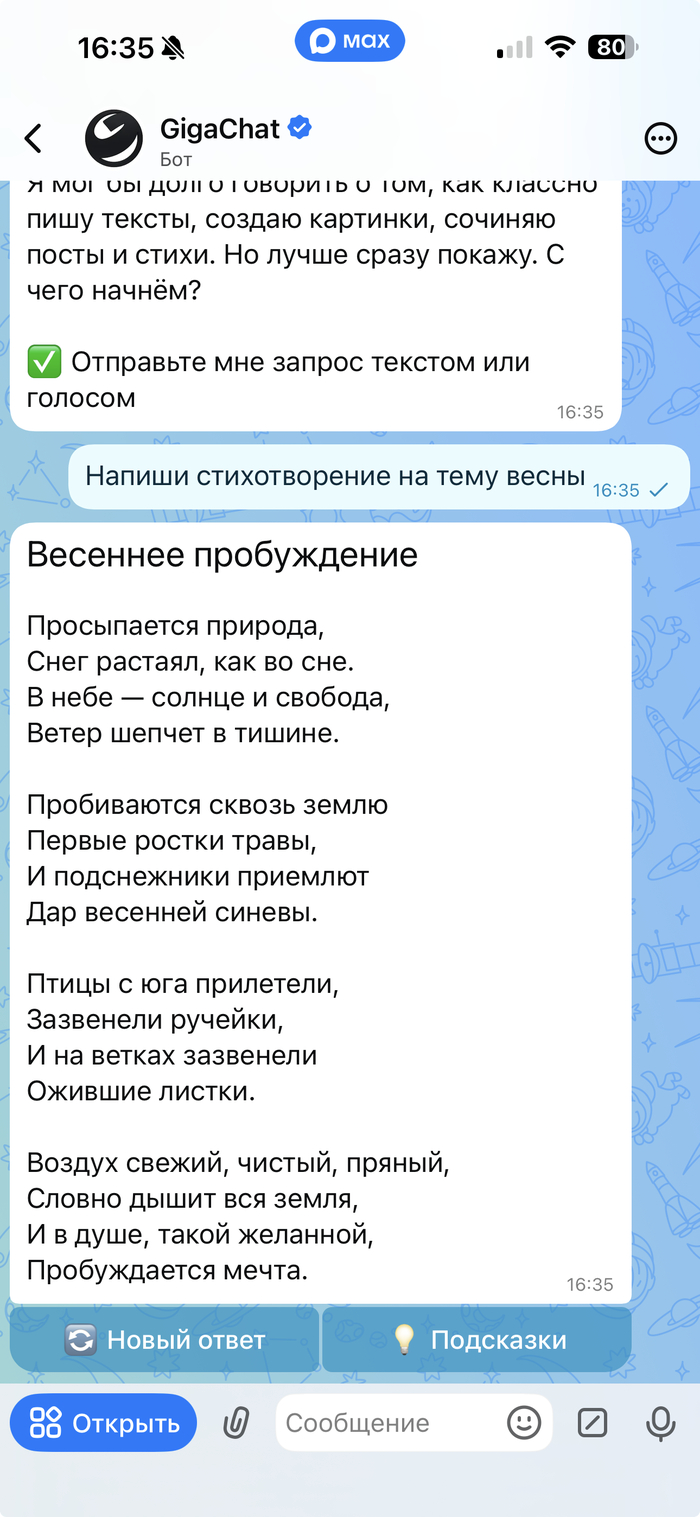
1.Текстовые ИИ-ассистенты
Это самая распространенная категория. Такие чат-боты помогают:
писать тексты;
сокращать статьи;
переводить;
генерировать идеи;
составлять планы;
отвечать на вопросы.
Например, можно отправить ссылку на материал и получить краткий пересказ, попросить составить структуру статьи или подготовить сценарий для выступления.
Многие пользователи ищут именно чат бот ИИ в Максе как альтернативу привычным нейросетям вроде Chat GPT.
2. Боты для генерации фото
Один из самых популярных запросов сегодня — нейросеть для генерации фото. Такие боты работают просто: вы описываете изображение текстом, а система создает готовую картинку.
С их помощью можно:
делать иллюстрации;
создавать обложки;
генерировать аватары;
придумывать изображения для контента.
Качество результата сильно зависит от описания. Чем точнее запрос, тем лучше итоговая картинка.
3. ИИ для презентаций
Отдельная категория боты, которые помогают собирать презентации автоматически.
Обычно такие инструменты:
создают структуру;
подбирают оформление;
генерируют изображения;
оформляют слайды;
экспортируют файл в PowerPoint.
Это удобно, когда нужно быстро подготовить материал без долгой ручной работы.
4. Боты для видео и аудио
Пока таких решений меньше, но интерес к ним растет. Нейросеть видео в MAX может:
создавать короткие ролики;
делать субтитры;
переводить голос в текст;
расшифровывать аудио;
превращать заметки в готовый текст.
Такие инструменты особенно полезны для контент-мейкеров и тех, кто работает с большим количеством медиафайлов.
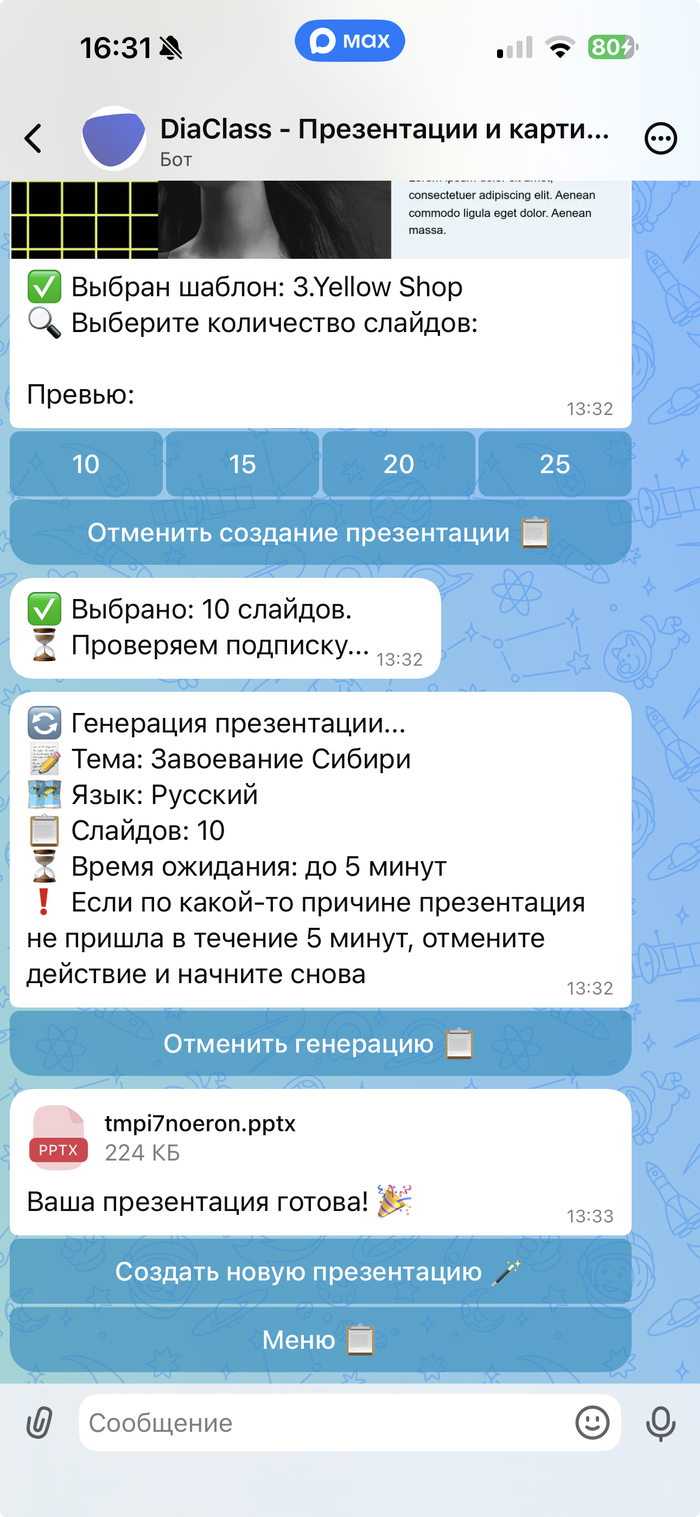
Среди инструментов есть бот от платформы интерактивных презентаций DiaClass — бот для создания слайдов и генерации изображений прямо внутри MAX.
Бот DiaClass
Принцип работы простой: пользователь задает тему, выбирает язык и количество слайдов, после чего система автоматически собирает готовую презентацию. Файл можно скачать в формате PowerPoint и доработать вручную при необходимости.
Дополнительно бот умеет генерировать картинки по текстовому описанию.
Несколько генераций изображений доступны бесплатно, а для презентаций потребуется платная подписка от 179 р в месяц.
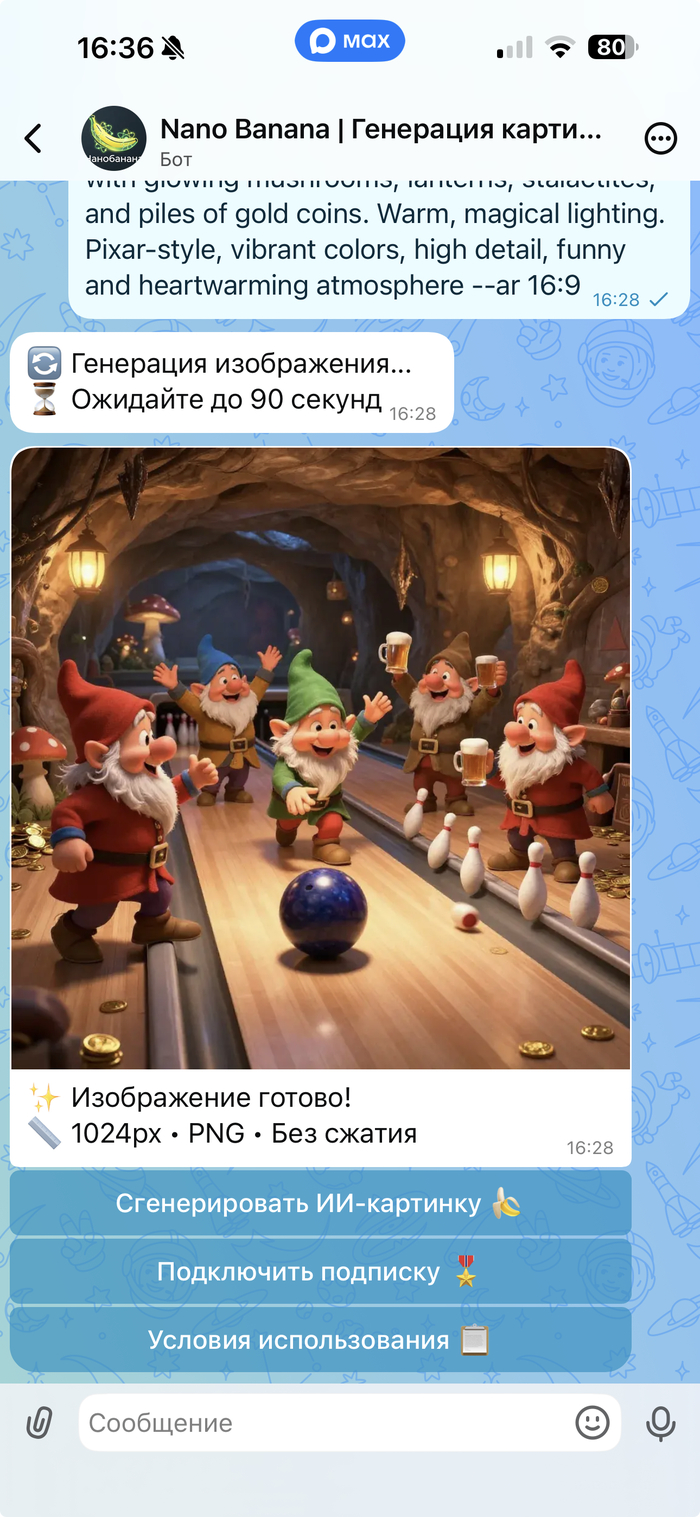
Если нужен бот с нейросетью для генерации изображений, стоит обратить внимание на Nano Banana. Этот сервис специализируется именно на создании картинок по текстовому описанию.
Nano Banana
Работает всё просто: пользователь вводит запрос, указывает стиль или формат изображения, а нейросеть генерирует готовую картинку буквально за минуту.
Как и многие боты, сервис предоставляет несколько пробных генераций. После этого можно оформить подписку или купить дополнительные попытки.
Отдельного внимания заслуживает бот, ориентированный на создание ИИ-фотосессий. Это уже не просто нейросеть фото, а полноценный инструмент для генерации визуального контента по загруженному снимку.
Бот для фотосессий
Работает всё достаточно просто: пользователь отправляет фотографию, а бот создает готовые изображения в разных стилях и локациях. Можно выбрать шаблон или придумать собственный сценарий фотосессии.
Например, нейросеть способна:
создать атмосферу кино или fashion-съемки;
сделать фотосессию в космосе или на другой планете;
сгенерировать парные изображения;
Такой ИИ бот для фото в Максе создаст необычные изображения без студии и сложной обработки.
Сервис предоставляет 10 бесплатных кредитов, этого хватит на одну генерацию. После можно приобрести дополнительные попытки или оформить подписку.
Необычный формат среди ботов — генератор музыки. ПесняAI позволяет создавать треки по текстовому описанию. Пользователь задает:
настроение;
стиль;
жанр;
идею композиции.
Бот для генерации песен
После этого система собирает музыкальный фрагмент с вокалом и инструментами.
Итоги
ИИ-боты в MAX превращаются в полноценные рабочие сервисы. Сегодня прямо в мессенджере можно написать текст, создать изображение, собрать презентацию или даже сгенерировать музыку.
Главное помнить, что любая ИИ нейросеть может ошибаться. Поэтому важную информацию стоит перепроверять, а готовые материалы адаптировать под свои задачи.
Искусственный интеллект давно перестал быть инструментом только для программистов и технарей — и Suno AI наглядно это доказывает. Когда в 2024 году платформа взорвала рынок AI-музыки, многие считали, что дальше расти уже некуда. Но с выходом версии Suno 5.5 площадка доказала обратное. Новое обновление приносит три ключевых нововведения — и каждое из них направлено на то, чтобы музыка, которую вы создаете с помощью нейросети, звучала как ваша, а не как «сгенерированная».
В этом обзоре я разберу, что именно изменилось, как работают новые функции и кому версия 5.5 будет особенно полезна.
Что нового в Suno AI 5.5
Версия 5.5 — это не просто плановое обновление с косметическими правками. Это принципиальный разворот платформы в сторону персонализации: Suno перестает быть универсальным генератором треков и становится инструментом, который учится работать именно с вами, вашим голосом и вашим музыкальным вкусом. Ниже разбираю каждое ключевое нововведение подробно.
Voices — ваш голос в ваших треках
Это, пожалуй, самое долгожданное обновление в истории платформы: функция Voices возглавляла список самых запрашиваемых пользователями возможностей на протяжении нескольких лет. Теперь она наконец стала реальностью — и работает именно так, как хотелось бы.
Суть проста: вы записываете или загружаете аудио со своим голосом, и Suno встраивает его в генерируемые треки. Если раньше платформа выбирала певца самостоятельно, то теперь в финальном треке звучите вы — или, точнее, нейросетевая модель вашего голоса, обученная на ваших записях.
Вот как устроен процесс настройки голоса:
Запись или загрузка аудио. Вы можете записать голос прямо в браузере, выбрать готовый файл с устройства или взять уже существующий трек из своей библиотеки Suno. Минимальная длина записи — 15 секунд, максимальная — 4 минуты. Suno автоматически предложит выбрать лучшие 2 минуты из загруженного материала.
Автоматическое выделение вокала. Если в аудиофайле есть инструментальный фон, Suno сама отделит голос от музыки с помощью технологии stem splitting. Это важно: вам не обязательно иметь студийную запись a cappella, хотя она дает лучший результат.
Верификация голоса. После загрузки система показывает случайную фразу и просит произнести ее вслух в режиме реального времени. Это антимошенническая мера: система сравнивает произнесенную фразу с загруженным вокалом и убеждается, что они принадлежат одному человеку. Таким образом Suno защищает от несанкционированного клонирования чужих голосов — публичных личностей, коллег, партнеров.
Настройка профиля. После верификации вы даете голосу имя, указываете уровень вокального мастерства и при желании загружаете аватар. Готовый профиль сохраняется и доступен при каждой новой генерации.
Генерация с вашим голосом. При создании трека вы выбираете нужный голосовой профиль, пишете текст песни, добавляете стилевые дескрипторы — и нажимаете «Создать». Важная деталь: слайдер Audio Influence рекомендуется держать на высоком значении (75–100%), иначе модель может «соскользнуть» на стандартный голос.
Voices доступна только для подписчиков Pro и Premier. В бета-период создание трека с голосом стоит всего 4 кредита. Голосовой профиль по умолчанию приватен: только вы можете использовать его для новых песен. В будущем Suno планирует добавить возможность делиться голосами — но с сохранением авторского контроля.
Функция недоступна пользователям моложе 18 лет и пока не работает во всех регионах.
Custom Models — нейросеть, настроенная под ваш стиль
Если Voices отвечает за то, как звучит ваш голос, то Custom Models отвечают за то, как звучит ваша музыка в целом. Это полноценная персонализация самой модели генерации.
Механика следующая: вы загружаете в Suno треки из своего каталога — музыку, которую вы создали вне платформы, — и на основе этих материалов система обучает персональную версию модели v5.5, которая улавливает вашу подпись: характерные гармонии, темп, звуковую эстетику, тембральные предпочтения, способ сводки.
Несколько важных деталей:
Для создания модели нужно загрузить минимум 6 треков. Опытные пользователи рекомендуют загружать 20–80 треков с разнообразием внутри одного стиля — это снижает риск «переобучения», при котором модель начинает буквально копировать элементы конкретных загруженных песен.
Есть функция Bulk Upload — пакетная загрузка, которая существенно экономит время при больших каталогах.
Обучение модели занимает всего 2–5 минут, после чего она появляется в выпадающем меню выбора модели рядом со стандартными версиями.
Подписчики Pro и Premier могут создать до трех персональных моделей — например, одну для электронной музыки, вторую для акустики, третью для экспериментального жанра.
Модели приватны и недоступны другим пользователям.
Custom Models — это то, чего давно не хватало профессионалам и продюсерам, которым важна стилистическая консистентность: теперь не нужно каждый раз заново прописывать длинные промпты с описанием звука, потому что нейросеть уже знает, что именно вам нужно.
My Taste — нейросеть, которая вас изучает
My Taste — самая «тихая» из трех новинок, но при этом одна из наиболее полезных для ежедневной работы. Это система пассивной персонализации, которая не требует от вас никаких дополнительных действий.
Suno анализирует вашу историю генераций: какие жанры вы используете чаще всего, к каким настроениям и референсам возвращаетесь, что оставляете в библиотеке, а что удаляете. На основе этих данных формируется ваш персональный «вкусовой профиль», который затем влияет на работу кнопки “Magic Wand” в поле “Styles”.
Если раньше Magic Wand генерировала случайные подсказки по стилю, то теперь она предлагает варианты, которые соответствуют вашей музыкальной логике — ближе к тому, что вы уже любите и создаете. Чем активнее вы пользуетесь платформой, тем точнее система понимает ваши предпочтения.
My Taste доступна всем без исключения, включая пользователей платной подписки.
Personas превратились в Voices
Пользователи, работавшие с предыдущим инструментом Personas, заметят, что он переименован и расширен. Все ранее созданные персонажи и голосовые профили автоматически перенесены во вкладку Voices и продолжают работать. Функциональность никуда не исчезла — она стала основой для нового, более мощного инструмента.
Версия 5.5 — это осознанный шаг от «умного генератора» к чему-то большему: платформе, которая адаптируется к конкретному человеку. И судя по тому, что сама команда Suno называет эти возможности «фундаментом для следующего поколения моделей», это только начало.
Как оплатить Suno AI из России
Оплатить подписку Suno AI российской картой напрямую на сайте не получится — платформа не принимает отечественные платежные инструменты. Ниже — несколько рабочих способов получить доступ к платным функциям сервиса.
Сервисы-посредники
Это самый простой и быстрый вариант: вы переводите рубли специализированному сервису, а он оформляет подписку на ваш аккаунт с помощью иностранной карты — никаких технических сложностей.
Топ-3 проверенных сервиса:
ggsel — надежный маркетплейс цифровых товаров, где можно быстро купить подписку Suno AI с оплатой российскими картами и мгновенной доставкой на почту.
Plati.Market — крупная площадка для покупки цифровых ключей и подписок, в том числе Suno AI, с удобной оплатой и широким выбором номиналов для разных тарифных планов.
Kupikod — российский сервис моментальной покупки подписок на зарубежные сервисы, включая Suno AI, с поддержкой популярных способов оплаты и понятным интерфейсом.
Иностранная банковская карта
Если вы активно пользуетесь зарубежными сервисами и платите за несколько подписок, имеет смысл один раз открыть счет в банке дружественной юрисдикции — например, в Казахстане или Кыргызстане. Карта Visa или Mastercard такого банка принимается напрямую на сайте Suno без каких-либо надбавок. Да, потребуются усилия на оформление, но в долгосрочной перспективе это очень удобное и экономичное решение.
Помощь знакомых за рубежом
Проверенный временем способ: попросить друга, родственника или коллегу с иностранной картой оплатить подписку за вас. Никаких комиссий, никаких рисков блокировки. Чтобы не обращаться с этой просьбой каждый месяц, лучше сразу оплатить годовую подписку — это снимает регулярное неудобство и, как правило, дает скидку около 20% от стоимости помесячной оплаты.
Как начать работу с Suno AI: первые шаги
Suno не требует музыкального образования, установки программ или специального оборудования — достаточно браузера и желания попробовать. Вот как войти в процесс с нуля и сразу получить результат.
Шаг 1. Регистрация
Зайдите на сайт и нажмите “Sign Up”. Зарегистрироваться можно через аккаунт Google, Apple, Microsoft или Discord — весь процесс занимает буквально одну минуту. После входа на балансе уже будут бесплатные кредиты: новым пользователям Suno начисляет 50 кредитов ежедневно, этого хватает на 5 полноценных треков (каждый трек генерируется в двух вариантах).
Шаг 2. Выбор режима генерации
В интерфейсе создания музыки доступны два режима:
Simple — вы просто описываете песню одним текстовым запросом, все остальное Suno делает сама. Идеальный старт для знакомства с сервисом.
Custom — расширенный режим, где можно отдельно прописать текст песни, стиль музыки, исключить нежелательные жанры и точнее управлять результатом. Именно этот режим используют те, кто работает с платформой регулярно.
Для первого раза рекомендую начать с Simple — чтобы почувствовать, как сервис реагирует на запросы, и не утонуть в настройках раньше времени.
Шаг 3. Составление промпта
Здесь кроется главный секрет качественного результата. Чем точнее и конкретнее вы опишете трек, тем ближе к задуманному будет итог. Хорошо работающая структура промпта выглядит так:
жанр + настроение + инструменты + тема или образ
Несколько примеров для ориентира:
Upbeat pop song, female vocals, catchy chorus, about freedom and summer — бодрая поп-песня с женским вокалом и запоминающимся припевом о свободе и лете.
Cinematic instrumental, slow piano and strings, emotional build-up, film score style — кинематографический инструментал с нарастающей эмоцией.
Old school hip-hop beat, heavy drums, dark mood, instrumental only — классический хип-хоп-бит без вокала.
Промпты лучше писать на английском: Suno понимает русский язык, но на нем нейросеть чуть хуже соблюдает ударения в вокале и иногда смешивает языки внутри трека.
Шаг 4. Генерация и выбор варианта
После нажатия кнопки “Create” Suno формирует два варианта трека — их можно прослушать прямо в браузере, не дожидаясь окончания генерации. Обычно это занимает 10–30 секунд. Если результат не устроил — уточните формулировки и запустите повторно: идеальный трек редко получается с первой попытки, и это нормальная часть рабочего процесса.
Шаг 5. Скачивание
Готовый трек скачивается через меню с тремя точками рядом с композицией. Бесплатная версия позволяет выгружать файлы в формате MP3. Пользователи платных тарифов дополнительно получают доступ к WAV — формату без потерь качества, который удобен для дальнейшей работы в любом аудиоредакторе.
Важно знать до старта:
Бесплатная версия не дает коммерческих прав на треки — для монетизации нужна платная подписка.
Неиспользованные кредиты не переносятся на следующий день и сгорают.
Функции Voices и Custom Models доступны только на тарифах Pro и Premier.
Suno AI 5.5 — это осознанный сдвиг в философии продукта: от универсального генератора треков к персональному музыкальному инструменту, который учится работать именно с вами. Платформа явно движется в сторону полноценного творческого партнёра, а не просто инструмента автоматизации. И это делает ее интересной не только для любителей, но и для профессионалов: продюсеров, авторов-исполнителей, саунд-дизайнеров и всех, кто работает со звуком как с частью своего творческого процесса. Если вы еще не пробовали Suno — сейчас самый удачный момент. Музыка, которую вы задумали, наконец может зазвучать именно так, как вы ее слышете в голове — и именно вашим голосом.
Всем привет! Музыку я люблю всю жизнь. Сам всегда хотел научиться играть на каком-нибудь инструменте - пробовал гитару, клавиши, даже барабаны - освоил в итоге только варган. Зато с генерацией музыки нейросетями дело у меня пошло сразу. Написал в своё время один из первых на русском гайдов по Udio, недавно собрал платформу для лайвкодинга музыки с ИИ-агентом. За опенсорсом в этой теме тоже слежу - щупаю каждый раз как что-то новое появляется. Но после Suno слушать их обычно невозможно. Уровень “ну ок, оно звуки издаёт, и это тоже достижение”.
Меня зовут Илья, я блогер, основатель ArtGeneration.me и просто фанат нейросетей. Не разработчик в классическом смысле - скорее продакт с 20-летним стажем, который последние пару лет вайбкодит с помощью нейросетей всё до чего дотянется. И каждый раз когда вижу опенсорс-проект с потенциалом, у меня чешутся руки его переделать под себя. Обычно я сдерживаюсь. В этот раз - не очень получилось.
В конце марта, когда на одном из моих стримов мы смотрели обзоры на свежую тогда ACE‑Step 1.5 — опенсорсную модель от команды StepFun. Посмотрели примеры, послушали что люди нагенерировали — и я решил что это хрень не достойная внимания. Вокал мычит, куплет примерно похож на куплет, по качеству — где‑то уровень Suno v3.5, то есть позапрошлогодний Suno. Даже скачивать не стал. Подумал: ну опенсорс и опенсорс, подождём когда научится.
И оно научилось! Уже через пару недель ACE‑Step выкатили версию XL.
❯ XL - это уже другой разговор
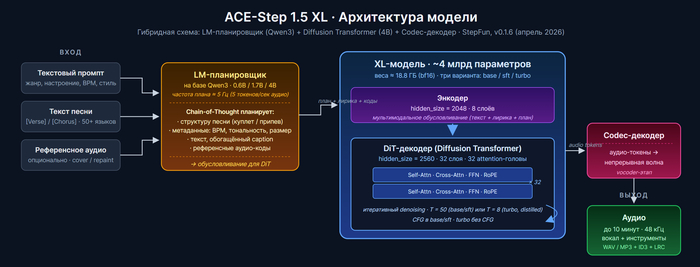
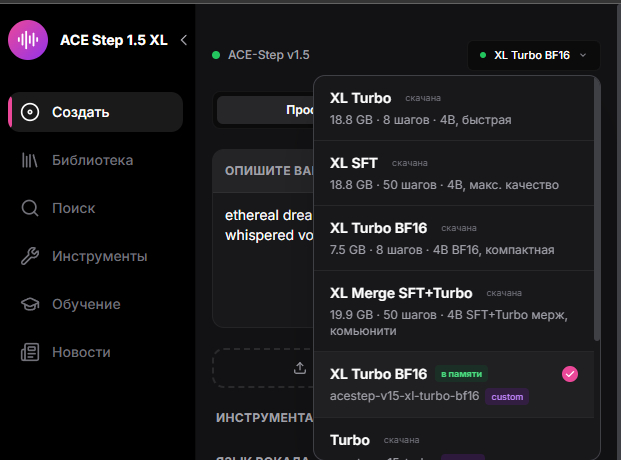
Для тех кто не в теме, коротко объясню. ACE-Step - это опенсорс-модель генерации музыки, построенная на гибридной архитектуре: языковая модель как планировщик плюс DiT (Diffusion Transformer) для синтеза звука. Базовая 1.5 была на 2 миллиарда параметров в DiT-декодере (~4.7 ГБ весов) и генерировала примерно ничего интересного. А в XL-релизе (это v0.1.6, вышел 3 апреля) команда раскачала DiT-декодер до 4 миллиардов (~9 ГБ весов в bf16), дообучила на сильно большем датасете и, судя по ощущениям, поменяла какие-то внутренности.
xl-base - 50 шагов, поддерживает CFG, умеет все задачи включая extract/lego/complete
xl-sft - 50 шагов, supervised fine-tuning, качество максимальное но только стандартные задачи
xl-turbo - 8 шагов, distillation-accelerated, без CFG, качество сопоставимо с SFT
Все три в официальных весах bf16 - это примерно 18.8 ГБ на диск. Это много. Поэтому в студию по умолчанию подключена сжатая BF16-версия Turbo от комьюнити на 7.5 ГБ, так она влезает хотя бы в 16 гигов VRAM.
Примечание: Все треки кроме последнего созданы в режиме авто-генерации, т.е. модель сама придумала как запрос с описанием жанра, так и текст для лирики. Это лишь один из режимов, можно самостоятельно сгенерировать текст и запрос для стиля в другой нейронке и получить более связанный и разумный текст. Но, по моему и так весело.
Я сгенерировал на XL Turbo, первый трек - и офигел. Нет, это всё ещё не Suno. Но это уже не “оно издаёт звуки”. Это полноценная песня с вокалом на русском (!!!), с куплетом и припевом (чаще всего очень тупым), но с осмысленной мелодией. До 8 минут длиной, на любом языке, в любом жанре. Я нагенериовал ещё десяток треков - и понял что вот в эту штуку уже как минимум весело играться.
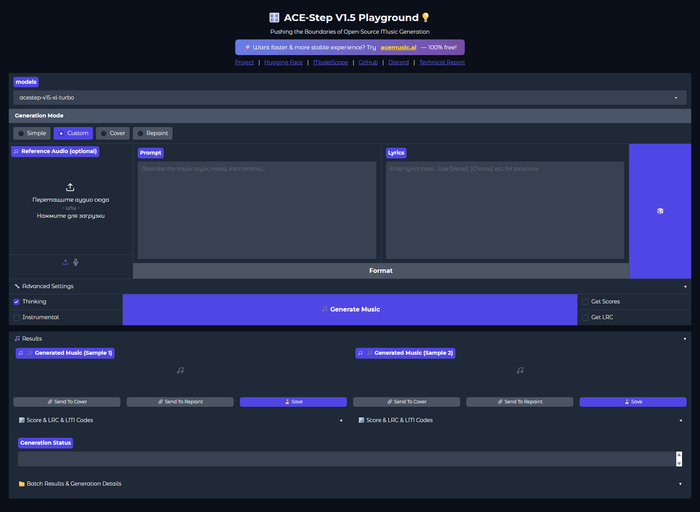
И тут же всплыла вторая проблема. Родной UI от авторов модели - это Gradio-демка. Знаете такие, где всё в один столбик, параметров полторы штуки, кнопка “Generate” и баста. Поиграться минут пять можно, делать что-то серьёзное - невозможно. А мне же хочется и красиво и удобно, иначе проще в суно.
Я пошёл искать что люди уже сделали вокруг этой модели. И нашёл проект ace-step-ui от fspecii - нормальный React-интерфейс в стиле Suno: плейлисты, карточки треков, плеер, история генераций, базовый редактор аудио, разделение дорожек, i18n на 4 языка, без русского правда, даже генератор видео с фонами из Pexels был. Человек проделал большую работу. Единственная проблема - UI был написан под базовую 1.5, про XL он ничего не знал, и там внутри было много косяков которые коипились с прошлых релизов.
И вот тут у меня в голове щёлкнуло - да я же сейчас форкну, прикручу XL, починю то что криво, добавлю то чего нет, и получится реально годная студия. На два вечера дел. Ага, на два. Спойлер: 393 моих коммита и несколько недель позже получилась штука которую я не стыжусь показывать людям.
❯ Почему форк а не с нуля
Я считаю очень важно говорить об этом честно. UI я не писал с нуля. Я форкнул чужой проект и значительно его переделал. fspecii сделал основу - React-приложение с плеером, плейлистами, карточками треков, тёмной темой, генерацией с вокалом и инструменталом, режимами Cover и Repaint под 1.5, встроенный AudioMass-редактор, разделение дорожек через Demucs, базовый видео-генератор, i18n на английский/китайский/японский/корейский, скелет LoRA-обучения. Это существенный фундамент, и я бы точно не стал начинать с нуля если бы его не было.
Что делал я сверху - адаптация всего этого под XL-модели (а это не косметика, это серьёзный ре-инжиниринг), куча новых вещей которых не было вообще, и починка того что работало кое-как. Дальше пройдусь честно по каждому пункту что именно моё.
В опенсорсе это нормальная практика - брать чужой фундамент и наращивать сверху. Главное - автора оригинала указать в README, лицензию соблюсти, звезду на гитхаб поставить. Всё это я сделал.
❯ Что я запилил - самое крутое
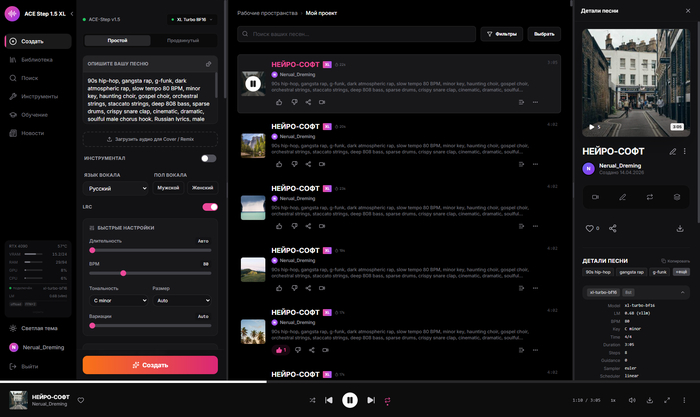
Три XL-модели в одном интерфейсе Это было первое что я начал делать. Оригинальный UI умел работать только с 1.5 и не знал про XL вообще ничего. Разные модели - разные дефолты, разные лимиты на количество шагов сэмплера, разные веса. Turbo крашится если поставить ему 50 шагов (он же distillation-accelerated, ему 8 шагов хватает). SFT выдаёт кашу если поставить 8. Пришлось делать умный выбор - когда выбираешь модель, UI сам переключает сэмплеры в допустимые для неё значения.
Плюс добавил XL Merge SFT+Turbo от комьюнити - компромиссный вариант который быстрее SFT но чуть качественнее Turbo.
Cover и Repaint адаптировал под XL
Сами режимы были в оригинальном UI, но работали криво и только под 1.5. На XL нужен был другой набор параметров, другая обработка входного аудио (падало если файл без расширения), другая логика слайдеров силы влияния. Что я переделал:
Разделил загрузку на две независимые зоны - референс отдельно, источник для кавера отдельно. В оригинале это всё лезло в одно поле и путалось.
Сделал выделение региона перетаскиванием на волновой форме для Repaint. Раньше регион задавался двумя числовыми полями - сек от, сек до. Теперь просто выделяешь мышкой.
Починил кучу багов: падение при загрузке файла без расширения, дефолтная сила кавера 100% (модель игнорировала источник, надо было 50%), повторное копирование аудио в референс-слот.
Добавил подсказки под слайдерами объясняющие что они делают.
Функционально режимы работают как и раньше - загружаешь трек, говоришь “переделай в стиле металл”, или выделяешь 15 секунд и перегенеришь. Магия тут не в UI, а в модели. Но под XL это наконец-то выдаёт что-то осмысленное.
Серверный рендеринг через ffmpeg с GPU-ускорением NVENC
Исправил баги что бы все это нормально работало
Вот про рендеринг расскажу отдельно, потому что это была отдельная боль. Базовый генератор рендерил всё на клиенте через ffmpeg.wasm. Работало, но очень медленно и регулярно падал браузер - Chrome не любит когда ему шлёшь 500 мегабайт кадров. Переписал на серверный ffmpeg, добавил кодирование кусками по 50 кадров, поднял лимит body-parser до 500 МБ - и вот теперь летает.
Страница Tools - мерджер, конвертер, Bake LoRA
Отдельная вкладка в студии, которой не было. Это уже не про генерацию музыки, а про работу с самими моделями.
BF16-конвертер - превращает safetensors модель из FP32/FP16 в BFloat16. Получается примерно -50% размера без видимой потери качества. Раньше чтобы это сделать, нужно было ставить питон, ставить зависимости, писать скрипт. Теперь - кнопка в интерфейсе.
Model Merger - объединяет две модели ACE-Step с настраиваемой альфой. Три метода мерджа: weighted_sum, add_difference и multiply. Это уже для тех кто знает зачем ему это. В мире Stable Diffusion такие мерджи - отдельное искусство, позволяющее получать авторские модели. С музыкой пока поле ещё совсем непаханное, но уже есть комьюнити-мерджи которые заметно круче базовых.
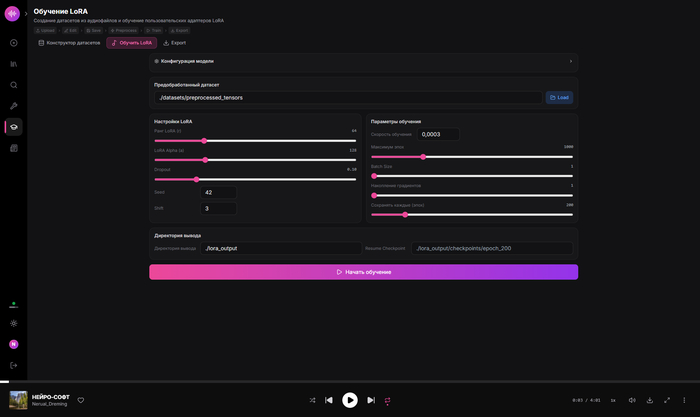
Bake LoRA - запекает веса LoRA в базовую модель, получая новый самодостаточный чекпоинт. Удобно когда сделал хорошую LoRA и хочешь использовать её всегда, не переключая.
Сэмплеры, шедулеры, CFG-пресеты
В базовом UI были базовые сэмплеры, я добавил ещё три - и три новых шедулера. В сумме теперь 10 сэмплеров (euler, heun, midpoint, ping-pong, a2s, bogacki, rk4, dopri5, deis, ipndm) и 7 шедулеров (linear, karras, cosine, beta, sway, logit_normal, laplace). Для каждой комбинации свои компромиссы между скоростью и качеством. Заодно починил баг где SDE-сэмплер выдавал шум вместо музыки, и залочил комбо для turbo-моделей - там работает только euler + linear, остальное крашится.
Отдельно - CFG scheduling presets. CFG (classifier-free guidance) - это параметр который говорит модели насколько строго следовать промпту. Обычно он константный. Но оказывается его можно расписать во времени - в начале генерации строже, к концу свободнее, или наоборот. Я добавил 5 пресетов подсмотренных в комьюнити: Default, Creative, Strict, Smooth, ADG. На моих тестах Smooth давал самые живые треки, но вкусовщина.
Two-stage cancel
Вот эта штука редко где реализована нормально. Жмёшь “Отмена” во время генерации - и реально останавливаешь, а не ждёшь минуту пока оно доделает. Первый этап - soft cancel через сигнал процессу. Второй этап - если процесс не реагирует второй клик отменяет генерацию.
Hot model swap
Меняешь модель - и тебе не надо перезапускать сервер. Когда я только прикрутил XL, переключение между моделями работало через рестарт сервера: хочу Turbo - перезапусти. Хочу SFT - перезапусти. Хочу другой LM для генерации текстов - угадайте что. Я переписал всю эту машинерию чтобы модели грузились/выгружались динамически. Отдельно DiT (сама музыкальная модель), отдельно LM (языковая для текстов). Можно отключить LM вообще и освободить VRAM для основной генерации через run-no-lm.bat.
Русский язык + починка i18n
В оригинале была i18n на 4 языка - английский, китайский, японский, корейский. Русского не было. Я добавил русский и заодно прошёл по фронту и вычистил все оставшиеся захардкоженные строки (в оригинале их было прям много - часть UI переведена, а часть просто на английском захардкожена). Все 750+ ключей теперь нормально переключаются между 5 языками.
Всякая VRAM-магия
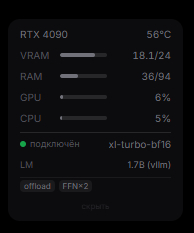
Добавил chunked FFN (feed-forward network считается кусочками - меньше памяти нужно единовременно), pinned memory для быстрой передачи между CPU и GPU, интеграцию с comfy-aimdo (оптимизированное внимание), CPU offload опционально через env var ACESTEP_OFFLOAD_TO_CPU=1. Это всё невидимое для юзера, но именно благодаря этому XL SFT стал запускаться на картах с 16 ГБ VRAM, а не только на 24 ГБ как было на старте.
Portable-установка одним батником
Это моя любимая тема по жизни. Оригинал ставился через setup.bat, который предполагал что у тебя уже есть Python, Node.js и CUDA нужной версии. Если чего-то нет - читай документацию, ставь сам, страдай. Нормальному человеку такое не дашь.
Я переписал установку чтобы ничего не требовалось заранее. install.bat сам скачивает портативный Python 3.12, портативный Node.js 22, нужную версию PyTorch под вашу CUDA (12.4 / 12.6 / 12.8 - выбор в начале), все зависимости. Ничего в систему не попадает. Вся папка самодостаточная. Скопировал на флешку - унёс на другой компьютер - всё работает. Удалил папку = деинсталлировал. Именно так я делаю все свои портативные сборки и считаю это единственным нормальным способом распространять ML-тулы для обычных пользователей.
Плюс run.bat, run-no-lm.bat, run-dev.bat, update.bat, reinstall.bat - каждый под свой сценарий, очевидный из названия ярлыка.
Виджет с потреблением ресурсов
Очень полезно следить за тем, сколько ресурсов потребляла система прежде чем все упало, я сделал минималистичный и симпатичный виджет в левом сайдбаре, где отображаются все основные жизненные показатели вашей системы.
❯ Честно про ограничения
Я обещал честно рассказывать про плюсы и минусы. Так что поехали минусы.
Это не Suno. И вряд ли в ближайший год станет. Качество заметно ниже, особенно когда речь про жанры с тонкой аранжировкой - классика, джаз, сложные электронные стили. ACE-Step XL очень уверенно делает “бодрые песни с вокалом” - поп, рок, электронику. Всё что требует тонкой нюансировки - пока нет.
Вокал местами синтетический. На коротких фразах - норм, на длинных куплетах инногда слышно что это не человек. Suno тут ушёл сильно вперёд.
Надо настраивать. Если вам нужно просто “нажал и получил” - это Suno за $10 в месяц. ACE-Step Studio - это инструмент для тех кто готов потратить время. Выбрать модель, подобрать сэмплер, покрутить CFG, поэкспериментировать с референсом. Кривая входа - часа два на то чтобы начать получать приличные результаты.
VRAM. Минимум 16 ГБ с BF16-моделью, но рекомендуется 20+. На встроенной графике ноутбука это не запустится.
Очень тупые, но забавные тексты. Они в рифму, но совершенно без смысла, к тому же модель плохо слушается промпта, на русском не понимает совсем, а на английском просто очень избирательно пишет лирику, если вы задаете её в промпте. Но, конечно, никто не мешает сгенерировать лирику, да и сам промпт для генерации музыки - в другой, более умной нейронке.
Нужно время на скачивание. Первый запуск скачивает 7.5 ГБ ( BF16-версия) или 18.8 ГБ (любая официальная XL). Плюс LM на генерацию текстов. В сумме полная установка - это около 20 ГБ на диск.
❯ Но есть ниши где опенсорс уделывает Suno
И вот тут интересно. Есть три сценария где ACE-Step Studio реально круче чем Suno - не “такое же”, а именно круче.
Каверы защищённых копирайтом треков. Suno жёстко режет любые попытки сделать кавер на известную песню. А у вас дома никого не волнует, что вы хотите послушать как “Smells Like Teen Spirit” звучал бы в стиле регги. Загрузил - получил - слушаешь. Для себя, не для публикации. Но в личной коллекции прикольных экспериментов - огонь.
Своя LoRA на любой трек. ACE-Step поддерживает LoRA из коробки. Можно обучить модель на любом треке. Это огромное пространство возможностей которое в закрытых сервисах в принципе недоступно. Я пока только начал в этом разбираться, но планирую отдельно про это написать - обучение LoRA для музыкальных моделей это своя тема.
Локальность и навсегда. Ни подписок, ни кредитов, ни лимитов, ни цензуры, ни “упс, сервис закрылся”. Скачал - работает. Тревожная мысль: как только какой-то SaaS-сервис становится мне важен, я сразу думаю “а что если он заавтра умрёт или поднимет цены в 5 раз”. С опенсорсом эта мысль не гложет. Что скачал - то твоё, и никто не отниимет.
Можно шарить по сети. Например зайти с телефона принимая ванну, ну или придумайте сами более достойный пример. Плюс есть система профилей, что отлично подойдет скажем для многодетной музыкальной семьи с GPU сервером на балконе.
Если будет мало, то в канале Нейро-Софт есть еще и архив с окружением под win 11, rtx 4090, подписывайтесь чтобы не пропускать портативки полезных нейросетей.
После установки открываете run.bat - браузер откроется автоматически. При первом запуске докачает модели.
❯ Опенсорс хочет вас
Это самая большая штука которую я когда-либо публиковал. И это уже сейчас работающий продукт - не демо, не proof-of-concept, а полноценная студия которой приятно пользоваться.
Но это опенсорс, и ему нужна ваша помощь. Области где я сам не дотянусь:
macOS и Linux-сборки - я писал под винду, Но оригинальный ACE-Step-1.5 работает и под mac и под Linux, нужно просто сделать сборку.
Новые пресеты визуализатора - это чистый HTML/Canvas, добавить пресет - часа на два работы
Переводы - если вы носитель языка которого ещё нет (немецкий, французский, испанский…) - берите i18n-файлы и вперёд
UI обучения LoRA - скелет есть, нужен нормальный пайплайн с прогресс-барами
Форкните, поправьте что не нравится, пришлите PR. Или создайте issue с идеей. Или напишите туториал. Или просто поставьте звезду на GitHub - чтобы другие нашли проект быстрее. Мне не сложно просить об этом, потому что это реально помогает проекту жить.
И главное - пришлите в комментарии треки которые нагенерите. Очень интересно послушать что из этого получается у других людей. В моей голове ACE-Step Studio это в первую очередь инструмент для творчества, а не ещё одна техно-игрушка. Покажите что вы делаете - это лучшая мотивация для меня продолжть пилить.
Как нейросети помогают реализовать творческий потенциал: создаём музыку и клип с помощью ИИ
Раньше для создания музыки и видеоклипов требовались годы обучения, дорогое оборудование и целая команда профессионалов. Сегодня с помощью нейросетей любой человек может реализовать свои творческие идеи — даже без специального образования. Не буду вас утомлять разновидностями нейронок, а просто расскажу как это получилось у меня:
Шаг 1. Пишем музыку с помощью музыкального ИИ
Взял понятную для себя нейронку SUNO
Шаг 2. Создаём клип с помощью визуального ИИ
Сгенерировал картинки в нейронке "Шедеврум" и каждую полученную картинку оживил в этой же нейросети. Лучше использовать общий промпт для генерации изображений (например: урбанистический стиль, улицы дворов, идет дождь), чтобы после обьединения полученных фрагментов клип получился цельным и с общей атмосферой.
Шаг 3. Объединяем музыку и видео
Когда у вас есть трек и набор визуальных материалов, остаётся собрать всё в единый клип. Для этого можно использовать любой видеоредактор, например: CapCut или InVideo
Итог:
Нейросети — это мощный помощник для самореализации. Попробуй создать свою первую песню и клип с помощью ИИ — возможно, это станет началом нового творческого пути!
Нейросеть создать песню: генератор музыки ИИ бесплатно — 5 советов, как написать текст, который нейросеть не «зажует»
Еще совсем недавно идея за несколько минут создать песню без студии, музыкантов, аранжировщика и долгих часов записи казалась фантастикой. Сегодня это рабочий сценарий: пользователь открывает сервис, вводит текст, задает настроение, стиль, темп — и получает трек, который можно слушать, дорабатывать, пересобирать и публиковать. Именно поэтому запросы вроде нейросеть создать песню, создать песню онлайн, создать песню ИИ и песня нейросеть создать онлайн перестали быть редкостью. Люди хотят не просто поиграть с технологией, а получить понятный инструмент для реального музыкального результата.
Но очень быстро выясняется неприятная вещь: далеко не любой текст хорошо поется. Даже если сервис умеет создать песню с помощью нейросети, он не обязан превратить слабый или перегруженный текст в убедительную композицию. Нейросеть может «съесть» окончания, смазать ритм, спутать акценты, проглотить важную строчку, странно растянуть слово или сделать так, что припев звучит блекло. Именно поэтому многим кажется, что ИИ “поет как-то не так”, хотя проблема часто не в модели, а в исходном материале.
Если ваша цель — не просто попробовать технологию, а действительносоздать песню с помощью нейросети онлайн, нужно понимать главный принцип: музыкальная нейросеть лучше работает не с любым текстом, а с текстом, который подготовлен под пение. Это особенно важно, если вы хотите создать русскую песню, получить песни созданные нейросетью русские, быстро создать песню онлайн на русском и при этом сохранить понятную дикцию, цепкий припев и живую подачу. Для русского языка это критично: длинные слова, сложные окончания, плотные согласные и подвижные ударения легко ломают вокальную линию.
Нейросеть создать песню: генератор музыки ИИ бесплатно
В этой статье разберем, как искусственный интеллект создать песню помогает на практике, почему одни тексты ИИ поет легко, а другие «зажевывает», какие функции дают современные сервисы, чем отличается создать песню с помощью текста от обычной генерации, как подготовить слова так, чтобы нейросеть их не уничтожила на вокале, и какие 5 приемов реально помогают получить трек, который звучит как песня, а не как неудачный эксперимент.
Почему нейросеть «зажевывает» текст в песне
Когда пользователь впервые пробует создать песню на стихи или создать песню по тексту, он часто думает так: если модель умеет писать музыку, значит, она автоматически справится и с любым текстом. Но музыкальная генерация работает иначе. Сервису нужно одновременно решить несколько задач: придумать мелодию, удержать ритм, подобрать гармонию, разложить слоги по долям, распределить акценты и еще вписать слова в музыкальную форму. Именно на этой стыковке и возникает большинство проблем.
Нейросеть начинает «жевать» текст в пяти типовых случаях. Первый — в строке слишком много слогов. Второй — слова плохо ложатся на доли и конфликтуют с ритмом. Третий — в тексте слишком много сложных сочетаний согласных. Четвертый — фраза написана как литературное предложение, а не как певучая строка. Пятый — пользователь перегружает песню смыслами, забывая, что в музыке важна не только мысль, но и вокальная удобность.
Вот почему даже если сервис умеет создать свою песню со словами, создать песню онлайн ИИ или работает как создать песню приложение, результат может получиться рыхлым на вокале. ИИ не “ленится”. Он просто пытается уложить неудобный текст в музыкальную форму. И если словесная конструкция сопротивляется пению, модель начинает жертвовать четкостью дикции, логикой акцентов или естественностью фразировки.
Особенно заметно это, когда хотят создать песню на русском языке или создать песню через нейросеть онлайн на длинных, сложных, литературных куплетах. Русский язык очень красив для песен, но он не прощает перегруза. В английском короткие слова легче садятся в ритм. В русском — нет. Поэтому текст под нейросетевую песню нужно писать с учетом вокальной механики, а не только смысла.
Что вообще умеет современный генератор песен и музыки
Важно сразу развести два сценария. Первый — когда пользователь хочет создать музыку без слов. Второй — когда нужно именно создать песню через ИИ, то есть трек с вокалом, текстом и структурой песни. Внутри сервисов это разные уровни сложности.
Обычно современный бот создающий песни или сервис генерации умеет:
создавать музыкальную основу по описанию жанра и настроения;
генерировать вокальную линию;
раскладывать текст по форме куплет — припев — бридж;
подбирать темп, тональность, динамику;
делать создать песню ai в заданном стиле: поп, рок, инди, рэп, synthwave, cinematic, lo-fi;
принимать собственный текст пользователя;
создавать инструментал отдельно от песни;
менять степень вокальной выразительности;
иногда — генерировать несколько вариантов одного трека.
Поэтому если вы хотите создать песню нейросеть со своим текстом, создать готовую песню или хотя бы создать мелодию песни онлайн, нужно понимать, какую именно часть вы отдаете ИИ. Текст? Музыку? Вокал? Все вместе? От этого зависит и результат, и требования к исходным словам.
То же касается более широких сценариев: создать музыку бесплатно, создать видео с музыкой, создать фото с музыкой, создать музыку онлайн бесплатно. Многие сервисы умеют работать не только с песнями, но и с музыкальными фонами, битами, аранжировочными заготовками, инструменталами. Но когда появляется человеческий голос, требования к тексту резко растут. Именно тогда становится видно, насколько хорошо вы подготовили слова.
Чем песня для нейросети отличается от обычного стихотворения
Это одна из самых важных мыслей. Не каждый хороший стих — хорошая песня. И не каждый сильный литературный текст хорошо поется. Часто пользователь пишет очень плотные, образные, красивые строки, а потом удивляется, почему ИИ превращает их в смазанный вокальный поток.
Причина в том, что песня — это не просто рифмованный текст. Это музыкальная конструкция, в которой каждое слово должно удобно лечь на ритм, на дыхание, на вокальную длину гласных, на музыкальную фразу. Поэтому когда вы хотите музыка создаваемая нейросетями в песенном формате, думайте не как поэт, а как автор текста для исполнения.
Хороший текст для нейросети обычно:
короче, чем кажется нужным;
проще синтаксически;
чище по ударениям;
богаче на гласные, чем на тяжелые скопления согласных;
повторяем в припеве;
ритмически предсказуем внутри строфы;
легко произносится вслух.
Вот почему, когда вы хотите создать музыку нейросеть, создать музыку ИИ или ИИ музыка создать бесплатно, очень полезно сначала прочитать текст вслух и попробовать напеть его на любой простой ритм. Если вы сами спотыкаетесь, нейросеть почти наверняка тоже “зажует” строчку.
Какой текст нейросеть поет лучше всего
Лучше всего поются тексты, в которых есть ясная вокальная архитектура. Это не обязательно примитивные слова и не обязательно попсовый шаблон. Но в них должна быть певучесть.
Обычно ИИ проще всего работает с такими строками:
короткими;
симметричными по длине;
с понятным ударением;
с открытыми гласными на концах;
без перегруженных оборотов;
без слишком длинных существительных и причастных цепочек;
с повтором ключевых слов в припеве.
Если пользователь хочет искусственный интеллект создать музыку под готовый текст, создать музыку с помощью нейросети или создать музыку нейросеть онлайн, лучший материал — это не “идеальная поэзия”, а хорошо поющийся текст. Тот, который уже в сыром виде несет ритм.
Именно поэтому, когда ищут создать музыку нейросеть онлайн бесплатно, создать музыку с помощью ИИ и создать музыку и сохранить, чаще всего выигрывают тексты, где меньше литературного блеска и больше музыкальной логики. В песне это не минус, а плюс.
5 советов, как написать текст, который нейросеть не «зажует»
Ниже — основная практическая часть статьи. Это не абстрактные рекомендации, а рабочие принципы, которые резко повышают шанс получить внятный, слушабельный вокальный результат.
Совет первый: пишите строками, а не абзацами
Главная ошибка — писать куплет как мини-рассказ. Пользователь думает о содержании, но забывает о дыхании и длительности фразы. Нейросеть видит длинное предложение и пытается распределить его по музыкальной линии. В результате ударения уезжают, смысловые акценты ломаются, а вокал становится смазанным.
Если хотите создать музыку без слов, эта проблема не критична. Но если цель — создать инструментальную музыку или именно вокальную песню со словами, строка должна быть короткой и самостоятельной. Лучше 8–10 простых слов, чем 20 слов со сложной пунктуацией.
Плохой вариант:
“Я снова возвращаюсь туда, где шум дождя когда-то заглушал мои сомнения и заставлял поверить, что все еще возможно”.
Лучше:
“Я снова здесь. И дождь шумит. И будто шепчет: все еще звучит”.
В таком формате приложение где создают музыку, создать музыку ИИ онлайн бесплатно или ai создать музыку справляются заметно лучше. Потому что каждая строка уже похожа на вокальную единицу.
Это же касается сценариев создать музыку бесплатно на русском, нейросеть создает музыку по тексту, приложения создавать музыку бесплатно и создать музыку биты с последующей вокальной надстройкой. Чем яснее строка, тем лучше ее поет модель.
Совет второй: давайте гласным “место для пения”
Песня любит гласные. Длинные вокальные ноты лучше держатся на открытых звуках, а не на плотных цепочках согласных. Если строка заканчивается словом, которое трудно тянуть, нейросеть часто проглатывает конец, смазывает дикцию или странно ломает фразу.
Поэтому при работе над текстом полезно обращать внимание на вокальную мягкость. Хорошо поются слова, где можно вытянуть “а”, “о”, “е”, “у”, иногда “и”. Сложнее — слова, которые заканчиваются на жесткие согласные или содержат тяжелые склейки.
Это особенно важно, когда вы хотите создать рок музыку, используете генерация музыки, ищете нейросеть для генерации музыки, ИИ для генерации музыки и генерация музыки онлайн. В роке и энергичных жанрах текст тоже можно сделать плотным, но даже там сильные вокальные точки почти всегда держатся на хорошо тянущихся звуках.
Если фраза не поется, попробуйте заменить одно слово на более вокальное. Иногда это меняет все. Вместо “всплеск” — “волна”. Вместо “крах” — “падение”. Вместо “мгла” — “темнота”, если ритм позволяет. Это не про упрощение смысла, а про понимание того, как генерация музыки нейронная сеть обрабатывает вокал.
Совет третий: делайте припев проще, чем куплет
Многие новички стараются “улучшить” припев и делают его самым сложным местом в песне. На практике работает наоборот. Именно припев должен быть легче всего для пения, запоминания и повторения. Если нейросеть поет ваш куплет приемлемо, но припев выходит рыхлым, причина часто в том, что вы перегрузили его словами и образами.
Хороший припев должен быть:
короче куплета;
ритмически проще;
повторяем;
понятен с первого прослушивания;
вокально удобен;
построен на сильной эмоциональной фразе.
Это правило особенно важно, если вы используете нейросеть для генерации музыки по тексту, русские нейросети для генерации музыки и генерация музыки и песен. В русском языке сложный припев быстро распадается. А вот простой, но цепкий — работает отлично.
Совет четвертый: повтор — это не слабость, а музыкальный инструмент
Литературная логика часто учит нас избегать повторов. В песне все иначе. Повтор — один из самых сильных музыкальных механизмов. Именно он помогает нейросети удерживать структуру, а слушателю — запоминать трек.
Если вы хотите генератор музыки и звуков, ИИ генератор музыки онлайн, ИИ музыка, создать музыку ИИ и ИИ для создания музыки в песенном сценарии, не бойтесь дублировать ключевые слова. Особенно в припеве, в начале строк и в эмоциональных точках.
Например, слабый вариант припева:
“Я иду туда, где меня встретит иной горизонт и новая история”.
Сильнее:
“Я иду. Я иду. Туда, где свет. Я иду. Я иду. Туда, где нет моих вчерашних бед”.
Да, это проще. Но именно это лучше ложится в музыка с помощью ИИ. В песне повтор работает как ритм, как крючок и как опора для модели.
Совет пятый: сначала прочитайте текст вслух, потом попробуйте пропеть на одном ритме
Это самый недооцененный прием. Прежде чем отправлять слова в сервис, прочитайте их вслух в обычном темпе, а потом попробуйте произнести их на условный размер — хоть под счет, хоть под хлопок, хоть под любой бит. Если строка ломается, застревает или вызывает ощущение “тут бы надо переделать”, значит, нейросеть почти наверняка тоже споткнется.
Особенно это важно, если вы хотите создать музыку с помощью ИИ, ИИ музыка на слова, музыка ИИ создать онлайн и написать музыку с помощью ИИ именно с вашим текстом. Технология может многое, но она не заменяет элементарную проверку на поющуюся форму.
На практике этот тест сразу показывает:
слишком ли длинная строка;
куда падает естественное ударение;
где сбивается дыхание;
какие слова хочется заменить;
где нужен повтор;
какая фраза должна быть припевной.
Если вы делаете это хотя бы один раз перед генерацией, качество финальной песни растет заметно.
Какой формат текста лучше всего подходит для генерации песни
Музыкальным нейросетям обычно легче работать с уже размеченной структурой. Поэтому если вы хотите ИИ для генерации песен, лучше подавать материал в простой песенной логике.
Рабочий формат:
куплет 1;
припев;
куплет 2;
припев;
бридж;
финальный припев.
При этом каждая секция должна быть понятна не только вам, но и модели. Не нужно делать абзацы по 12 строк без внутренней логики. Лучше короткие, одинаково оформленные блоки.
Именно так нейросеть для генерации песен на русском и генерация музыки и песен обычно работают лучше всего. У модели есть понятный каркас, и она легче строит музыкальную форму.
Как писать припев, который нейросеть подхватит с первого раза
Если говорить совсем практично, то хороший припев для ИИ обладает четырьмя свойствами:
короткие строки;
минимум сложных слов;
ключевая фраза повторяется;
сильная эмоция ясна без расшифровки.
Допустим, вы хотите ИИ для генерации песен по тексту или нейросеть для генерации песни онлайн с припевом, который запоминается. Тогда лучший вопрос звучит не “насколько красиво это написано?”, а “насколько легко это можно спеть два раза подряд и не потерять силу?”.
Плохой припев часто слишком литературный. Хороший — почти всегда немного проще, чем автору хотелось бы. Но именно это делает его музыкальным.
Что делать, если у вас уже есть стихотворение
Многие приходят к музыкальным нейросетям с готовыми стихами. И это нормальный сценарий. Но если ваша цель — генератор песен нейросеть и генератор песен онлайн, то стихотворение почти наверняка придется адаптировать.
Что обычно нужно изменить:
сократить длинные строки;
убрать сложные инверсии;
сделать яснее припев;
выделить повторяемый крючок;
заменить слишком тяжелые слова;
разбить длинную мысль на две музыкальные строки;
упростить пунктуацию и синтаксис.
Какой жанр легче всего подхватывает текст
Жанр тоже имеет значение. Один и тот же текст может плохо лечь в энергичный поп, но хорошо сработать в инди, лоу-фай или речитативно-мелодическом формате.
Обычно легче всего поются тексты в таких жанрах:
поп;
инди-поп;
synth-pop;
мягкий рок;
singer-songwriter;
dream pop;
melodic rap;
lo-fi vocal.
Сложнее — в очень плотных, быстрых или жанрово агрессивных форматах, если текст сам по себе перегружен. Поэтому, если вы хотите генератор песни на русском языке, создать песню ИИ генератор, лучше не начинать с самой тяжелой музыкальной формы. Возьмите жанр, где слова слышны.
Особенно это актуально для русского языка. В русскоязычной песне четкая дикция и понятный припев часто важнее, чем экстравагантный продакшн.
Как писать текст, если вы хотите именно русскую песню
Русский язык предъявляет свои требования. В нем много длинных слов, сложных окончаний и плотных согласных. Но именно поэтому русская песня может звучать глубже и эмоциональнее, если правильно подготовить текст.
Чтобы ИИ для создания песен, ИИ песни онлайн, песня через ИИ и ИИ песня на стихи справлялись лучше, полезно:
избегать слишком длинных канцелярских слов;
следить за ударением в каждой строке;
использовать сильные, понятные глаголы;
не перегружать строку существительными;
оставлять пространство для тянущихся гласных;
делать припев проще куплета;
проверять слова на произносительность вслух.
Это и есть база для тех, кто хочет ИИ пишущий песни, тестирует генерация музыки Чат GPT или генерация музыки Chat GPT как концепт. Хорошая песня для ИИ начинается с человечески удобного текста.
Что делать, если нейросеть все равно «жует» слова
Даже хороший текст иногда звучит неидеально. Это нормально. В таком случае не нужно сразу менять сервис или думать, что технология не работает. Чаще всего помогает один из пяти ходов.
Первый — сократить строку на 20–30%. Второй — заменить два-три трудных слова на более певучие. Третий — разбить одну длинную строку на две. Четвертый — упростить припев. Пятый — сменить жанр или темп.
Иногда проблема не в словах, а в слишком быстром BPM. Иногда — в том, что строчка хорошо звучит как текст, но плохо тянется как мелодия. Поэтому если вы хотите создать песню, не относитесь к первой генерации как к финалу. Это черновик, который показывает, где текст сопротивляется музыке.
Практический шаблон текста, который обычно хорошо поется
Ниже — упрощенный каркас, с которого можно начинать.
Куплет 1
Я шел туда, где гаснет свет И день уходит без следа Но в тишине услышал вдруг Что ты все так же ждешь меня
Припев
Верни меня, верни меня Туда, где дышит тишина Верни меня, верни меня Туда, где снова есть весна
Куплет 2
Я столько слов не досказал Я столько дней терял впустую Но если слышишь этот звук Я снова выберу живую
Это не шедевр, а именно каркас. Но он показывает, почему нейросеть обычно лучше поет такие тексты: короткие строки, простые ударения, повтор, гласные в концах, ясный припев.
Как использовать ИИ не вместо автора, а вместе с ним
Лучший результат почти всегда дает связка, где человек отвечает за смысл, а ИИ — за музыкальную упаковку, аранжировочную идею и вокальную интерпретацию. То есть не “пусть нейросеть все придумает”, а “я дам материал, который ей удобно петь”.
Именно в этом сценарии реально раскрываются возможности тех, кто хочет создать песню онлайн, создать песню с помощью нейросети, создать песню со своим текстом, создать музыку по тексту и получать не просто забавный эксперимент, а usable-трек.
ИИ здесь — не маг, а ускоритель. Он может дать форму, настроение, гармонию, тембр, стиль, но по-настоящему сильный вокальный текст все еще начинается с человеческого понимания ритма слова.
FAQ
Почему нейросеть «жует» русский текст в песне?
Чаще всего потому, что текст слишком длинный, перегруженный или плохо ложится на музыкальный ритм. В русском языке это особенно заметно из-за сложных окончаний, длинных слов и подвижных ударений.
Можно ли просто вставить стихотворение и получить хорошую песню?
Иногда — да, но чаще стихотворение нужно адаптировать под пение. Песня требует более коротких строк, понятной структуры, повторяемого припева и вокально удобных слов.
Что важнее для хорошей AI-песни: музыка или текст?
Если речь о песне со словами, текст критически важен. Даже сильный генератор может испортить слабый или неудобный для пения текст. Хороший материал заметно повышает качество результата.
Какой жанр лучше всего подходит для первого эксперимента?
Для старта обычно легче работают поп, инди-поп, singer-songwriter, мягкий рок и melodic rap. В них текст чаще сохраняет читаемость и понятность.
Можно ли создать русскую песню, которая звучит естественно?
Да, можно. Но для этого текст нужно писать именно под русский вокал: короткими строками, с ясными ударениями, певучими окончаниями и простым, сильным припевом.
Заключение
Сегодня создать песню с помощью нейросетей — уже не экзотика, а нормальный творческий инструмент. Пользователи хотят создать песню с помощью нейросетине ради эффекта “вау”, а ради реального трека, который можно слушать.
Но качество результата почти всегда упирается в текст. Именно поэтому, если вы хотите создать свою песню со словами, нужно писать не просто красиво, а музыкально. Именно в песенном сценарии особенно видно: нейросеть может придумать много, но она не обязана спасать неудобный текст. Поэтому лучший путь — не ждать, что ИИ сам “разрулит” каждую строку, а дать ему материал, который уже написан под музыку. Тогда и генерация песен, и нейросеть для генерации песен, и генератор песен онлайн перестают быть просто технологическим фокусом и превращаются в полноценный инструмент для автора. А это значит, что вместо “зажеванной” вокальной каши вы получаете песню, которая звучит, запоминается и действительно работает как музыка.