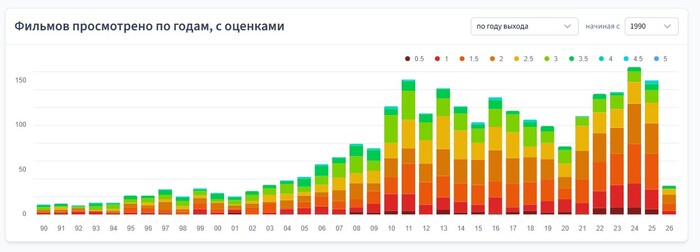
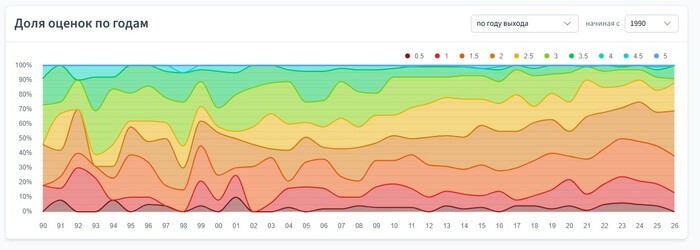
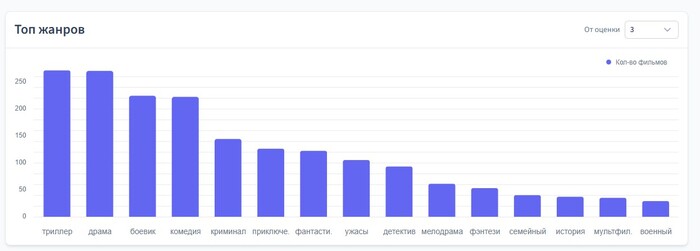
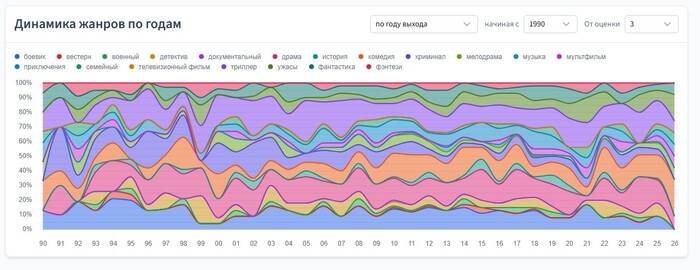
Разработка на Java без всего
Снова показываю как вести разработку «голыми руками» — без IDE, документации и даже интернета. На этот раз с помощью «пользовательской» Ubuntu Linux и OpenJDK.

Поскольку современные разработчики постоянно жалуются на завышенные требования технических интервью вообще и на мою «дурную практику» написания кода от руки в частности — показываю на личном примере как все это работает.
Жертвам «слабой памяти» посвящается.
Заодно узнаете как можно вести разработку на Java хоть в чистом поле — в самолете, в поезде или на закрытом объекте, без подключения к интернету и документации.
Видео
На этот раз для большего угара помимо статьи было записано и видео, где показан весь процесс «полевой разработки» на Java, с одним только JDK:
Тестовое окружение
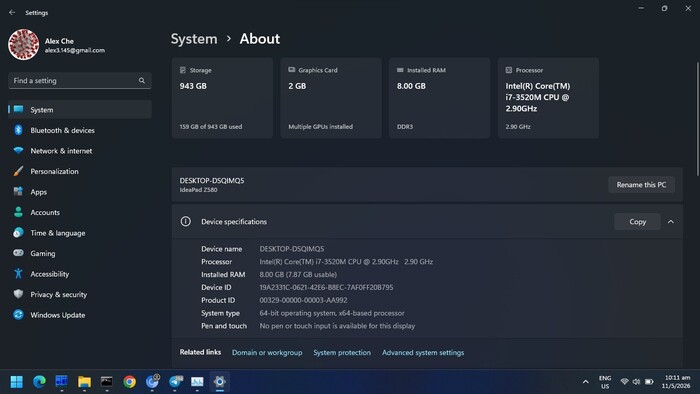
Для большей чистоты эксперимента был взят Live-образ Ubuntu Desktop 24.04.3 LTS, записан на флешку, флешка вставлена в один из рабочих ноутбуков, который затем с нее был загружен.
Таким образом получилась абсолютно чистая система, без средств разработки и с отключенной сетью.
Из инструментов у нас будет лишь текстовый редактор и JDK.
И все.
Что будем писать
Самое простое что можно написать в таких полевых условиях — реверс-шелл HTTP-сервер. На самом деле написать можно много чего, особенно если посмотреть в каталог demo внутри OpenJDK:
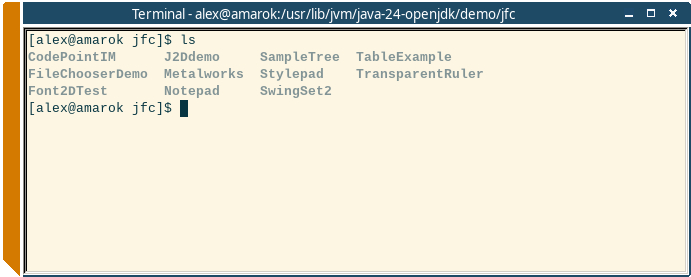
Набор демо-проектов из состава OpenJDK 24
Здесь и далее скриншоты из другой системы (Manjaro), чтобы не заморачиваться с их перебрасыванием из Live-системы и добавлением в статью. Тем не менее на видео все описываемые в статье шаги и весь код вбиваются каноничным способом — полностью вручную, на чистой системе, загруженной с Live USB.
Демо
Упомянутый выше каталог demo содержит набор довольно серьезных примеров проектов, которых вам вполне хватит для начальной стадии изучения или в качестве основы для какого-нибудь прототипа, особенно если никаких других инструментов и интернета — нет.
Так выглядит демо-проект Notepad, реализующий простейший текстовый редактор:
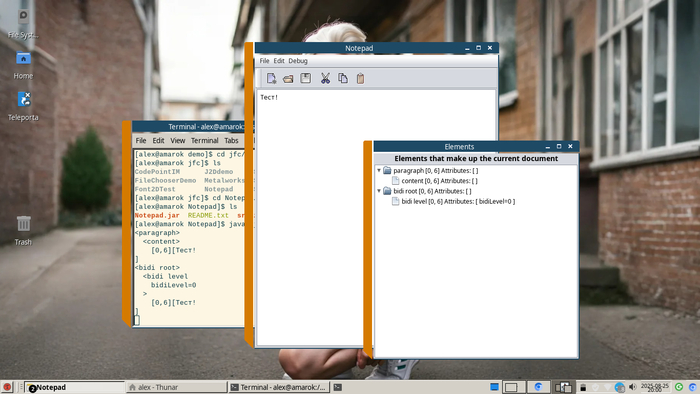
Окно отладки справа — часть демо‑проекта.
Так выглядит демо Metalworks, с простейшей реализацией мульти-оконной системы (MDI):
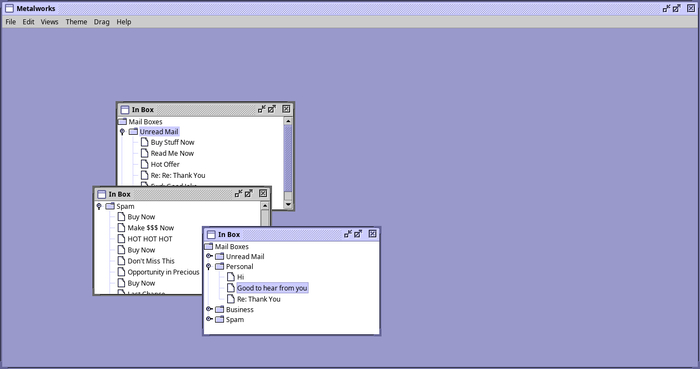
Обратите внимание на меню Theme, даже у демо-проекта есть скины!
Напоминаю, что вся эта благодать находится внутри стандартной поставки любой версии JDK, начиная с незапамятных времен 8й версии.
Все демо-проекты содержат исходный код в архивах src.zip и собираются без внешних зависимостей.
К сожалению каталог с демо иногда вырезается ментейнерами дистрибутивов линукса ради экономии места и переносится в отдельный пакет, который пользователи разумеется забывают установить.
Ручная разработка
В ролике в записи показано как автор последовательно вводит и запускает в работу примерно такой код:
// разумеется я не помню названий абсолютно всех
// импортируемых классов, поэтому тут стоит '*'
import java.io.*;
import java.net.*;
import java.util.concurrent.*;
public class MyWebServer {
static void handle(Socket s) {
// метод getId() устарел, поэтому его использование в
// последних версиях JDK выдает предупреждение
System.out.println("Thread: %d"
.formatted(Thread.currentThread().getId()));
// самое сложное место, которое удалось повторить на записи
// далеко не с первой попытки
try(PrintWriter out = new PrintWriter(s.getOutputStream());
BufferedReader in = new BufferedReader(
new InputStreamReader(s.getInputStream()));) {
// поскольку используется чтение и запись строк а не байт - читаем
// строку целиком, т.е. до символа \n
String l = in.readLine();
// тут просто показываем в консоль
System.out.println(l);
// этим простым способом читаем только строку запроса,
// которая идет первой, пропустив все заголовки
// \r\n (пустая строка) - признак завершения запроса
while (l==null || l.isEmpty() || "\r\n".equals(in.readLine()));
// тут мы 'в лоб' сравниваем строку HTTP-запроса целиком
// так она выглядит до работы парсера
if ("GET /test HTTP/1.1".equals(l)) {
// поскольку мы реагируем только на один url '/test'
// формируем ниже статичный ответ
String data = "Hello from alex0x08 at "+ new Date();
// так выглядят стандартные поля ответа в 'raw' виде, без обработки
out.println("HTTP/1.1 200 OK");
// 'close' дает указание браузеру разорвать соединение
// с сервером сразу после получения данных
out.println("Connection: close");
// поскольку мы отдаем строку - ставим MIME тип 'text/plain'
out.println("Content-Type: text/plain");
// опционально отдаем размер данных
out.println("Content-Length: " + data.length());
// пустая строка - признак начала блока с данными
out.println();
// отдаем сами данные
out.println(data);
} else {
// во всех остальных случаях формируем ответ 404
out.println("HTTP/1.1 404 Not Found");
out.println("Connection: close");
out.println();
}
// нужно обязательно вызывать поскольку PrintWriter кеширует данные
out.flush();
} catch (Exception e) {
e.printStackTrace();
} finally {
// в любом случае закрываем клиентский сокет
try {s.close();} catch (Exception ee) {}
}
}
// стартовый метод приложения
public static void main(String[] args) throws Exception {
System.out.println("Starting..");
// тоже сложное место, которое было непросто ввести по памяти
ExecutorService p = Executors.newFixedThreadPool(10);
// создание 'серверного' сокета, который будет прослушивать
// указанный порт
// поскольку хост не указан - будут прослушиваться все (0.0.0.0)
ServerSocket ss = new ServerSocket(8089);
// бесконечный цикл, который нужен тк метод accept() - блокирующий
// и выход из него произойдет после получения входящего подключения
while (true) {
// получен клиентский сокет
Socket s = ss.accept();
// запуск асинхронной обработки
p.execute(() -> handle(s));
}
}
}
Комментариев в той версии кода, который был показан на записи разумеется нет, они были добавлены уже после — для большего понимания.
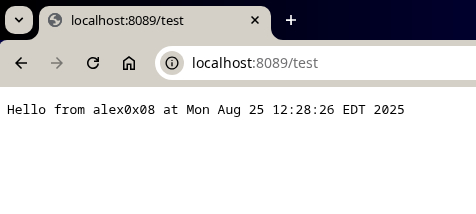
Данный исходный код реализует простейший многопоточный веб-сервер на Java, который отвечает лишь на один URL /test и отдает заранее заданную строку с датой.
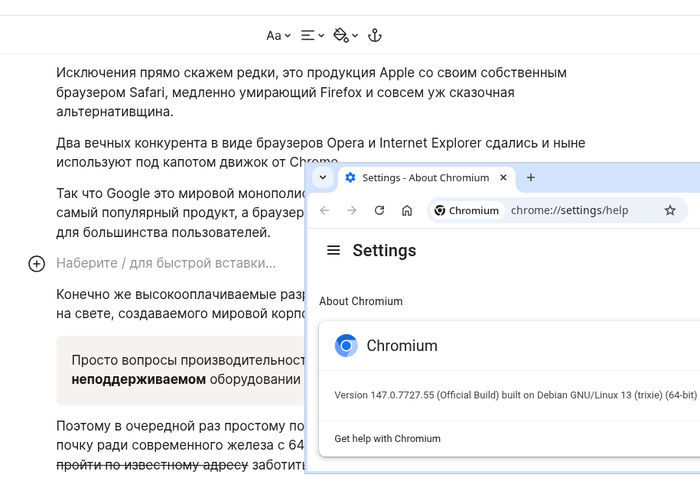
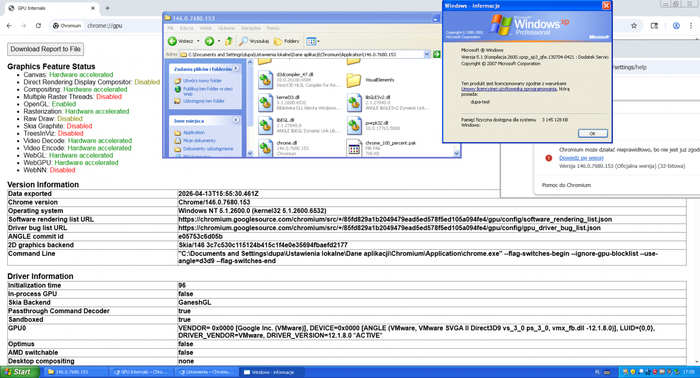
Как видите даже столь небольшого количества строк достаточно, чтобы можно было подключиться из современного браузера Chrome:
Компиляция выполняется как и в записи всего одной командой:
javac -cp . MyWebServer.java
После чего появится один единственный class-файл c совпадающим именем. Поскольку пакеты не использовались, для запуска достаточно указать в качестве classpath текущий каталог:
java -cp . MyWebServer
Но это все лирика и понты.
Когда кончается человеческая память
Разумеется невозможно запомнить абсолютно все и рано или поздно вы столкнетесь с названием метода или класса, которые надо где-то подсмотреть.
Для примера, автор при записи видео столкнулся с таким в двух местах:
длинные классы-обертки над потоками (stream) сокета и сложное название статичного метода, создающего экземпляр ExecutorService.
И то и другое получилось правильно ввести далеко не с первой попытки.
Возвращаясь к ситуации когда нет доступа к интернету и полноценной среды разработки, зато на машине есть JDK — показываю что можно сделать в этом непростом случае.
Невероятно но факт:
подсмотреть названия системных классов и методов можно.. в самом JDK!
Вот это поворот!
В последних версиях JDK появилась интересная утилита jimage, которая находится в каталоге bin (там же где и главные бинарники java и javac).
С помощью этой штуки можно легко посмотреть полные названия всех системных классов:
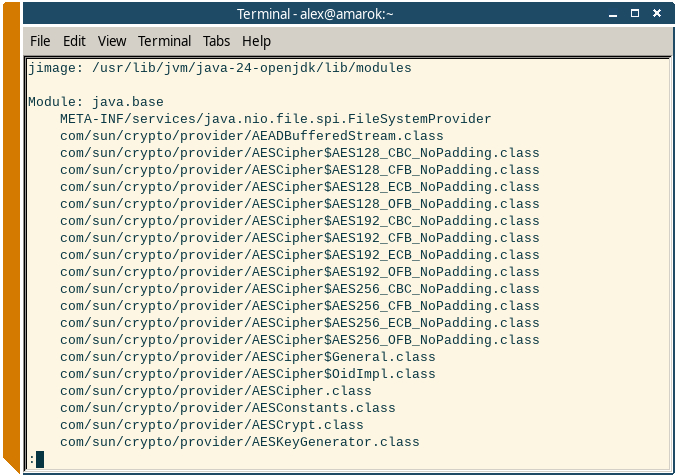
Листинг системных классов JDK с полными именами.
Правда знание полного имени класса не всегда помогает, поскольку в JDK много вложенных системных классов, которые по идее вызывать снаружи не надо.
Команда для запуска:
jimage list $JAVA_HOME/lib/modules |less
Где переменная JAVA_HOME указывает на каталог с установленной JDK:
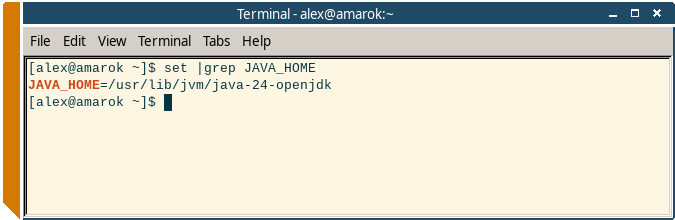
Так вы увидите названия всех системных классов, но что делать с методами?
Вытаскиваем сигнатуры методов
Тут тоже есть решение, поскольку эта же самая утилита позволяет распаковывать jmod-файлы в которых находятся системные классы JDK:
jimage extract --dir=/opt/src/tmp $JAVA_HOME/lib/modules
А еще одна утилита javap позволяет посмотреть метаданные class-файла, в том числе сигнатуры всех методов:
cd /opt/src/tmp/jre
javap java.base/java/nio/Bits.class
Так выглядит результат:
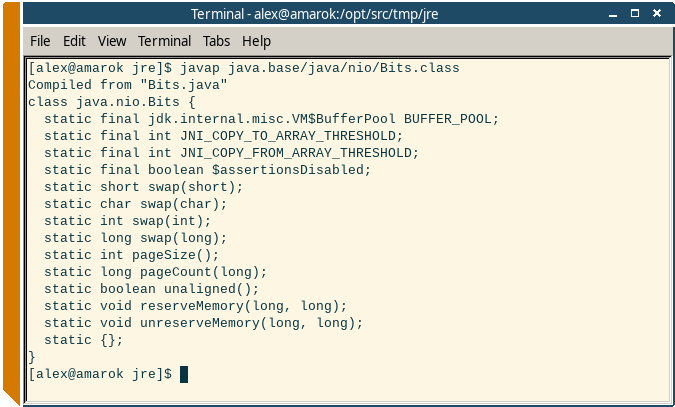
Вот этого уже с запасом хватит для полевой разработки в условиях крайнего Севера.
Если у вас есть реальный, не "нарисованный" опыт разработки на Java, двух этих трюков будет достаточно для работы в поезде или самолете или на чужом компьютере — в тех местах и обстоятельствах, где нет подготовленного рабочего места.
Исходники JRE
Если вам совсем повезет, в каталоге JDK/lib будет находиться файл src.zip, внутри которого будут исходники всех системных классов JRE:
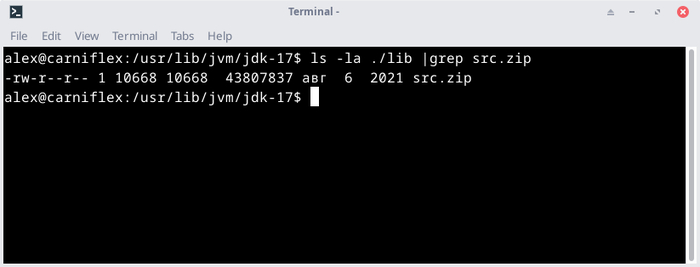
«Повезет» — потому что также как и demo, этот файл часто удаляют ментейнеры дистрибутивов Linux, с переносом в отдельный пакет. Но разумеется если он присутствует, то поможет гораздо больше чем все приседания с javap.
В распакованном виде:
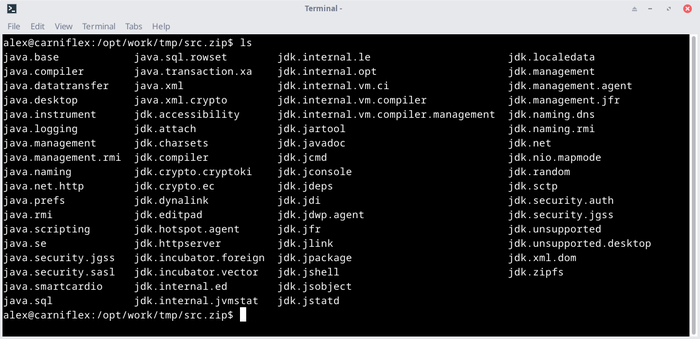
Внутри находится исходный код всех классов Java, используемых в JDK:
cat java.base/java/io/Bits.java |less
Для примера, так выглядит исходный код класса java.io.Bits, который мы просматривали выше с помощью javap:
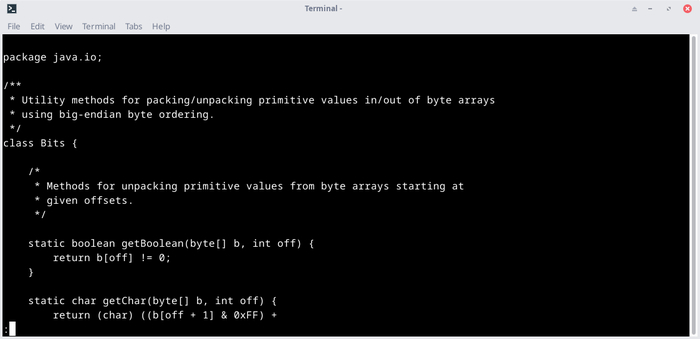
Как видите тут есть все, включая комментарии.
Эпилог
Смысл такой «полевой разработки» — в первую очередь глумеж над джунами проверка реальных практических навыков, которые находятся в голове у программиста, а не где‑то в интернете. К сожалению ныне можно констатировать, что такие навыки являются большой редкостью и мало кто из кандидатов, которых я когда-либо собеседовал могли осилить написание хотя‑бы трети подобного кода.
Кстати в нашем Телеграм-канале выложено первое техническое видео, где впервые получилось проверить всю эту идею.
Статья была опубликована на Хабре, более вольный оригинал статьи как обычно в нашем блоге.