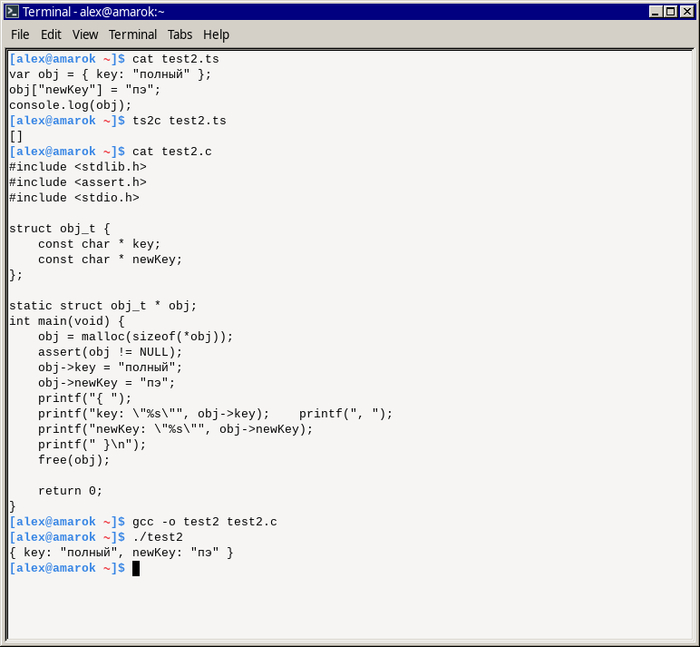
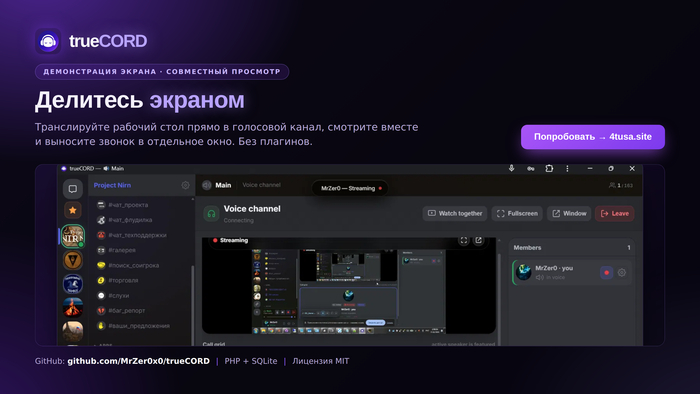
Снова показываю как вести разработку «голыми руками» — без IDE, документации и даже интернета. На этот раз с помощью «пользовательской» Ubuntu Linux и OpenJDK.
Поскольку современные разработчики постоянно жалуются на завышенные требования технических интервью вообще и на мою «дурную практику» написания кода от руки в частности — показываю на личном примере как все это работает.
Жертвам «слабой памяти» посвящается.
Заодно узнаете как можно вести разработку на Java хоть в чистом поле — в самолете, в поезде или на закрытом объекте, без подключения к интернету и документации.
Видео
На этот раз для большего угара помимо статьи было записано и видео, где показан весь процесс «полевой разработки» на Java, с одним только JDK:
Для большей чистоты эксперимента был взят Live-образ Ubuntu Desktop 24.04.3 LTS, записан на флешку, флешка вставлена в один из рабочих ноутбуков, который затем с нее был загружен.
Таким образом получилась абсолютно чистая система, без средств разработки и с отключенной сетью.
Из инструментов у нас будет лишь текстовый редактор и JDK.
И все.
Что будем писать
Самое простое что можно написать в таких полевых условиях — реверс-шелл HTTP-сервер. На самом деле написать можно много чего, особенно если посмотреть в каталог demo внутри OpenJDK:
Набор демо-проектов из состава OpenJDK 24
Здесь и далее скриншоты из другой системы (Manjaro), чтобы не заморачиваться с их перебрасыванием из Live-системы и добавлением в статью. Тем не менее на видео все описываемые в статье шаги и весь код вбиваются каноничным способом — полностью вручную, на чистой системе, загруженной с Live USB.
Демо
Упомянутый выше каталог demo содержит набор довольно серьезных примеров проектов, которых вам вполне хватит для начальной стадии изучения или в качестве основы для какого-нибудь прототипа, особенно если никаких других инструментов и интернета — нет.
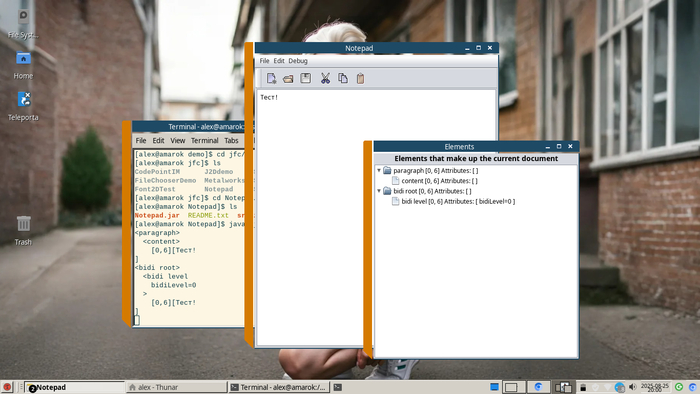
Так выглядит демо-проект Notepad, реализующий простейший текстовый редактор:
Окно отладки справа — часть демо‑проекта.
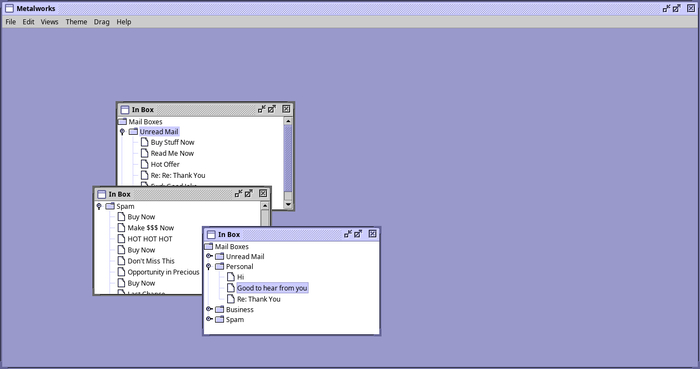
Так выглядит демо Metalworks, с простейшей реализацией мульти-оконной системы (MDI):
Обратите внимание на меню Theme, даже у демо-проекта есть скины!
Напоминаю, что вся эта благодать находится внутри стандартной поставки любой версии JDK, начиная с незапамятных времен 8й версии.
Все демо-проекты содержат исходный код в архивах src.zip и собираются без внешних зависимостей.
К сожалению каталог с демо иногда вырезается ментейнерами дистрибутивов линукса ради экономии места и переносится в отдельный пакет, который пользователи разумеется забывают установить.
Ручная разработка
В ролике в записи показано как автор последовательно вводит и запускает в работу примерно такой код:
// разумеется я не помню названий абсолютно всех // импортируемых классов, поэтому тут стоит '*' importjava.io.*; importjava.net.*; import java.util.concurrent.*;
publicclass MyWebServer {
staticvoid handle(Socket s) { // метод getId() устарел, поэтому его использование в // последних версиях JDK выдает предупреждение System.out.println("Thread: %d" .formatted(Thread.currentThread().getId()));
// самое сложное место, которое удалось повторить на записи // далеко не с первой попытки try(PrintWriter out = new PrintWriter(s.getOutputStream()); BufferedReader in = new BufferedReader( new InputStreamReader(s.getInputStream()));) { // поскольку используется чтение и запись строк а не байт - читаем // строку целиком, т.е. до символа \n String l = in.readLine(); // тут просто показываем в консоль System.out.println(l); // этим простым способом читаем только строку запроса, // которая идет первой, пропустив все заголовки // \r\n (пустая строка) - признак завершения запроса while (l==null || l.isEmpty() || "\r\n".equals(in.readLine()));
// тут мы 'в лоб' сравниваем строку HTTP-запроса целиком // так она выглядит до работы парсера if ("GET /test HTTP/1.1".equals(l)) { // поскольку мы реагируем только на один url '/test' // формируем ниже статичный ответ String data = "Hello from alex0x08 at "+ new Date(); // так выглядят стандартные поля ответа в 'raw' виде, без обработки out.println("HTTP/1.1 200 OK"); // 'close' дает указание браузеру разорвать соединение // с сервером сразу после получения данных out.println("Connection: close"); // поскольку мы отдаем строку - ставим MIME тип 'text/plain' out.println("Content-Type: text/plain"); // опционально отдаем размер данных out.println("Content-Length: " + data.length()); // пустая строка - признак начала блока с данными out.println(); // отдаем сами данные out.println(data); } else { // во всех остальных случаях формируем ответ 404 out.println("HTTP/1.1 404 Not Found"); out.println("Connection: close"); out.println(); } // нужно обязательно вызывать поскольку PrintWriter кеширует данные out.flush(); } catch (Exception e) { e.printStackTrace(); } finally { // в любом случае закрываем клиентский сокет try {s.close();} catch (Exception ee) {} } } // стартовый метод приложения publicstaticvoid main(String[] args) throws Exception { System.out.println("Starting.."); // тоже сложное место, которое было непросто ввести по памяти ExecutorService p = Executors.newFixedThreadPool(10); // создание 'серверного' сокета, который будет прослушивать // указанный порт // поскольку хост не указан - будут прослушиваться все (0.0.0.0) ServerSocket ss = new ServerSocket(8089); // бесконечный цикл, который нужен тк метод accept() - блокирующий // и выход из него произойдет после получения входящего подключения while (true) { // получен клиентский сокет Socket s = ss.accept(); // запуск асинхронной обработки p.execute(() -> handle(s)); } } }
Комментариев в той версии кода, который был показан на записи разумеется нет, они были добавлены уже после — для большего понимания.
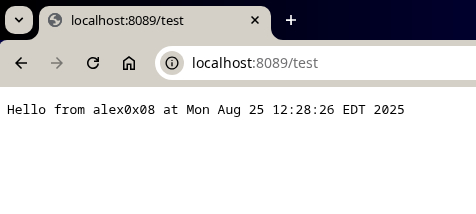
Данный исходный код реализует простейший многопоточный веб-сервер на Java, который отвечает лишь на один URL /test и отдает заранее заданную строку с датой.
Как видите даже столь небольшого количества строк достаточно, чтобы можно было подключиться из современного браузера Chrome:
Компиляция выполняется как и в записи всего одной командой:
После чего появится один единственный class-файл c совпадающим именем. Поскольку пакеты не использовались, для запуска достаточно указать в качестве classpath текущий каталог:
java -cp . MyWebServer
Но это все лирика и понты.
Когда кончается человеческая память
Разумеется невозможно запомнить абсолютно все и рано или поздно вы столкнетесь с названием метода или класса, которые надо где-то подсмотреть.
Для примера, автор при записи видео столкнулся с таким в двух местах:
длинные классы-обертки над потоками (stream) сокета и сложное название статичного метода, создающего экземпляр ExecutorService.
И то и другое получилось правильно ввести далеко не с первой попытки.
Возвращаясь к ситуации когда нет доступа к интернету и полноценной среды разработки, зато на машине есть JDK — показываю что можно сделать в этом непростом случае.
Невероятно но факт:
подсмотреть названия системных классов и методов можно.. в самом JDK!
Вот это поворот!
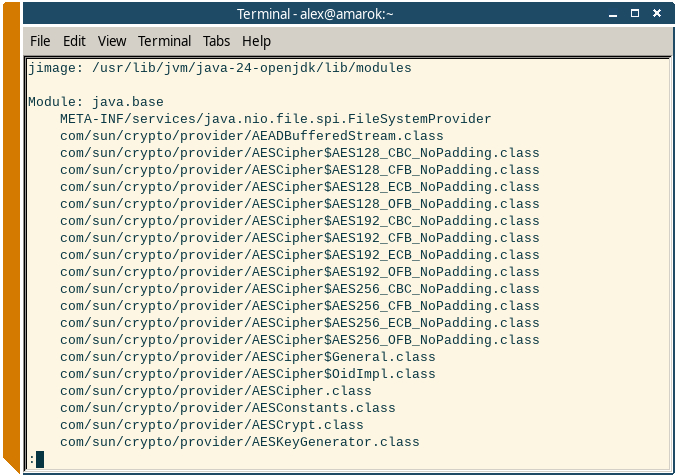
В последних версиях JDK появилась интересная утилита jimage, которая находится в каталоге bin (там же где и главные бинарники java и javac).
С помощью этой штуки можно легко посмотреть полные названия всех системных классов:
Листинг системных классов JDK с полными именами.
Правда знание полного имени класса не всегда помогает, поскольку в JDK много вложенных системных классов, которые по идее вызывать снаружи не надо.
Команда для запуска:
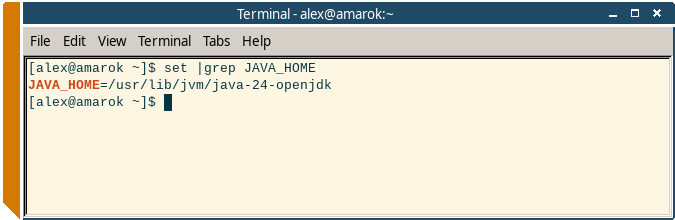
jimage list $JAVA_HOME/lib/modules |less
Где переменная JAVA_HOME указывает на каталог с установленной JDK:
Так вы увидите названия всех системных классов, но что делать с методами?
Вытаскиваем сигнатуры методов
Тут тоже есть решение, поскольку эта же самая утилита позволяет распаковывать jmod-файлы в которых находятся системные классы JDK:
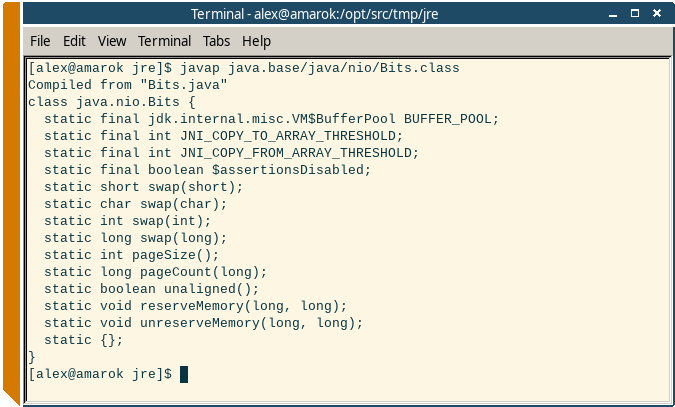
А еще одна утилита javap позволяет посмотреть метаданные class-файла, в том числе сигнатуры всех методов:
cd /opt/src/tmp/jre javap java.base/java/nio/Bits.class
Так выглядит результат:
Вот этого уже с запасом хватит для полевой разработки в условиях крайнего Севера.
Если у вас есть реальный, не "нарисованный" опыт разработки на Java, двух этих трюков будет достаточно для работы в поезде или самолете или на чужом компьютере — в тех местах и обстоятельствах, где нет подготовленного рабочего места.
Исходники JRE
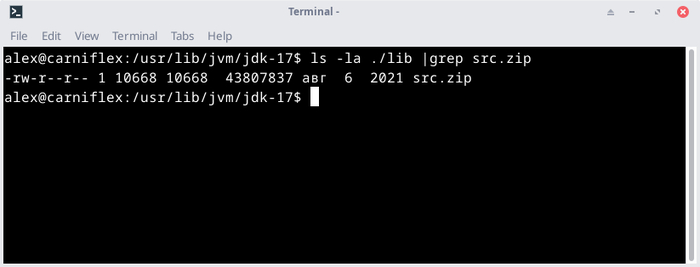
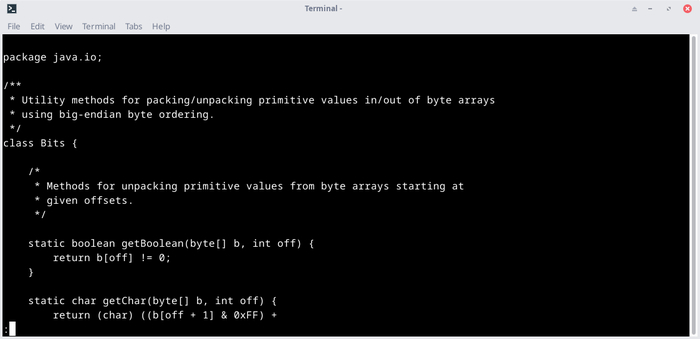
Если вам совсем повезет, в каталоге JDK/lib будет находиться файл src.zip, внутри которого будут исходники всех системных классов JRE:
«Повезет» — потому что также как и demo, этот файл часто удаляют ментейнеры дистрибутивов Linux, с переносом в отдельный пакет. Но разумеется если он присутствует, то поможет гораздо больше чем все приседания с javap.
В распакованном виде:
Внутри находится исходный код всех классов Java, используемых в JDK:
cat java.base/java/io/Bits.java |less
Для примера, так выглядит исходный код класса java.io.Bits, который мы просматривали выше с помощью javap:
Как видите тут есть все, включая комментарии.
Эпилог
Смысл такой «полевой разработки» — в первую очередь глумеж над джунами проверка реальных практических навыков, которые находятся в голове у программиста, а не где‑то в интернете. К сожалению ныне можно констатировать, что такие навыки являются большой редкостью и мало кто из кандидатов, которых я когда-либо собеседовал могли осилить написание хотя‑бы трети подобного кода.
Кстати в нашем Телеграм-канале выложено первое техническое видео, где впервые получилось проверить всю эту идею.
Или что бывает если заставить очень опытного разработчика заниматься не своим делом. Думаю после этой статьи термин «overqualified» заиграет для вас новыми красками.
Пять минут вдумчивого изучения этого скриншота могут привести к нервному срыву, я предупредил.
Наш волшебный дикий веб
Что первым делом приходит в голову, когда говорят о «веб-разработке»? Наверное что-то вроде "создание сайтов или веб-приложений"?
Лендинги, сайты-визитки, интернет-магазины или какие-нибудь веб-порталы в ад.
Самые продвинутые из читателей вспомнят PWA или какой-нибудь React Native с Flutter — предел полета фантазии обычного разработчика.
Что плохо:
главное что отделяет человека от великих свершений это его фантазия — точно нельзя сделать только то, что невозможно вообразить.
Поэтому сейчас мы будем расширять ваше воображение — в превентивных мерах, дрелью и дыроколом подручными средствами. Перед вами шесть проектов отборнейшей дичи — реализующих самые безумные идеи с помощью вполне обыденных инструментов современного веб-разработчика.
Пожалуйста не пытайтесь рассказывать о таком на интервью в обычных компаниях — пожалейте интервьюера и его нежную психику.
Дичь первая: HTMLang
Не смог пропустить столь жизнеутверждающее описание от автора этого замечательного проекта:
They were laughing that HTML was not a real programming language... WHO"S LAUGHING NOW!!11
Да, это именно то что вы подумали — кто-то будучи сильно не в духе взял общий синтаксис HTML и создал на его основе полноценный язык программирования.
Не представляю что будет если самому Джоэлу выдать его же знаменитый «FizzBuzz» в такой реализации — есть шанс что старый сишный программист впадет в рекурсию.
Кстати кто там рассказывал на лекциях про «декларативный язык разметки» и «общую неполноценность»?
HTML (от англ. HyperText Markup Language — «язык гипертекстовой разметки») — стандартизированный язык гипертекстовой разметки документов для просмотра веб-страниц в браузере.
Зря старались, автор этого проекта тем временем спокойно пишет в консоль тегами HTML:
А все потому, что не надо нанимать системных программистов, прошедших полноценное обучение по дисциплинам CS (вроде курса по разработке компиляторов) для работы штатным говночистом разработчиком в обычном корпоративном проекте.
Дичь вторая: HTML-as-programming-language
Нехорошие мысли терзают многих опытных разработчиков — все та же идея «полноценной разработки на HTML» не дает покоя и автору данного проекта.
Но только он зашел в этом процессе несколько дальше предыдущего.
Как вам например функция на чистом HTML:
<def multiplyFunction returns=int> <!-- You can create functions --> <param a type=int/> <param b type=int/> <return>a * b</return> </def>
<def main> <var result type=int> <!-- Create variables --> <multiplyFunction> <!-- and store the result of the function in the variable --> <param>5</param> <param>6</param> </multiplyFunction> </var> </def>
Известная библейская истина «многие знания — многие печали» — как раз про этот проект, например я бы очень хотел все это забыть и никогда о подобном не знать.
Но к сожалению уже слишком поздно, поэтому делюсь откровениями:
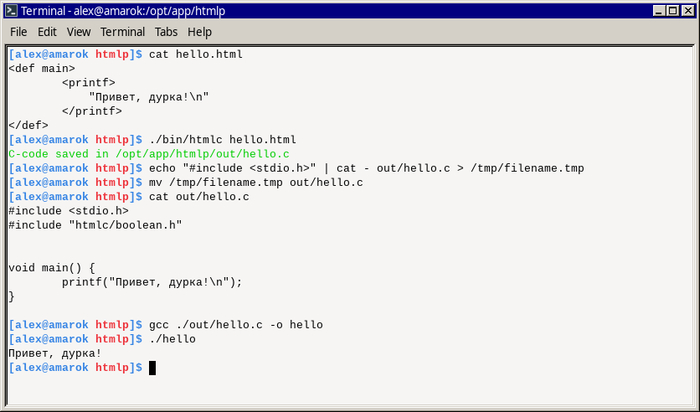
Замечательный пайплайн с вызовом компилятора HTML, правда?
Да, вы все правильно поняли — это самый настоящий компилятор из HTML в нативный ELF64.
А сейчас совсем поплохеет:
To write code for Adruino/AVR microcontrollers, (Arduino UNO for example) you need to put a DOCTYPE tag in your HTML file.
For example:
<!DOCTYPE avr/atmega328p>
Да, это была оригинальная задумка автора — разработка для микроконтроллеров на HTML, я ничего не придумываю.
К слову, небольшая магия с #include <stdio.h> на скриншоте выше была необходима как раз потому, что компилятор предназначен для микроконтроллеров и не добавляет в генерируемый код на С этот стандартный для обычной ОС заголовок.
Вот так выглядит эта железка, если никогда не видели.
К сожалению у меня не оказалось под рукой такого девайса, так что полноценную работу и весь пайплайн проверить не смог. Но если среди читателей найдутся смелые люди, которые смогут это запустить — с радостью почитаю о впечатлениях.
А мы тем временем переходим к следующему замечательному проекту.
Несмотря на то что автор честно пишет о куче недоработок:
Work in progress: it works, but only about 70% of ES3 specification is currently supported: statements and expressions - 95%, built-in objects - 17%.
Скажу что это самый работоспособный проект из серии, все остальное буквально рассыпается в руках. Рассыпается и валится как и следующий объект исследования.
Дичь пятая: nerd
Как легко и быстро понять что исследуемый проект — дикое, нерабочее и глючное говно?
По описанию, обещающему бесконечные ништяки:
Javascript's God Mode. No VM. No Bytecode. No GC. Just native binaries.
Отсылка к чему-то божественному в описании технического проекта это вообще практически 100% диагноз, можно отбраковывать только по одному этому признаку — врядли ошибетесь.
Как нетрудно догадаться, вместо нормального JavaScript тут тоже что-то свое божественное:
NerdLang is a substract of JS with some additions, focus on efficiency.
И это «свое» скажем так застряло в далеком прошлом:
Supporting EcmaScript 3 standard
На минуточку, 3я редакция стандарта вышла еще в далеком 2000м году.
А сам проект пытается в который раз «натянуть сову на глобус» и залезть туда, где последовательно обломали клыки все крупные корпрорации уровня Google:
Nerd is a JavaScript native compiler aiming to make JavaScript universal, Nerd is able to compile native apps for Windows, Mac, Linux, iOS, Android, Raspberry, STM32 and more.
Разумеется я не мог пройти мимо такого, поэтому всю эту дичь собрал и запустил, хотя и пришлось немного исправлять скрипты сборки.
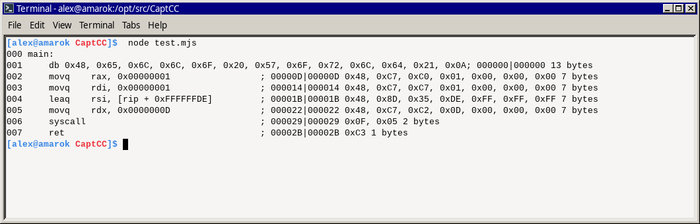
Пайплайн (присутствует на титульном скриншоте) выглядит вот так:
Автор настолько суров, что запихал инстукции сборки и линковки модуля работы с сокетами в package.json:
Увидев вот такой package.json, знакомый веб-разработчик решил навсегда уйти из профессии и теперь пасет коз в горах Кавказа. Ну а я всего лишь не рискнул адаптировать такое для сборки под Linux, так что вы останетесь без примера запуска HTTP-сервера на этом чудище.
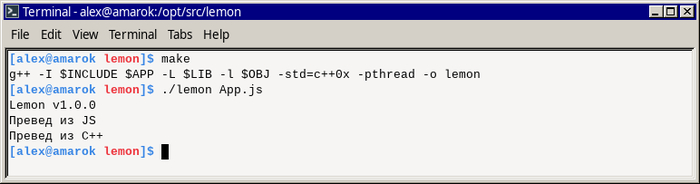
Дичь шестая: lemon
Наконец последний на сегодня проект, который по сравнению с предыдущими является можно сказать нормальным и где-то даже применимым:
Lemon is a framework for building Javascript runtime software, built on the Chrome V8 Javascript Engine.
Мне он понравился своей предельной простотой (по сравнению со всеми остальными проектами) и легкостью встраивания.
Ниже показано как выглядит двойной «Hello, world», в котором есть как часть на JavaScript так и часть на C++ — немного подумав объединил два примера из документации в один.
App.js:
version(); console.log("Превед из JS"); helloworld();
App.hpp:
#ifndef APP #define APP
#include "../engine/Lemon.hpp" using v8::Context;
class App : public Lemon { public: void Start(int argc, char* argv[]); void SetupEnvironment(); }; #endif
for (int i = 1; i < argc; ++i) { // Get filename of the javascript file to run constchar* filename = argv[i]; // Create a new context for executing javascript code Local<Context> context = this->CreateLocalContext(); // Enter the new context Context::Scope contextscope(context); this->CreateGlobalObject("console") .SetPropertyMethod("log", Log) .Register(); // Run the javascript file this->RunJsFromFile(filename); } }
Чудны дела твои Господи, коль даже перебирая запредельную дичь есть шанс найти столь мощный проект.
Спросите с чего столько радости?
Потому что это самый настоящий V8, не самопал с реализацией ECMAScript «в переводе Гоблина», а именно тот самый движок, который используется в браузере Chrome — со всеми оптимизациями и наворотами.
А значит при определенных усилиях, у вас будет работать практически любой JavaScript код — в вашем нативном приложении, без всяких жирных Node.js и всех проблем с линковкой и версиями.
Словом берите на вооружение, пригодится.
Одной строкой
Конечно же интересных проектов в области творения дичи куда больше чем хватит сил описать, поэтому ниже небольшая подборка найденного и интересного, но неработающего.
Compile javascript to LLVM IR, x86 assembly and self interpreting
К сожалению оказался прибит гвоздями к определенной версии MacOS, ни нормально собрать ни прогнать тесты под Linux не удалось. Интересен тем что в одном проекте собран и интерпретатор и компилятор, причем в нативный бинарник.
Недавно Кинопоиск отключил пользователям личную статистику по просмотренным фильмам — это был последний нетронутый островок функциональности, оставшийся от классической версии сайта.
Неизвестно, что стояло за этим решением, но в любом случае на официальном форуме уже создаются обсуждения в защиту удалённой статистики, например тут и тут.
Меня это изменение не задело — я давно уже переехал с Кинопоиска на Letterboxd.
Не буду сегодня останавливаться на моих впечатлениях от Letterboxd в целом (спойлер: они смешанные). Но вот интересно посмотреть, как там обстоят дела со статистикой просмотренного.
Хорошая новость в том, что она есть. Вот примеры для профиля целиком и за конкретный год. Но плохая новость в том, что статистика доступна только на платной Pro-подписке.
Что очевидно подталкивает нас к тому, чтобы сделать своё решение, где будет вся нужная нам статистика бесплатно и в лучшем виде. Тем более, Letterboxd позволяет выгрузить всю свою личную информацию в виде архива.
Сегодня я покажу, что у меня получилось, поделюсь исходным кодом и расскажу, как легко запустить такой же проект у себя локально или в облаке.
❯ Текущий статус проекта
Проект я назвал Cinesta — сокращение от Cinema Statistics («Статистика кино»). Что в принципе и отражает ключевую задачу проекта — отобразить разнообразную статистику конкретного человека на основе данных о его просмотренных фильмах.
Это не готовый сайт-сервис, а проект с открытым кодом для личного использования, доступный в репозитории на GitHub.
Код можно скачать и запускать на своём ПК, на сервере и в облачной платформе. Далее мы разберёмся, как это сделать.
Не стоит ожидать от Cinesta многого — это всего лишь прототип, собранный на коленке за пару выходных просто для демонстрации, вдохновения и проверки гипотезы. Да, функций мало, код кривой, дизайн простоват, с телефона не юзабельно и местами всплывают баги, но это всё нормально для первой версии.
Код можно использовать как вам угодно: копируйте его, модифицируйте с помощью ИИ, добавляйте нужные вам графики и другую информацию. Можете даже доработать его в полноценную платформу.
Хоть и проект предназначен для личного закрытого использования, я временно для демонстрации запустил копию проекта по адресу cinesta.ru. Проект не адаптирован для использования многими пользователями одновременно, поэтому работоспособность не гарантируется, но как минимум демо-данные должны подгружаться нормально.
База данных не используется. Загруженный пользователем архив из Letterboxd просто извлекается в удобный вид, обогащается данными из TMDB и затем возвращается пользователю обратно в браузер.
❯ Как работает проект
Итак, посмотрим, как выглядит и работает Cinesta. Пока что пропустим вопрос установки, настройки и загрузки данных — мы вернёмся к этому позже. Представим, что уже всё готово.
На главной странице сразу показывается ключевая статистика в виде карточек и графиков. Рассмотрим всё по порядку.
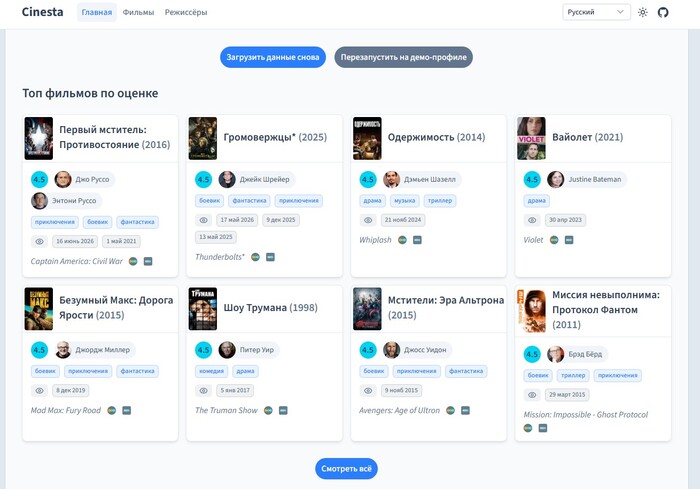
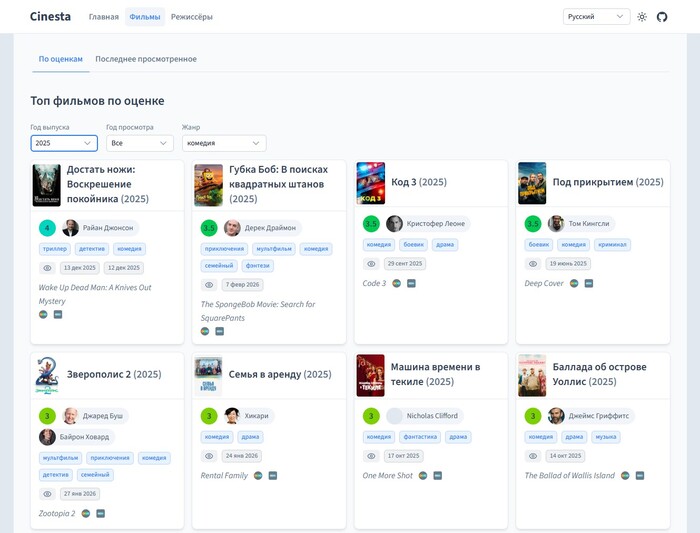
Топ фильмов по оценке
Визитная карточка любого киногика — список его любимых фильмов.
Поэтому в первую очередь на главной мы видим карточки 8 фильмов с самой высокой оценкой.
В каждой карточке есть название фильма, год выхода, постер, ваша оценка фильму по 5-балльной шкале, режиссеры, жанры, даты просмотра, а также оригинальное название и ссылки на Letterboxd и TMDB.
Если баллы одинаковые, то фильмы располагаются в порядке просмотра — от недавних дат к более давним.
Под блоком есть кнопка «Смотреть всё», которая переводит на страницу с полным списком фильмов по рейтингу (к ней мы еще вернёмся).
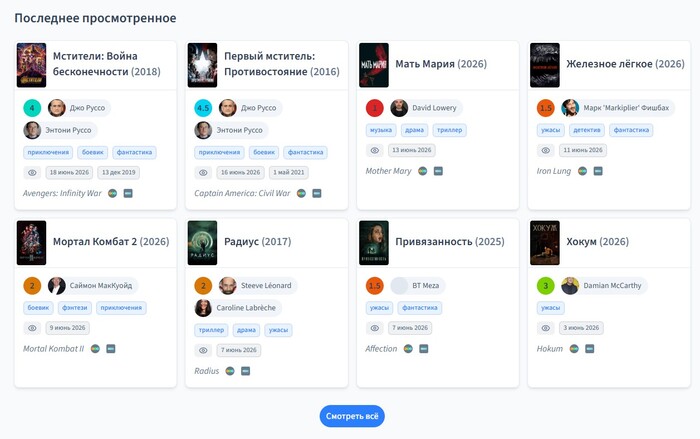
Последние просмотренные
Далее в аналогичном блоке с карточками показывается список последних просмотренных фильмов.
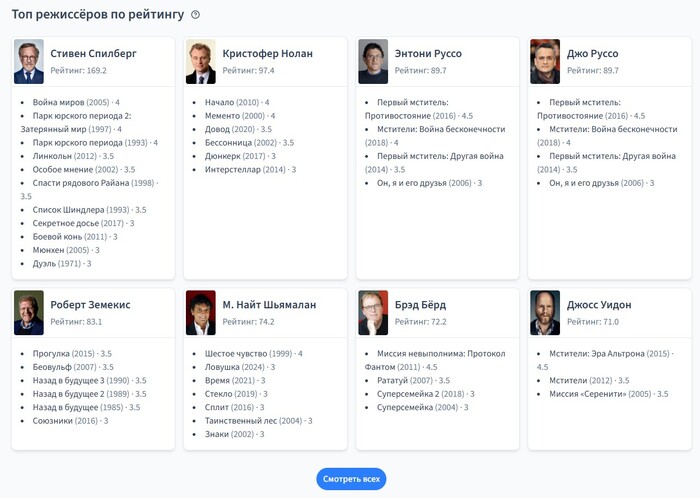
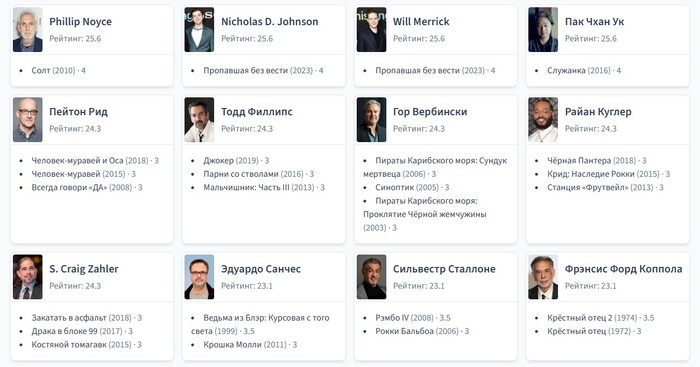
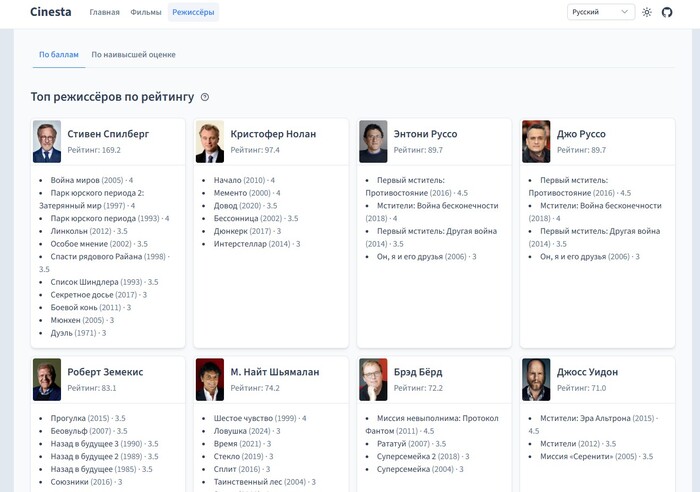
Топ режиссёров по рейтингу
Далее идут карточки с вашими любимыми режиссерами.
На главной показываются только 8 топовых режиссеров, а по клику на кнопку «Смотреть всех» будет переход на отдельную страницу, где можно посмотреть всех.
Здесь у нас необычное решение — рейтинг режиссеров на проекте составляется по баллам (points), которые рассчитываются по специальной формуле.
Если навести мышью на рейтинг режиссера, то в подсказке отобразится, как именно он был посчитан.
Обычно в подобной статистике, когда выводят лучших режиссеров, считают их или по средней оценке, или по количеству просмотренных фильмов.
На мой взгляд, ни то ни другое не отражает полноценной картины. Потому что важно одновременно учитывать и количество, и качество фильмов.
Более того, обычно для расчёта рейтинга режиссёров берутся вообще все их просмотренные фильмы. Но мне кажется, что лучше брать только те, которым пользователь поставил хорошую оценку.
В итоге наша формула рейтинга режиссёра работает так:
Берется каждый фильм с оценкой от 3 и выше.
Оценка каждого фильма возводится в 4 степень (т.е. 3 становится 3*3*3*3=81).
Полученные числа складываются.
Итоговое число делится на 10 и округляется до десятых — это сделано просто для упрощения восприятия.
Вы спросите, почему оценки фильмов не просто суммируются, а возводятся в 4 степень? Это нужно, чтобы увеличить удельный вес фильмов с самыми высокими оценками. Потому что если просто сложить баллы, то режиссер, который снял два середняка (3+3 = 6) получит больше баллов, чем режиссер, который снял один шедевр на 5 баллов.
Но если мы перед сложением возводим оценки в степени, то высокие баллы усиливаются. Например, если в нашем простом примере возвести оценки во вторую степень, то режиссер с 5-балльным фильмом теперь победит: будет 3*3 + 3*3 = 18 против 5*5 = 25.
Но когда я начал пробовать эту формулу, то понял, что для меня второй и даже третьей степени мало. А вот четвёртая — самое то.
Посмотрим конкретный пример на странице «Режиссёры», к которой мы еще вернемся.
Наверху этого списка четыре режиссера, у каждого из которых по одному фильму с оценкой 4. Эта оценка даёт 25,6 баллов. И этого достаточно, чтобы они встали выше тех, кто снял по три трёхбалльных фильма и получил за это по 24,3 балла.
А дальше идут те, у кого в наличии один фильм с 3 баллами и один с 3,5 баллами.
Т. е. при такой формуле на первое место выходит качество, а не количество. Хотя и количество тоже играет роль.
Мне кажется, такой подход полноценно отражает ценность хороших фильмов, в результате чего формируется объективный рейтинг режиссеров. Очень интересно будет послушать ваше мнение на этот счёт в комментариях.
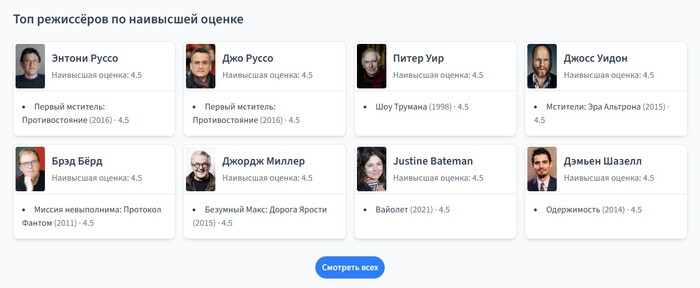
Топ режиссёров по наивысшей оценке
Тем не менее, даже такое продвинутое решение, как расчет рейтинга режиссёров по специальной формуле, в некоторых случаях всё равно не даёт полной картины.
Поэтому дополнительно есть список режиссеров по их максимальной оценке. Если режиссёр снял всего один фильм, но этот фильм получил высокий балл от пользователя, то он всё равно будет в топе этого списка.
Также, как и в остальных блоках, по клику на «Смотреть всех» будет переход на отдельную страницу с полным списком.
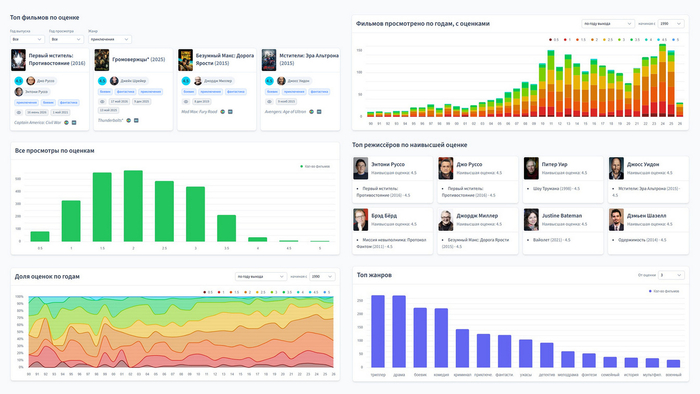
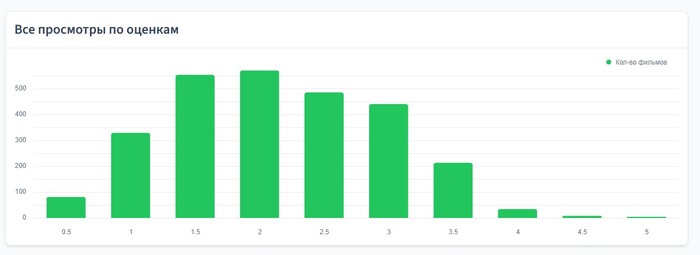
Все просмотры по оценкам
А дальше начинаются графики. Первый график самый простой и очевидный — количество всех фильмов, разбитых по оценкам.
По этому графику можно понять характер оценок пользователя. Любит ли он занижать или завышать оценки. Старается ли он оценивать рассудительно, помещая много фильмов по центру, или же больше доверяет эмоциям и часто ставит минимальные и максимальные оценки.
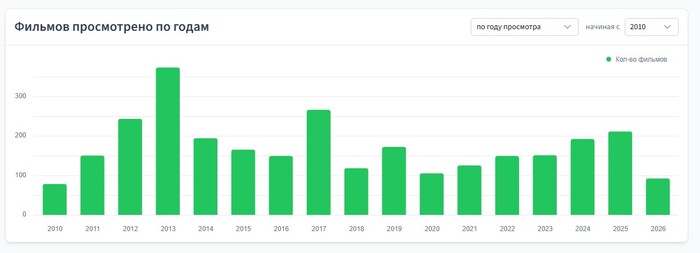
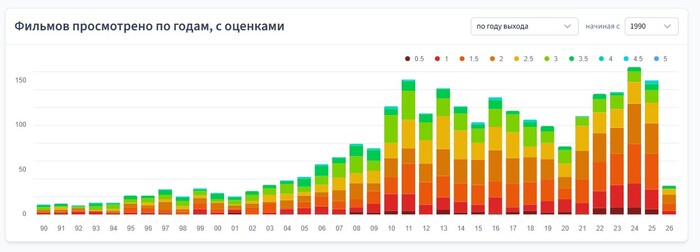
Фильмов просмотрено по годам
Далее еще один простой график — количество всех просмотренных фильмов по годам.
При этом можно выбрать, считать ли по году просмотра или по году выхода фильма. Также можно выбрать, с какого года начинать отсчёт.
Тут стоит отметить, что TMDB считает год выхода фильма по дате его премьеры. Как правило, это бывает на каком-нибудь фестивале задолго до выхода фильма в кинотеатрах. Это неоднозначный подход, который иногда путает и мешает видеть адекватную статистику.
Фильмов просмотрено по годам, с оценками
А вот теперь кое-что поинтересней — все фильмы по годам выхода, с разбивкой по оценке внутри столбца.
На этом графике можно оценить не только то, на сколько больше или меньше смотрел пользователь фильмов в каждый год, но и то, отразилось ли количество на качестве.
На примере видно, что в 2024 вышло больше посмотренных фильмов, чем в 2023, но весь этот прирост ушел у пользователя в фильмы с низкой оценкой, а количество качественных фильмов не изменилось.
Так же, как и в предыдущем графике, можно выбрать, считать ли по году просмотра или по году выхода фильма. И с какого года начинать отсчёт.
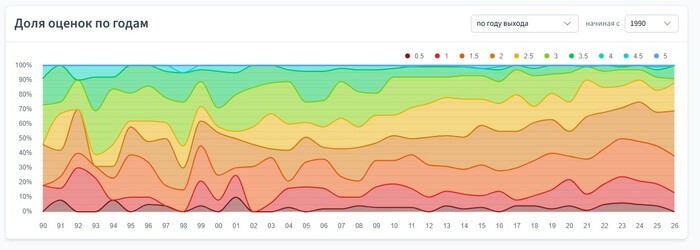
Доля оценок по годам
В прошлом графике уже можно было отследить, как менялось количество фильмов с разными оценками.
В этом же графике количество не важно — важен процент. Т. е. мы смотрим на отношение фильмов с определенной оценкой ко всем фильмам этого года. За основу берётся год выхода фильма.
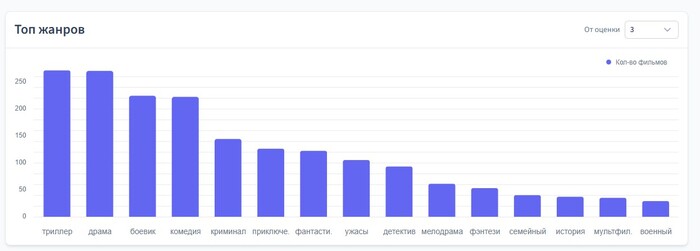
Топ жанров
Рейтинг самых популярных у пользователя жанров.
Можно выбрать, от какой минимальной оценки вести счёт. По умолчанию — от 3 включительно.
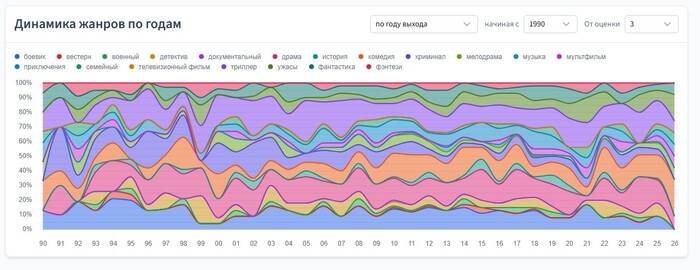
Динамика жанров по годам
А тут можно посмотреть жанры в динамике — как менялось количество посмотренных фильмов определенного жанра с каждым годом.
На этом главная страница заканчивается и переходим к другим страницам.
Страница «Фильмы»
Отдельная страница посвящена только фильмам.
По умолчанию открывается вкладка «По оценкам» — это список всех фильмов, отсортированных по оценке.
Здесь можно отфильтровать фильмы по году выхода, году просмотра или по жанру.
А на вкладке «Последнее просмотренное» показываются последние просмотренные фильмы.
Страница «Режиссеры»
На странице «Режиссеры» по умолчанию открывается вкладка «По рейтингу». То же самое, что и на главной, только тут уже выводятся все режиссеры.
Вторая вкладка — «По наивысшей оценке».
На этом мы рассмотрели всю функциональность проекта. Да, информации и графиков пока мало — то, что есть, это скорее для демонстрации и вдохновения. Вы можете легко доработать проект самостоятельно или с помощью ИИ.
❯ Как зарегистрироваться в TMDB (The Movie Database)
Теперь посмотрим, как настроить и запустить такой проект у себя. Начнём с подключения к TMDB (The Movie Database).
Сразу предупредим, что TMDB не доступен с территории РФ. Не открывается сайт, не доступен API и не будут открываться картинки с серверов TMDB. Это конечно легко решается, но в данной статье мы не будем на этом останавливаться.
Для получения детальной информации о фильмах вам нужен доступ к API сайта The Movie Database (TMDB). Однако, вы можете пока пропустить этот шаг, если вам хочется просто посмотреть на проект на тестовых данных (они загрузятся и без TMDB).
Потом переходим в настройки аккаунта, в API, нажимаем «Создать» и выбираем «This is for my own personal use only». Затем еще раз подтверждаем, что API только для личного некоммерческого использования.
Затем нужно заполнить нудную форму с подробной информацией. Можно всё выдумать самому или попросить ИИшку.
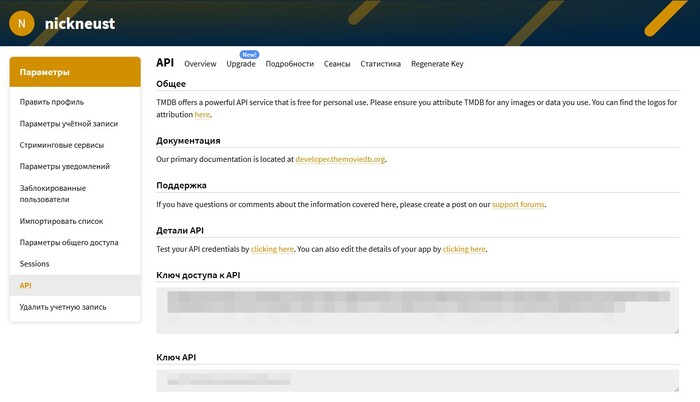
После отправки формы откроется страница с готовыми API ключами и подробной информацией, как их использовать.
В нашем случае потребуется более длинный ключ — «Ключ доступа к API» (API Read Access Token). Всё, вы готовы к использованию TMDB API.
❯ Как запустить проект локально
Для локального запуска проекта в вашей операционной системе вам предварительно нужно установить Node.js, pnpm и git.
Когда будете готовы, скопируйте репозиторий к себе и перейдите в папку проекта. Это можно сделать командами:
В папке проекта создайте файл .env с нужными переменными:
# Ваш токен для подключения к API TheMovieDatabase (обязательно, если хотите загрузить свои данные) NUXT_TMDB_TOKEN="qwertyoasdf123435asdfzxcvasdfqw234adsf" # Для обхода ограничений со стороны TMDB (обязательно для входа с российского IP) NUXT_TMDB_PROXY="http://admin:password@123.123.123.123:8000"
Затем из папки проекта по отдельности запустите команды, чтобы установить зависимости, собрать проект и запустить его.
pnpm install pnpm build pnpm preview
И всё, сайт будет доступен по локальному адресу http://localhost:3000/ Что делать потом, будет рассмотрено чуть дальше.
❯ Как запустить проект в облаке
Но может быть вы хотите запустить проект на облачном сервере, чтобы он был доступен другим людям.
Есть разные способы, как это сделать, и сегодня мы рассмотрим установку с помощью App Platform от Timeweb Cloud.
Заходим в раздел App Platform и нажимаем «Создать». Открывается форма настройки приложения, которая состоит из нескольких пунктов.
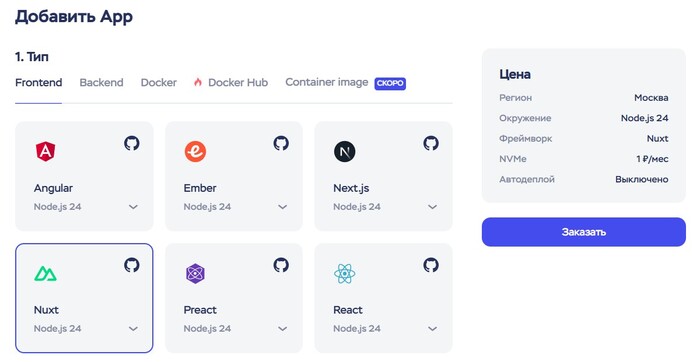
Форма создания приложения
1. Тип
У нас приложение на фронтенд-фреймворке Nuxt, поэтому на вкладке Frontend выбираем Nuxt.
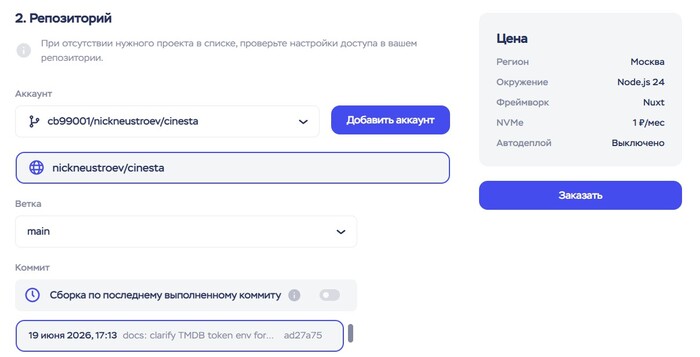
2. Репозиторий
У нас открытый репозиторий, доступный для всех по ссылке, поэтому кликаем на «Подключите git-репозиторий по URL» и далее вставляем ссылку на репозиторий: https://github.com/nickneustroev/cinesta.git
Оставляем ветку и коммит по умолчанию.
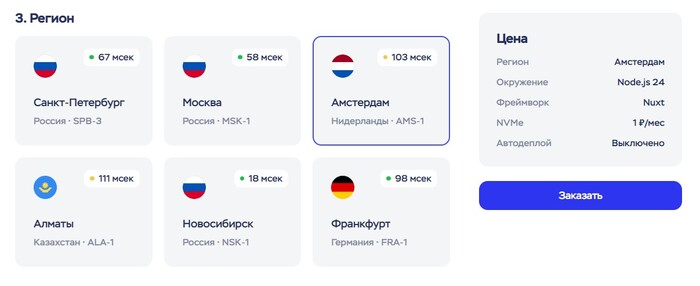
3. Регион
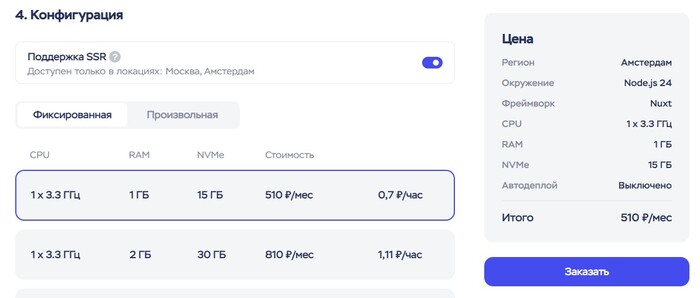
Нам важен регион с поддержкой SSR. Чуть ниже в форме в пункте 4 есть примечание, какие регионы поддерживают SSR. На момент написания статьи это Москва и Амстердам — значит, мы должны выбрать что-то из них.
Можно выбрать Амстердам, потому что это европейский регион, и может быть TMDB API будет работать с этим сервером напрямую без обхода, хотя это не гарантируется.
4. Конфигурация
Тут видим галочку «Поддержка SSR», и на самом деле она означает поддержку серверной части Nuxt в целом, не только SSR (серверный рендеринг страниц).
В нашем случае SSR на проекте отключен, потому что он не нужен. Но нам нужна работающая серверная часть, потому что именно там обрабатываются загруженные из Letterboxd данные и оттуда идут запросы к TMDB.
Так что включаем эту галочку.
После этого выбираем конфигурацию сервера. Нам достаточно самой простой — 1 CPU 1 RAM.
5. Сеть
Оставляем по умолчанию
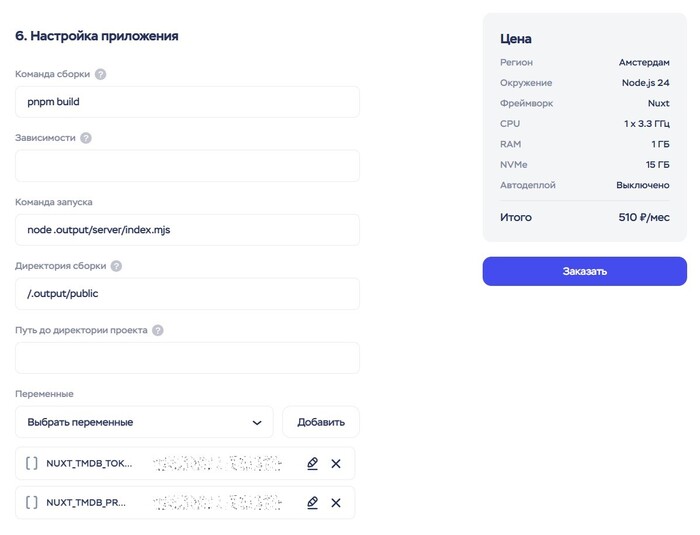
6. Настройка приложения
Здесь прописываются настройки для сборки и запуска приложения.
У каждого фреймворка есть свои настройки по умолчанию, и они уже тут прописаны, так что мы можем почти всё оставить как есть. Только заменим «npm run build» на «pnpm build».
Далее тут же надо добавить переменные окружения. Нажимаем «Добавить» и прописываем значения для NUXT_TMDB_TOKEN и для NUXT_TMDB_PROXY, если необходимо.
7. Информация о приложении
Тут можно указать имя, комментарий приложению и выбрать проект. Это роли не играет, и нужно только для удобства и наглядности.
На этом все готово и можно нажать «Заказать».
Запуск приложения
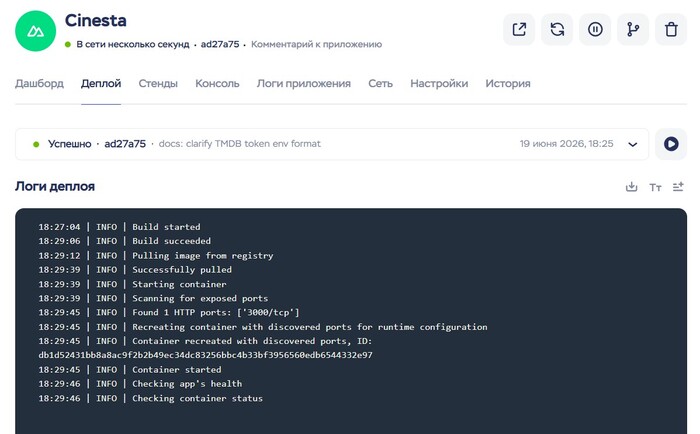
Начнётся деплой (установка) приложения, который займет несколько минут.
После этого вы увидите сообщение, что всё успешно запущено.
По умолчанию App Platform уже выдаёт и подключает бесплатный технический домен, который может выглядеть как https://nickneustroev-cinesta-02f5.twc1.net/. Это как раз удобно для тестовых или пет проектов.
Поэтому вы можете сразу кликнуть на кнопку «Открыть приложение в новой вкладке» в панели сверху, и сайт откроется.
Покупка и подключение домена
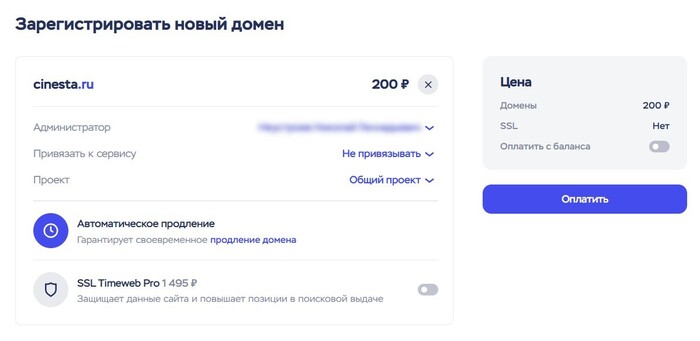
Но если вам всё-таки хочется подключить проект к своему домену, то сделать это несложно. Раз я всё равно поднимаю копию проекта для демо, то почему бы и не купить домен и не показать вам, как это делается.
Переходим в раздел «Домены» и выбираем «Купить домен».
Подбираем имя и добавляем домен в корзину.
Переходим в корзину. Тут, если необходимо, пока убираем пункт «Привязать к сервису» — это можно будет сделать позже.
Также, отключаем «SSL Timeweb PRO», потому что это платная профессиональная услуга, которая нам в данном случае не нужна.
Нажимаем «Оплатить» и далее после оплаты домен будет приобретен и появится в списке Доменов. Но чтобы полноценно им пользоваться, нужно подождать несколько минут.
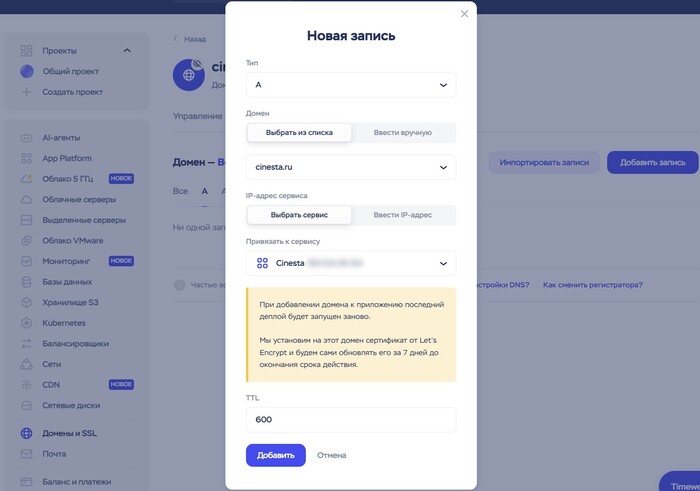
Когда домен будет готов, заходим в его настройки во вкладку DNS, нажимаем «Добавить запись» и выбираем тип записи «А». Из списка сервисов выбираем созданное нами приложение в App Platform и нажимаем «Добавить».
Деплой приложения будет запущен заново, и после его завершения проект будет доступен по новому домену. Хотя иногда, чтобы изменения применились, нужно подождать.
❯ Как начать работать с проектом
Итак, мы запустили приложение локально или в облаке, сайт открывается.
Теперь посмотрим, какие настройки есть на сайте и как правильно загрузить свои данные.
1. Выбор языка
На проекте есть выбор языка: Русский и Английский.
Выбор языка не только меняет язык интерфейса, но также будет определять, на каком языке будет выгружена информация из TMDB: названия фильмов, обложки, жанры и имена режиссеров. Поэтому сразу до импорта выберите, какой язык вам больше подходит.
Важно ещё учитывать, что с разным языком TMDB будет выдавать разные результаты поиска фильма по названию. С английском языком данные получаются более точные.
2. Светлая и темная тема
На сайте можно переключать светлую и темную тему, кликнув на иконку в шапке возле выбора языка. Это функциональность обеспечивается из коробки библиотекой Nuxt UI.
4. Импорт своих данных
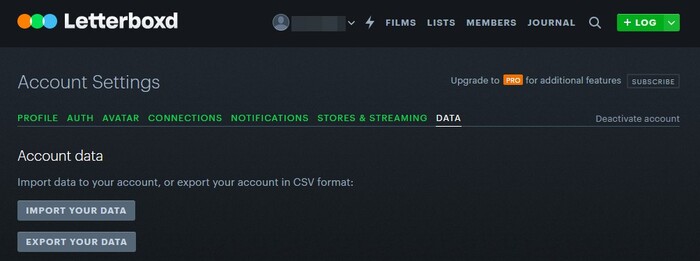
Пока проект принимает только данные из Letterboxd. На сайте Letterboxd откройте Profile —> Settings —> Data и там нажимайте кнопку Export you Data. Вы сможете скачать архив в формате zip. Именно его в неизменном виде нужно будет загрузить на нашем сайте.
Нажмите «Загрузить файл» и укажите файл с архивом. Будет показано число обнаруженных в архиве фильмов и отобразится примерное максимальное время обработки. На практике обработка будет быстрее, потому что уже полученная из TMDB информация сохраняется на сервере в кэше.
Нажмите кнопку, чтобы начать импорт. Если сервер уже занят обработкой данных от другого пользователя, то вам будет предложено подождать и запустить импорт позже.
5. Импорт демо-данных
Если вы пока просто хотите посмотреть, как работает статистика, вы можете нажать «Запустить на демо-профиле». Будет импортирован архив с демо-данными.
При этом дополнительная информация по демо-архиву уже выгружена заранее и хранится в коде проекта в виде json-файла. Поэтому загрузка данных демо-архива произойдёт мгновенно и она сработает, даже если у вас в настройках приложения не указан ключ к API TMDB.
Если вы запускаете проект в dev-режиме, то все импортируемые из TMDB фильмы будут добавляться в общий кэш и сохраняться в data/tmdb-cache.runtime.json
6. Хранение данные в браузере после импорта
Данные о фильмах сохраняются в браузере в виде IndexedDB. Это значит, что вы можете обновлять страницу или даже совсем закрывать её — данные не пропадут и не будут требовать повторного импорта.
❯ Итоги
На дворе 2026 год, мы живём в эпоху расцвета ИИ, и создание сайтов и приложений ещё никогда не было таким простым.
Нам, обычным пользователям, больше не обязательно ждать, пока на сайтах появится нужная нам функциональность. Во многих случаях мы теперь можем сделать всё сами — подключиться к API, собрать свой скрипт, бота, несколько страниц, расширение для браузера. И в итоге решить нужную задачу лучшим для нас образом.
Я постарался этим кейсом показать, как это можно делать, на примере конкретной проблемы. Надеюсь, это вдохновит вас попробовать сделать что-то такое же, или может быть вы захотите доработать этот прототип в более мощное приложение под ваши индивидуальные потребности.
Или как минимум, надеюсь что вы получили интересный взгляд на свою статистику просмотренных фильмов и узнали что-то новое о себе.
Если не хотите пропустить следующую статью или выход новых версий проекта, вы знаете, что делать.
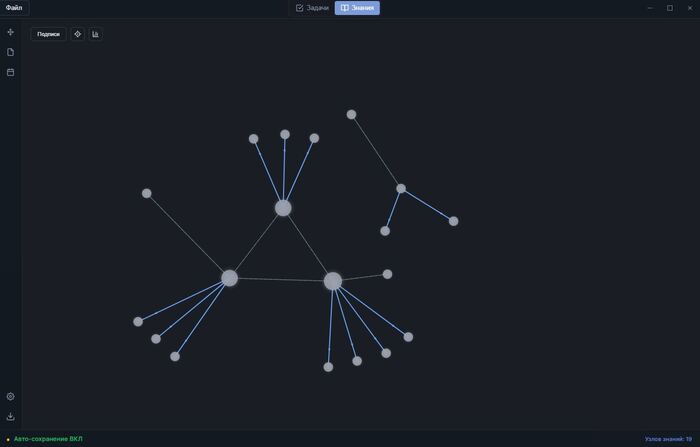
Продолжаю вести серию постов про Gamma Resonance. Не то что бы Obsidian тут как-то замешан, но новая фича очень похожа на него. До этого был просто планировщик в виде графа с математической моделью (которую в будущем буду улучшать), но чего-то мне лично не хватало. Решил в одно рабочее пространство добавить также граф знаний, так как удобно держать и задачи, и заметки в одном месте. Было множество идей как это реализовать "правильно". Пришел все таки к тому, чтобы сделать эти два графа в одном рабочем пространстве, скажем так. Просто через переключение режимов. Подумал, что это будет лучше, чем множество файлов, графов, которые раскиданы по папкам. Сначала с .md перешел на .json сохранение, что мне особо не дало лучшего результата. В конечном итоге выбрал для хранения SQLite - базу данных для удобного хранения, быстрой записи на диск и, что самое главное, инкрементального сохранения (если кто не знает, то эта фишка дает возможность сохранять только нужные блоки, узлы, записи отдельно, не перезаписывая ВЕСЬ файл), что позволяет без проблем работать с тысячами узлами с заметками без особо сильных тормозов.
Да, круто, все работает. Если кто-то спросит "ну и смысл? есть же привычный obsidian", то да, соглашусь с тем, что программа еще сыроватая, только начал разработку. Но! Я не пытаюсь полностью скопировать Obsidian, а лишь сделать удобную программу для личной продуктивности, которая, кстати, работает полностью локально и без интернета, данные не собирает ВООБЩЕ, вот прям ноль. Для бизнеса это плохо - я не вижу скачивания, я не вижу статистику, я не вижу вообще ничего. Для тех, кому программа реально зайдет - это большой плюс, и для самих пользователей в принципе, кто будет пользоваться хоть как-то.
Ладно, вернемся к графу знаний. На первом этапе я добавил в него только создание узлов, создание подузлов, то есть иерархию и обычное связывание через интерфейс, но пока что без ссылок. Но сам узел не является заметкой. Это контейнер по своей сути, который содержит заметки.
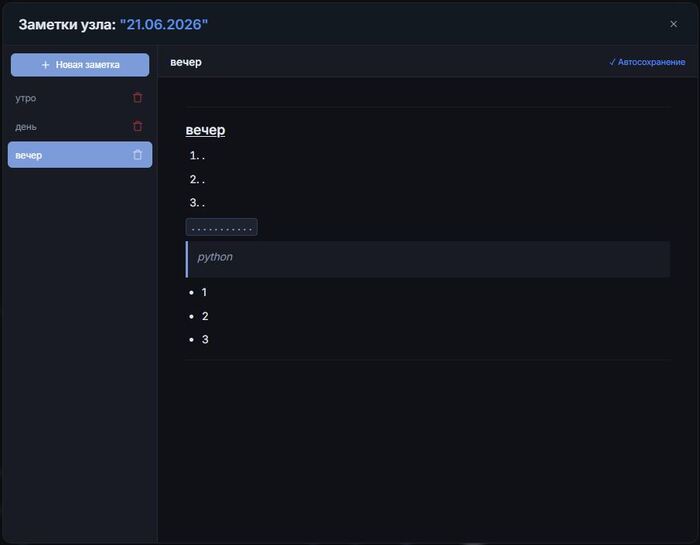
Первая ситуация: у меня был очень насыщенный день, хочу записать все до мелочей, чтобы потом проанализировать и вести статистику. Был бы узел целой заметкой, хорошо, вроде база, но как по мне каша. мне нужно разделить день на 3 части - утро, день и вечер. Допустим создам 3 узла с каждой частью, но как их удобно связать? как понять, что от чего зависит? Поэтому вместо "1 узел - 1 заметка" я сделал сам узел контейнером, где можно добавлять СКОЛЬКО УГОДНО заметок и разделять их. Вот пример:
Вторая ситуация: у меня есть некий проект на пайтоне, который состоит из 5 файлов. Допустим мне нужно его сохранить в заметки, чтобы не забыть/сохранить/на память/проанализировать, в общем много каких может быть причин. Заливать все в одну заметку? Каша, неудобно. Каждый файл по отдельности на несколько заметок? Не знаю кому как, но мне было бы неудобно. В один узел-контейнер, где можно по очереди создать нужные заметки под каждый файл? Да, было бы неплохо.
Примерно так выглядит шаблон графа знаний. Синие связи - иерархия, серые связи - обычные связи.
В планах много чего доделать, но без фидбека это будет сложнее сделать, так как не знаю точный вектор и направление разработки. Призыв к действию: если хоть кого-то заинтересует моя прога, буду очень благодарен за фидбек и конструктивную критику. Связь, Пикабу!
В пригороде далекого города Нью-Дели жил простой индийский паренек со сложным именем Чандракант. Любил он маму, Кришну и общаться с волшебными говорящими грибами.
Три грани безумия на одной картинке.
Однажды после особо глубокого погружения в нирвану, волшебный гриб рассказал индийскому пареньку его предназначение, что рожден Чандракант был ради великой цели:
мстить белым варварам за годы рабства и угнетения индийского народа.
— О юный Чандракант! — молвил гриб. — Помни что «вера без дел мертва». Будет непросто. Враг хитер и коварен, сражаться предстоит тайно и его же оружием..
Прошли годы, затем десятилетия.
Паренек выучил английский, закончил хороший индийский ВУЗ и поступил на работу в крупную индийскую компанию, которой «белые варвары» из далекой страны за океаном заказывали разработку программного обеспечения.
Но не забыл храбрый Чандракант — верный сын индийского народа наставления волшебного гриба и дослужившись до должности системного архитектора начал вершить жестокую месть, сражаясь с «белыми варварами» их же собственным информационным оружием.
Прошу прощения за столь поэтическую вводную, но проект о котором пойдет речь — настолько лют, что его появление на свет может быть обосновано только экспериментами по созданию психотронного оружия.
Если код это изложение мысли в виде набора логических конструкций, то этот проект — программная реализация шизофрении.
Единственное связанное с этим проектом хорошее событие: коллега, который первым узрел это навсегда бросил пить и находится в полной завязке до сих пор. Седьмой год подряд.
К серьезному безумию надо уметь подводить, поэтому прежде чем показывать код, немного раскрою теорию и матчасть — для непричастных и невинных.
Аннотации
У современных языков вроде Java и C# есть такая замечательная вещь как аннотации — метаданные, которые содержат различные метки и дополнительные настройки, связанные с конкретным полем, методом или классом.
В примере выше, аннотация @Column, которой помечено практически каждое поле класса, отвечает за связывание этого поля с колонкой в таблице базы данных. Атрибут name собственно хранит название колонки.
Несмотря на внешнюю громоздкость, аннотации всегда были лишь дополнением к классу — дополнительным инструментом, призванным упростить работу и сократить объем кода внутри самого класса, необходимый для поддержки аналогичного функционала.
Никто в своем уме не воспринимал аннотации как полную замену всей логики приложения и соответственно не пытался программировать исключительно с помощью аннотаций — запомните этот важный момент.
Неожиданный но предсказуемый результат поиска по словам "SOLID rocks"
SOLID
В современном программировании есть такой термин SOLID — акроним, каждая буква которого обозначает отдельную концепцию:
Как и любая другая абстрактная концепция, SOLID — «за все хорошее против всего плохого», красиво выглядит на бумаге (в книгах) и в виде строчки резюме, но при реальном использовании становится сильно сложнее и не такой красивой.
Как и любую другую концепцию, созданную человеком, SOLID можно извратить до неузнаваемости, превратив в психотронное оружие для пожирания мозга несчастных программистов.
Особенно когда волшебный говорящий гриб нарекает избранным и готовит к великой миссии — мстить «белым варварам» за годы угнетения их же собственным высокотехнологичным оружием.
Та самая корпоративная IBM Websphere, на которой работал неповторимый оригинал.
Часть 0. Архитектурный джихад
Первая встреча с неведомым произошла как обычно абсолютно случайно, но навсегда изменила нашу скучную жизнь и отношение к индийской школе программирования и ее талантам:
к нам обратился (через посредников) классический английский джентельмен с лаконичной просьбой «посмотреть проект и если возможно оценить состояние».
Послать джентельмена сразу мы сочли неприемлемым — все же культурные люди из культурной столицы, тем более у него оказался приятный бюджет при весьма скромных запросах. Однако несмотря на постоянную практику в подобных задачах, к такому оказались не готовы даже мы — настолько все оказалось люто завернуто внутри.
На этом месте думаю стоит начать выкладывать конкретные примеры этой «индийской истории ужасов», чтобы дорогие читатели начали наконец понимать о чем идет речь.
К сожалению ввиду подписанных документов о неразглашении давно убитой сборки проекта и объемов исходников, не могу хочу показывать оригинальный индийский код, поэтому все что ниже — вольное изложение «по мотивам» и адаптация, хотя и занявшая в итоге семь лет подготовки.
Что никак не уменьшает убойность архитектурных талантов смелого Чандраканта (да не тронет GC его классы), помноженных на мощь его веры в святое дело борьбы с «белыми угнетателями» путем сжигания их мозгов.
Оригинальный проект представлял собой связку из нескольких десятков JEE-приложений, разворачиваемых на «большой» IBM Websphere и соответственно Java 8, но ради упрощения мы адаптировали реализацию для более современной Jakarta 10, со всеми наворотами новых версий Java (см. ниже).
Начнем демонстрацию с чего‑то более‑менее безобидного, хоть как‑то попадающего в рамки адекватности:
.. @WebFilter("/*") @WebListener publicclass Foo implements Filter,ServletContextListener{ // важная переменная privateint someImportantValue = 42; @override publicvoid contextInitialized(ServletContextEvent sce) { final ServletContext sc = sce.getServletContext(); // прокидывание в контекст выполнения собственный инстанс sc.setAttribute("foo", this); } ..
@override publicvoid doFilter(ServletRequest sr, ServletResponse sr1, FilterChain fc) throws IOException, ServletException { final ServletContext sc = sr.getServletContext(); // вытаскивание своего же инстанса из контекста Foo foo = (Foo)sc.getAttribute("foo"); if (foo.someImportantValue == 42) { // дальнейшая обработка .. } } .. }
В примере выше храбрый индийский архитектор Чандракант с помощью двух аннотаций, общего контекста и молитв Кришне использовал одну и ту же копию основного объекта в контексте двух разных сущностей в Servlet API (Filter и Listener), с разным жизненным циклом.
Связав их состояние воедино с поистине индийской хитростью — ради нанесения побоев мозгу неподготовленного «белого варвара».
Но пример выше это еще цветочки, по сравнению со следующим шедевром индийской инженерной мысли, из-за которого мой бедный коллега навсегда бросил пить:
@Entity @Table(name = "t_foo") @NamedQueries({ @NamedQuery(name = "Foo.fetchAll", query = "SELECT f FROM Foo f order by f.id desc") }) @Named @RequestScoped publicclass Foo { @Id @SequenceGenerator @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "default_gen") privateLong id; @size(min = 3, max = 255) @pattern(regexp = "[a-zA-Z0-9._ -?!]+") privateString title; ..
public List<Foo> fetchRecords() { returnthis.em.createNamedQuery("Foo.fetchAll",Foo.class).getResultList(); } .. }
Если вы занимались разработкой для J2EE/JEE/Jakarta и видели все эти JPA, JTA, JSF в работе — уже должны были бежать за валидолом. Но если ужасы корпоративной Java-разработки обошли стороной, наверное стоит немного объяснить суть.
На класс Foo в примере выше навешано два типа аннотаций, каждая из которых помечает его использование в разных контекстах и с разным жизненным циклом:
в качестве сущности (Entity) JPA, отвечающей за связывание с таблицей в базе данных;
в качестве бина CDI, который может быть использован непосредственно со страницы JSF.
Но на самом деле тут все еще веселее — посмотрите на поле instance:
private transient Foo instance;
Которое великий индийский гуру использовал в качестве.. DTO!
Считаю что такая реализация — верх дословной интерпретации принципов SOLID, доведенный до безумия, в качестве мести белым угнетателям по заказу волшебных грибов.
Таких интересных классов в проекте было не один и не два, а около 700 — целая армия автономных бинов, каждый из которых отвечал только за себя от начала и до конца.
Временами бины вызывали друг-друга, временами делали это по сети, иногда — через очереди сообщений.
Сложно сказать было ли это попыткой создать нейронную сеть с помощью Java-бинов и если да то насколько успешной, но JEE-приложение в те времена еще не успело осознать себя как личность.
Несмотря на всю описанную выше жесть, гордый сын индийского народа — архитектор Чандракант (да будут вечно стабильными его сборки) не успокоился, решив окончательно добить белых варваров, живущих за океаном и сжечь им психику таким замечательным API:
Если вы отличаете SOAP от REST и тем более знаете что такое JAX-WS и JAX-RS — с кода выше уже должно было морально поплохеть, поскольку сие есть самое натуральное оскорбление чувств верующих в высокие архитектурные принципы.
Для непричастных объясняю:
API состоит из методов, вызываемых удаленно, вебсервис — вариация API, вызываемая через веб, с использованием классических протоколов веба: HTTP/HTTPS.
REST и SOAP — два разных стандарта вебсервисов, один использует JSON, другой — XML (если упрощенно) для обмена сообщениями между клиентом и сервером. JAX‑WS и JAX‑RS — два разных стандарта для разметки методов вебсервиса с помощью аннотаций.
Так что в примере выше один и тот же метод используется одновременно в вебсервисе SOAP и как метод RESTful вебсервиса.
Особую пикантность и новые ощущения во время отладки придает тот факт, что каждый вебсервис — отдельный инстанс класса, со своим жизненным циклом.
А связывались между собой они через все тот же контекст CDI.
Или атрибут ServletContext.
Или через статический синглтон.
Или через контекст EJB.
Или по сети.
Или через очереди сообщений (JMS).
Гордый сын индийского народа любил разнообразие.
Резюмируя:
для того чтобы хотя-бы понять как это все работает, потребовался весь наш многолетний опыт разгребания корпоративных говен — ни в каких поисковиках, wiki, stackoverflow, форумах и досках объявлений ничего подобного не находилось.
Такова сила и мощь индийской инженерной школы.
Часть 1. Одноклассовый энтерпраиз
Мы решили сохранить подвиг храброго индийского архитектора Чандраканта (да никогда не упадут его юнит-тесты) для будущих поколений, чтобы его великие архитектурные идеи стали примером и образцом того как правильно мстить «белым угнетателям», сжигая вражеские мозги их собственным оружием.
мы отобрали самую лютую дичь из этого отбитого индийского проекта и свели в одно небольшое приложение, реализующее простейшую гостевую книгу.
Фишка в том что вся реализация это один класс на Java, без вложенных или анонимных классов. И очень много аннотаций.
Затем мы смогли развернуть столь упоротое приложение на всех основных серверах приложений, реализующих API Jakarta 10:
WildFly
Open Liberty / IBM WebSphere Liberty
Eclipse GlassFish
Payara
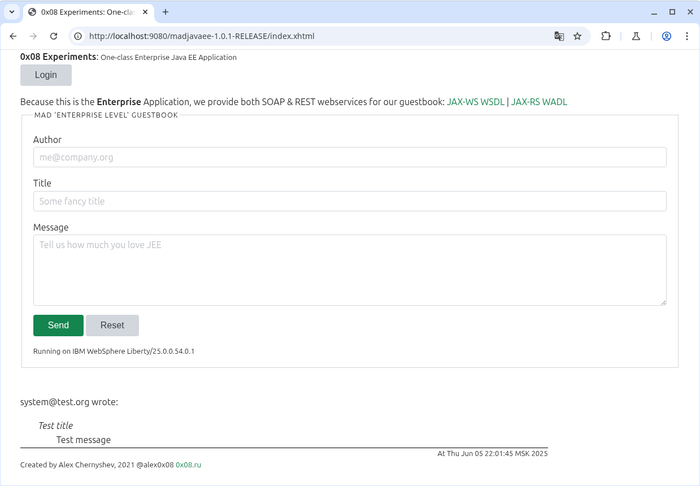
Так оно выглядит в работе (основной экран):
Для оформления на этот раз был взят индийский CSS-микрофреймворк с интересным для отечественного слуха названием.
Учим хинди вместе с автором:
FWIW, "choṭā" means "small" in Hindi
Так выглядит основной функционал гостевой книги — добавление новой записи в действии:
Так выглядит авторизация, полноценная авторизация с сессиями:
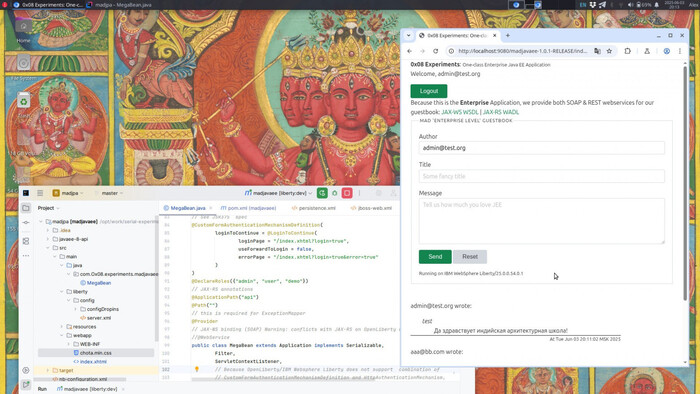
Теперь показываю работу с API, напоминаю это все еще один и тот же класс на Java.
JAX-WS
Вызов JAX-WS (SOAP) из клиента на Python:
Так выглядит тестовый клиент на Python:
from zeep import Client # ссылка на wsdl файл client = Client('http://localhost:9080/madjavaee-1.0.1-RELEASE/MegaBeanService?wsdl') # вызов тестового метода result = client.service.doPing() print(result)
# создание объекта DTO factory = client.type_factory('http://madjavaee.experiments.Ox08.com/') message = factory.megaBean(title='new title', author='test@test.com', message='test message') # вызов метода API для добавления записи result = client.service.addMessage(message) print(result)
# получить записи гостевой через API result = client.service.fetchRecords() print(result) # получить количество записей через API result = client.service.fetchRecordsCount() print(result)
JAX-RS
Так выглядят в действии вызовы вебсервиса JAX-RS (REST) с помощью curl и браузера:
То что в итоге у нас получилось представляет собой самое настоящее психотронное оружие, которым можно выжигать мозг неподготовленным к такому накалу дичи программистам.
Если никогда не видели код, за который приличные люди с высшим техническим образованием могут избить ногами прямо на рабочем месте — ниже вас ждут удивительные открытия.
Но сначала немного статистики:
~600 строк из которых ~200 — комментарии, итого ~400 строк на все приложение.
Смотрим и наслаждаемся шедевром:
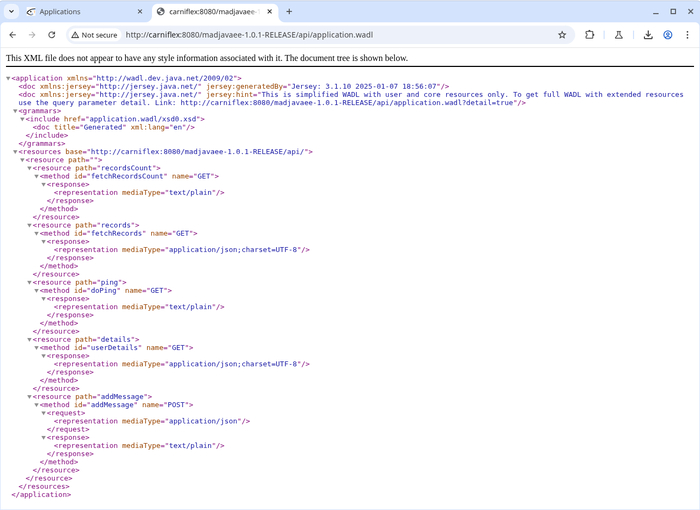
package com.Ox08.experiments.madjavaee; // Common Java importjava.io.*; import java.util.*; import java.util.logging.*; // CDI import jakarta.enterprise.context.*; import jakarta.inject.*; // JPA import jakarta.persistence.*; import jakarta.persistence.criteria.*; // JSR 303 Validation API import jakarta.validation.constraints.*; // JSF import jakarta.faces.application.FacesMessage; import jakarta.faces.context.*; // JSR 375 import jakarta.security.enterprise.AuthenticationStatus; import jakarta.security.enterprise.authentication.mechanism.http.*; import jakarta.security.enterprise.credential.*; import jakarta.security.enterprise.identitystore.*; // Servlet API import jakarta.servlet.*; import jakarta.servlet.annotation.*; import jakarta.servlet.http.*; // JTA import jakarta.transaction.Transactional; // JAX-RS importjakarta.ws.rs.core.*; importjakarta.ws.rs.ext.*; importjakarta.ws.rs.*; // JAX-WS import jakarta.jws.*; /** * This is single class CRUD application, based on recent Java EE stack. * @author <a href="mailto:alex3.145@gmail.com">Alex Chernyshev</a> */ // ordinary JPA entity annotations @Entity @Table(name = "t_records") @NamedQueries({ @NamedQuery(name = "MegaBean.getAllRecords", query = "SELECT m FROM MegaBean m order by m.id desc") }) // CDI bean annotation, which used to register instance of this class as CDI managed bean // This is required for EntityManager injection @Named // Java Faces annotation, required to trigger JSF initialization on some servers @jakarta.faces.annotation.FacesConfig() //(version = FacesConfig.Version.JSF_2_3) - deprecated in Faces 4.0 and upper // JSF annotation, required to bypass jsr299 validation see WebContainer.validateJSR299Scope @Dependent //@ApplicationScoped or @RequestScoped are not allowed, because of @WebFilter/@WebListener annotations presence // Servlet 3.0 annotations // Servlet Filter - another instance of this class will be registered as servlet filter @WebFilter("/*") // One more instance will be registered as servlet context listener, to be used as initialization point. // All because we can't use @ApplicationScoped and @Observes here @WebListener // See JSR375 spec for details @CustomFormAuthenticationMechanismDefinition( loginToContinue = @LoginToContinue( loginPage = "/index.xhtml?login=true", useForwardToLogin = false, errorPage = "/index.xhtml?login=true&error=true" ) ) // used only when embedded IdentityStore in use @jakarta.annotation.security.DeclareRoles({"admin", "user", "demo"}) // JAX-RS annotations @ApplicationPath("api") @jakarta.ws.rs.Path("") // this is required for ExceptionMapper @jakarta.ws.rs.ext.Provider // JAX-WS binding (SOAP) Warning: conflicts with JAX-RS on OpenLiberty and Wildfly! //@WebService publicclass MegaBean extends Application implements Serializable, jakarta.servlet.Filter, ServletContextListener, // Because OpenLiberty/IBM Websphere Liberty does not support combination of // CustomFormAuthenticationMechanismDefinition and HttpAuthenticationMechanism, // I was required to remove HttpAuthenticationMechanism interface // Custom IdentityStore does not work without @ApplicationScoped on OpenLiberty IdentityStore, // see JSR375 ExceptionMapper<Exception> { public MegaBean() { // call for JAX-RS parent class super(); /* * we need to set some default values to bypass JSR 303 bean validation for * JAX-RS bean, otherwise, JAX-RS service will not work. */ this.author = "no@no.org"; this.createdAt = new Date(); this.message = "no no no"; this.title = "test title"; } /** * We need to have an instance of this class as DTO - to transfer data from * html form */ privatetransient MegaBean current; /** * This class is also a CDI managed bean, remember? So here we will inject * EntityManager */ @Transient @PersistenceContext(unitName = "megaPU") private EntityManager em; /** * Security context maybe null when JAAS API was not initialized, so it's wrapped with @Instance */ @Transient @Inject private jakarta.enterprise.inject.Instance<jakarta.security.enterprise.SecurityContext> securityContext; @Transient @Context private ServletContext servletContext; /** * Ordinary JPA fields */ @Id @SequenceGenerator(name = "default_gen", sequenceName = "w_default_pk_seq") @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "default_gen") privateLong id; // unique id, this sequence will be created automatically too @Size(min = 3, max = 255) @Pattern(regexp = "[a-zA-Z0-9._ -?!]+") privateString title; // used also as 'login' field for auth @Size(min = 3, max = 30) @Email privateString author; // used also as 'password' field for auth @Lob @Column(length = Integer.MAX_VALUE) @NotBlank(message = "message may not be blank") privateString message; //message body, CLOB/TEXT/BLOB type will be used in database @Column(name = "created_date", nullable = false) @Temporal(TemporalType.TIMESTAMP) @NotNull protected Date createdAt; /** * this called from JSF page to clean up fields on page reload */ @WebMethod(exclude = true) publicvoid init() { resetFields(this); } /** * Each and every interface methods should be implemented and marked with * Annotation WebMethod(exclude = true) used to avoid bug in Apache CXF (Wildfly/OpenLiberty) * <a href="https://issues.apache.org/jira/browse/CXF-4916">...</a> * Method 'contextDestroyed' is part of ServletContextListener interface, so must be implemented */ @WebMethod(exclude = true) @Override publicvoid contextDestroyed(ServletContextEvent sce) { // not used, but required } /** * Part of ServletContextListener API, used on app start/reload */ @Override @WebMethod(exclude = true) // transactional is required to let EntityManager do his job @Transactional(Transactional.TxType.REQUIRED) publicvoid contextInitialized(ServletContextEvent sce) { final ServletContext sc = sce.getServletContext(); // due to CDI vs servlet conflict sc.setAttribute("mega", this); // we can make it only here due to stackoverflow error in eclipselink this.current = new MegaBean(); // reset fields back to nulls - to have working JSR303 validation resetFields(this.current); // populate JSF version details addVersionEnv(sc); // try to add some initial data if database is empty try { if (fetchRecordsCount() == 0) { //create test entity final MegaBean r = new MegaBean(); r.setCreatedAt(new Date()); r.setAuthor("system@test.org"); r.setMessage("Test message"); r.setTitle("Test title"); em.merge(r); LOG.info(String.format("automatically added default record: %d", r.getId())); } } catch (Exception e) { LOG.log(Level.WARNING, String.format("Exception on startup: %s", e.getMessage()), e); } } /** * JSF bean method, used to save form (from itself) */ @WebMethod(exclude = true) @Transactional(value=Transactional.TxType.REQUIRED,rollbackOn = Exception.class) publicString save() { // set creation date&time current.setCreatedAt(new Date()); em.merge(current); // this is required to reset form fields this.current = new MegaBean(); resetFields(this.current); // does redirect return "/index.xhtml?faces-redirect=true"; } /** * Does login action from JSF page * @throws IOException * if God was not on our side */ @WebMethod(exclude = true) publicvoid login() throws IOException { // we need to re-use 2 existing fields, present in this class: 'author for username and 'title' for password final Credential credential = new UsernamePasswordCredential(author, new Password(title)); final FacesContext facesContext =FacesContext.getCurrentInstance(); final ExternalContext ec = facesContext.getExternalContext(); // should not happen, this is used to avoid class cast if (!(ec.getRequest() instanceof HttpServletRequest req) || !(ec.getResponse() instanceof HttpServletResponse res)) { ec.getRequestMap().put("login", "true"); facesContext.addMessage(null, new FacesMessage(FacesMessage.SEVERITY_ERROR, "Login failed", null)); return; } // check if JAAS initialized if (!securityContext.isResolvable()) { LOG.warning("SecurityContext cannot be resolved!"); return; } // try to authenticate programmatically final AuthenticationStatus status = securityContext.get() .authenticate( req, res, AuthenticationParameters.withParams().credential(credential)); if (status == null) { LOG.warning("JAAS not initialized!"); return; } LOG.fine(String.format("auth status: %s",status)); switch (status) { case SEND_CONTINUE: { facesContext.responseComplete(); break; } case SEND_FAILURE: { ec.getRequestMap().put("login", "true"); facesContext.addMessage(null, new FacesMessage(FacesMessage.SEVERITY_ERROR, "Login failed", null)); break; } case SUCCESS: { putCurrentUser(current); LOG.info(String.format("logged in as %s",current.author)); facesContext.addMessage(null, new FacesMessage(FacesMessage.SEVERITY_INFO, "Login succeed", null)); // after redirect there will be full page reload ec.redirect(ec.getRequestContextPath() + "/index.xhtml?ok=true"); break; } case NOT_DONE: facesContext.responseComplete(); break; } } /** * Does logout action from JSF page */ @WebMethod(exclude = true) publicString logout() throws ServletException { final FacesContext facesContext =FacesContext.getCurrentInstance(); final ExternalContext ec = facesContext.getExternalContext(); // check for impossible state if (!(ec.getRequest() instanceof HttpServletRequest req)) { facesContext.addMessage(null, new FacesMessage(FacesMessage.SEVERITY_ERROR, "Logout failed", null)); return ""; } req.logout(); ec.invalidateSession(); return "/index.xhtml?faces-redirect=true"; } /** * JPA Entity fields * ------------------------------------------------------------------------------------------- */ @WebMethod(exclude = true) publicString getAuthor() { return author; } @WebMethod(exclude = true) publicvoid setAuthor(String author) { this.author = author; } @WebMethod(exclude = true) @jakarta.json.bind.annotation.JsonbTransient public MegaBean getCurrent() { return current; } @WebMethod(exclude = true) public Date getCreatedAt() { return createdAt; } @WebMethod(exclude = true) publicvoid setCreatedAt(Date createdAt) { this.createdAt = createdAt; } @WebMethod(exclude = true) publicLong getId() { return id; } @WebMethod(exclude = true) publicvoid setId(Long id) { this.id = id; } @WebMethod(exclude = true) publicString getTitle() { return title; } @WebMethod(exclude = true) publicvoid setTitle(String title) { this.title = title; } @WebMethod(exclude = true) publicString getMessage() { return message; } @WebMethod(exclude = true) publicvoid setMessage(String message) { this.message = message; } /** * JAX-RS & JAX-WS Methods * ----------------------------------------------------------- * Each method serves for both APIs * Ping is a test method, which respond plain text */ @GET @jakarta.ws.rs.Path("ping") @Produces(MediaType.TEXT_PLAIN) @WebMethod publicString doPing() { return "pong: " + System.currentTimeMillis(); } /** * Adds new message to guestbook from API * @param dto * new message data * @return */ @WebMethod @POST @jakarta.ws.rs.Path("addMessage") @Consumes(MediaType.APPLICATION_JSON) @Produces(MediaType.TEXT_PLAIN) // for JAX-WS only @Transactional publicString addMessage(MegaBean dto) { LOG.info(String.format("prepare to add record %s , %s , %s", author, title, message)); final MegaBean r = new MegaBean(); r.setCreatedAt(new Date()); r.setAuthor(dto.author); r.setMessage(dto.message); r.setTitle(dto.title); // for JAX-RS, EntityManager should be injected if (em!=null && em.isJoinedToTransaction()) return addMessageImpl(r); // otherwise, take EntityManager from servlet context // note: access to servletContext from JAX-RS will trigger exception: // RESTEASY003880: Unable to find contextual data of type: jakarta.servlet.ServletContext else { final MegaBean mb = (MegaBean) servletContext.getAttribute("mega"); return mb.addMessageImpl(r); } } /** * This 'black magic' is required, because JAX-WS does not allow transaction injection on service method */ @Transactional(Transactional.TxType.REQUIRED) @WebMethod(exclude = true) publicString addMessageImpl(MegaBean r) { try { r=em.merge(r); LOG.info(String.format("saved record %d", r.id)); returnString.format("Message added: %d %n", r.id); } catch (Exception e) { LOG.log(Level.WARNING, e.getMessage(), e); returnString.format("Error on saving: %s", e.getMessage()); } } /** * Uses Criteria API to retrieve count of records */ @WebMethod @GET @jakarta.ws.rs.Path("recordsCount") @Produces(MediaType.TEXT_PLAIN) publicLong fetchRecordsCount() { final EntityManager em = selectEm(); final CriteriaBuilder qb = em.getCriteriaBuilder(); final CriteriaQuery<Long> cq = qb.createQuery(Long.class); cq.select(qb.count(cq.from(MegaBean.class))); return em.createQuery(cq).getSingleResult(); } /** * API method to retrieve all guestbook records */ @WebMethod @GET @jakarta.ws.rs.Path("records") @Produces(MediaType.APPLICATION_JSON + "; charset=UTF-8") public List<MegaBean> fetchRecords() { return selectEm().createNamedQuery("MegaBean.getAllRecords", MegaBean.class).getResultList(); } /** * API method to get currently authenticated user details */ @GET @Produces(MediaType.APPLICATION_JSON + "; charset=UTF-8") @jakarta.ws.rs.Path("details") @WebMethod(exclude = true) public Response userDetails(@Context SecurityContext sc) { final java.security.Principal p = sc.getUserPrincipal(); // see sc.getCallerPrincipal() in Jakarta EE; return p != null ? Response.ok(p.getName()).build() : Response.status(Response.Status.UNAUTHORIZED).build(); } /** * Methods below are required , due to re-use of same class for both JAX-WS * and JAX-RS * ------------------------------------------------------------------------------------------------------- */ // part of IdentityStore API, not used @Override @WebMethod(exclude = true) public Set<String> getCallerGroups(CredentialValidationResult validationResult) { return Collections.emptySet(); } @Override @WebMethod(exclude = true) publicint priority() { return 100; } @Override @WebMethod(exclude = true) public Set<ValidationType> validationTypes() { return DEFAULT_VALIDATION_TYPES; } @WebMethod(exclude = true) @Override publicvoid init(FilterConfig filterConfig) { } @WebMethod(exclude = true) @Override publicvoid destroy() { } /** * this filter is used to redirect from / to actual jsf page */ @Override @WebMethod(exclude = true) publicvoid doFilter(ServletRequest sr, ServletResponse sr1, FilterChain fc) throws IOException, ServletException { final HttpServletRequest request = (HttpServletRequest) sr; LOG.info(String.format("got request: %s", request.getRequestURI())); // required for correct characters encoding request.setCharacterEncoding("UTF-8"); finalString p = request.getRequestURI(), cp = request.getServletContext().getContextPath(); String url = p; if (p.startsWith(cp)) url = p.substring(cp.length()); if ("/".equals(url) && sr1 instanceof HttpServletResponse hsr) hsr.sendRedirect(cp + "/index.xhtml"); else fc.doFilter(sr, sr1); } /** * Custom JSR375 validation * Used in combination with IdentityStore * @param credential * @return */ @Override @WebMethod(exclude = true) public CredentialValidationResult validate(Credential credential) { // should not happen if (!(credential instanceof UsernamePasswordCredential userCredential)) return CredentialValidationResult.INVALID_RESULT; finalString login = userCredential.getCaller(); LOG.info(String.format("called validate for %s", login)); if (!USERS.containsKey(login)) return CredentialValidationResult.INVALID_RESULT; final Map<String, Object> user = USERS.get(login); // dumb password check if (!userCredential.compareTo(login, (String) user.get("password"))) return CredentialValidationResult.INVALID_RESULT; LOG.info(String.format("user %s validated", login)); returnnew CredentialValidationResult(login, new HashSet<>(Arrays.asList((String[]) user.get("roles")))); }
/** * JAX-RS exception handler */ @Override @WebMethod(exclude = true) public Response toResponse(Exception e) { LOG.log(Level.WARNING, String.format("Exception on call : %s", e.getMessage()), e); return Response.status(400).entity(e.getMessage()).type("text/plain").build(); } // !! required for YASSON parser, otherwise exception will raise: // Error accessing getter 'getEnclosingConstructor' declared in 'class java.lang.Class' @Override @WebMethod(exclude = true) @jakarta.json.bind.annotation.JsonbTransient public Set<Class<?>> getClasses() { return Collections.emptySet();}
/* remove from JAX-RS/JAX-WS output */ @Override @WebMethod(exclude = true) @jakarta.json.bind.annotation.JsonbTransient public Set<Object> getSingletons() { return Collections.emptySet();} /* remove from JAX-RS/JAX-WS output */ @Override @WebMethod(exclude = true) @jakarta.json.bind.annotation.JsonbTransient public Map<String,Object> getProperties() { return Collections.emptyMap();} /** * Clean fields for provided instance * @param m * bean instance */ privatevoid resetFields(MegaBean m) { m.setAuthor(null); putCurrentUser(m); m.setCreatedAt(null); m.setId(null); m.setMessage(null); m.setTitle(null); } /** * JAX-RS and JAX-WS APIs have different lifecycle, for JAX-WS, an EntityManager will be injected by CDI, * but for JAX-RS is not (not for all servers). * So we need some selection logic here */ private EntityManager selectEm() { // if EntityManager was not injected if (this.em!=null) returnthis.em; // take instance from servlet context return ((MegaBean) servletContext.getAttribute("mega")).em; } /** * Get current user from principal * @return * current user's name */ publicstaticString getCurrentUser() { final FacesContext ctx = FacesContext.getCurrentInstance(); // if there is no faces context - could happen if current bean was not created by JSF if (ctx==null || ctx.getExternalContext()==null) return null; // get principal (the standard way) from current context final java.security.Principal p = ctx.getExternalContext().getUserPrincipal(); return p == null ? null : p.getName(); } /** * Set current user's name to author field of our bean instance * @param instance * an instance of MegaBean, used as DTO */ privatestaticvoid putCurrentUser(MegaBean instance) { finalString username = getCurrentUser(); if (username!=null) instance.setAuthor(username); } /** * Reads JSF version details and store as attribute of ServletContext * @param sc */ privatestaticvoid addVersionEnv(ServletContext sc) { final Package facesPackage = FacesContext.class.getPackage(); finalStringBuilder sb = newStringBuilder(); if (sc.getServerInfo() !=null) sb.append(sc.getServerInfo()); if (facesPackage.getImplementationVersion()!=null) sb.append(facesPackage.getImplementationVersion()); sc.setAttribute("versionLine", sb.toString()); LOG.info(sb.toString()); } // credentials store, not used under Wildfly/OpenLiberty privatestaticfinal Map<String, Map<String, Object>> USERS = new TreeMap<>(); static { final Map<String, Object> admin_user = new HashMap<>(); admin_user.put("password", "admin"); admin_user.put("roles", newString[]{"admin", "user", "demo"}); USERS.put("admin@test.org", admin_user);
final Map<String, Object> s_user = new HashMap<>(); s_user.put("password", "user"); s_user.put("roles", newString[]{"user"}); USERS.put("user@test.org", s_user); } // ordinary JUL logger, will not be serialized/persisted privatestaticfinal Logger LOG = Logger.getLogger("MEGA"); }
Выдохнули, перекрестились и хлебнули валидола? Значит самое время рассказать как эта космическая дичь вообще работает.
Часть 3. Препарируя дичь
Начнем с жемчужины индийской архитектурной мысли — использования JPA Entity и работы с Entity в одном и том же классе:
@Entity @Table(name = "t_records") @NamedQueries({ @NamedQuery(name = "MegaBean.getAllRecords", query = "SELECT m FROM MegaBean m order by m.id desc") }) @Named .. // ниже в этом же классе @Transient @PersistenceContext(unitName = "megaPU") private EntityManager em; .. // еще ниже в этом же классе final MegaBean r = new MegaBean(); r.setCreatedAt(new Date()); r.setAuthor("system@test.org"); r.setMessage("Test message"); r.setTitle("Test title"); em.merge(r); ..
Сама мысль о возможности такого не могла придти в голову психически здоровому инженеру, поэтому индийскому архитектору явно помогали волшебные говорящие грибы.
Но работает тем не менее все довольно просто:
во время сканирования аннотаций, создаются несколько разных контекстов выполнения для одного и того же класса
Да, оказывается «так можно было».
Аннотация @Entity регистрирует класс в качестве entity JPA, @Table указывает на конкретную таблицу, @NamedQueries и @NamedQuery описывает именованное JPQL-выражение для получения записей из базы - все как в других, нормальных проектах.
А затем начинается чистая шиза:
в этом же классе указывается аннотация @Named, которая превращает класс в управляемый бин CDI, с возможностью связывания зависимых полей.
Контейнер CDI честно отрабатывает свою пайку и вставляет инстанс EntityManager, через который происходит работа с сущностями JPA в качестве поля этого управляемого бина. Который является тем же самым классом что и сама сущность.
Аннотация @Transient нужна для того чтобы скрыть вставляемое через CDI поле от механизма, отвечающего за сохранение данных в JPA.
Servlet API
Следующий интересный с точки зрения клинической психиатрии блок аннотаций отвечает за надругательство над Servlet API:
@Dependent @WebFilter("/*") @WebListener
Конечно же так тоже делать нельзя, более того — если попытаетесь комбинировать @RequestScoped,@SessionScoped или @ApplicationScopedи аннотации Servlet API получите отлуп а приложение упадет при установке.
Единственная причина, по которой эта дичь вообще работает — «волшебная» аннотация @Dependent, про которую никто (из моих коллег) никогда не слышал.
The default scope if none is specified; it means that an object exists to serve exactly one client (bean) and has the same lifecycle as that client (bean).
Во всех остальных случаях (для всех остальных scope) будет выбрасываться ошибка при установке. Разгадка находится в методе validateJSR299Scope, аналог которого есть в любой реализации Jakarta API.
Так что суммнарно аннотации @Named и @Dependent позволяют использовать класс в качестве бина для Jakarta Faces и одновременно использовать аннотации из Servlet API — на одном и том же классе.
Поэтому у класса появляются обязательные методы, которые необходимо реализовать. Для интерфейса ServletContextListener это метод contextInitialized, ради которого собственно интерфейс и использовался:
.. @Override @WebMethod(exclude = true) @Transactional(Transactional.TxType.REQUIRED) publicvoid contextInitialized(ServletContextEvent sce) { final ServletContext sc = sce.getServletContext(); // due to CDI vs servlet conflict sc.setAttribute("mega", this); // we can make it only here due to stackoverflow error // in eclipselink this.current = new MegaBean(); // reset fields back to nulls - to have working JSR303 validation resetFields(this.current); // populate JSF version details addVersionEnv(sc); // try to add some initial data if database is empty try { if (fetchRecordsCount() == 0) { //create test entity final MegaBean r = new MegaBean(); r.setCreatedAt(new Date()); r.setAuthor("system@test.org"); r.setMessage("Test message"); r.setTitle("Test title"); em.merge(r); LOG.info(String.format("automatically added default record: %d", r.getId())); } } catch (Exception e) { LOG.log(Level.WARNING, String.format("Exception on startup: %s", e.getMessage()), e); } } ..
Напомню, что метод contextInitialized вызывается при запуске приложения, что используется для начальной загрузки данных в базу.
Кастомная авторизация
Следующий уровень отбитости, хотя и более слабый чем идея с JPA описанная выше:
полностью программная настройка авторизации, силами одних лишь аннотаций.
Конечно после красот Spring Boot все это смотрится как жалкая пародия уже не так мощно, но не забываем что Jakarta это API, у которого есть разные реализации.
И все они обязаны поддерживать вот такое:
.. @CustomFormAuthenticationMechanismDefinition( loginToContinue = @LoginToContinue( loginPage = "/index.xhtml?login=true", useForwardToLogin = false, errorPage = "/index.xhtml?login=true&error=true" ) ) // used only when embedded IdentityStore in use @jakarta.annotation.security.DeclareRoles({"admin", "user", "demo"}) ..
Верхняя аннотация «лошадиного размера» отвечает за настройку механизма авторизации — указывает на использование form-based авторизации с дополнительными настройками.
Нижняя @DeclareRoles описывает набор ролей, используемых приложением.
К сожалению аннотация @DeclareRoles работает только в сочетании с IdentityStore, который актвируется не всеми серверами приложений.
Отбитый API
Напоследок стоит рассказать и про реализацию двух вебсервисов в одном классе, средствами черной магии аннотаций.
На класс на самом деле навешано два разных набора аннотаций, первая отвечает за инициализацию бина в качестве вебсервиса JAX-WS (старый добрый SOAP с XML):
@WebService
Каждый публичный метод, который должен быть скрыт от генератора вебсервисов должен быть помечен специальным образом:
Помимо стандартных @ApplicationPath и @Path, которые вы точно видели в официальных примерах и более нормальных проектах, тут используется аннотация @Provider.
Нужна она ради метода toResponse, отвечающего за обработку исключений:
@Override @WebMethod(exclude = true) public Response toResponse(Exception e) { LOG.log(Level.WARNING, String.format("Exception on call : %s", e.getMessage()), e); return Response.status(400).entity(e.getMessage()).type("text/plain").build(); }
С помощью этого обработчика можно отдать клиенту вебсервиса красивое сообщение об ошибке а не адовый треш трейс, который вы чаще всего видите при ошибках в других проектах.
Часть 4. Сборка и деплой отбитой дичи
Проект целиком выложен в репозиторий на Github, сборка осуществляется с помощью обычного Apache Maven:
mvn clean package
Для сборки и запуска использовалась стандартная OpenJDK 21, которую поддерживают все используемые в статье серверы приложений.
К сожалению установка имеет свою специфику в каждом сервере приложений и временами требует дополнительных шагов настройки.
Самый простой способ увидеть наше «чудо-приложение» в действии — запустить специальный шаг Maven:
mvn liberty:run
После чего запустится скачивание сервера приложений OpenLiberty, его запуск и развертывание туда нашего приложения.
В качестве СУБД на всех серверах приложений использовался встраиваемый Apache Derby, за исключением Payara, где по-умолчанию используется H2.
Open Liberty / IBM Websphere Liberty
Проект OpenLiberty это открытая реализация сервера приложений, активно разрабатываемая IBM. Ее коммерческая версия IBM Websphere Liberty позиционируется как замена «большой» Websphere и основа всех будущих продуктов IBM, создаваемых на базе Websphere.
Вся основная разработка и развитие происходят в Open Liberty, затем переносятся в IBM Websphere Liberty, для которой потом оказывается коммерческая и долговременная поддержка.
Все описанные шаги по развертыванию актуальны и применимы для IBM Websphere Liberty.
Для статьи использовалась Open Liberty версии 25.0.0.5 с профилем Jakarta 10, скачать архив со сборкой можно по ссылке.
Так выглядит наша «адская гостевая» будучи запущенной в Open Liberty:
Прежде чем запускать приложение, необходимо настроить сервер — задать хотя-бы одного тестового пользователя и пул подключений к базе.
К сожалению OpenLiberty не подхватывает программный IdentityStore, который мы реализовывали в самом бине ради авторизации.
Для обоих действий надо изменить файл server.xml в каталоге:
wlp/usr/servers/defaultServer/server.xml
где wlp — корневой каталог распакованного Open Liberty.
Для регистрации тестового пользователя необходимо добавить блок:
Еще OpenLiberty не умеет генерировать WADL-файл с описанием JAX-RS сервиса, поэтому ссылка на него будет битой.
Wildfly
Wildfly (в девичестве JBoss) — один из самых известных серверов приложений с очень долгой историей. Хотя это изначально открытый проект, как и в случае с разработкой IBM (Websphere Liberty) существует отдельный коммерческий продукт на его основе — Red Hat JBoss Enterprise Application Platform.
Как и в случае с OpenLiberty, смысл существования Wildfly — разработка и обкатка новых фич с помощью коммьюнити, с последующей продажей гоям в виде готового коммерческого продукта за серьезный прайс.
Для статьи использовался Wildfly 36.0.1.Final, архив с которым можно скачать по ссылке.
Так выглядит наше чудо-приложение в работе под управлением Wildfly:
Установка приложения на Wildfly заметно проще — достаточно скопировать WAR-файл с приложением в каталог:
wildfly/standalone/deployments
Поддержка Apache Derby, JDBC-драйвер и пул подключений по-умолчанию уже присутствуют.
К сожалению текущая версия Wildfly (на момент написания статьи) также не активирует программный IdentityStore — тестовый домен JASPIC убрали в настройке по-умолчанию.
Поэтому тестовых пользователей придется создавать вручную с помощью скрипта bin/add-user.sh
Еще один очень известный проект с длинной историей, некогда разрабатываемый самой компанией Sun Microsystems в качестве эталонной реализации J2EE.
Для статьи использовалась версия 7.0.25 с профилем Jakarta EE Platform, скачать архив со сборкой можно по ссылке.
Так выглядит развертывание и запуск нашего приложения в Glassfish:
Запускается сервер командой bin/startserv
Glassfish поддерживает и похватывает при установке программный IdentityStore (будут работать встроенные в бин учетки) и пул по-умолчанию с Apache Derby и сочетание JAX-WS и JAX-RS вебсервисов на одном и том же классе.
И даже генерацию WADL-файла он тоже поддерживает:
Единственная яркая дичь — за каким-то хреном в последних версиях перестал автоматически запускаться сервер Apache Derby, теперь для его запуска надо запустить консоль управления asadmin и выполнить команду:
start-database
Результат выполнения:
Payara
Наконец последний в сегодняшнем списке и наименее известный в наших краях проект Payara:
When commercial support for GlassFish ended in 2014, Payara Server was created as a fully-supported drop-in replacement. Payara Services was born in 2016 to offer support solutions for the application server.
Да, теперь вы тоже знаете что у Glassifsh оказывается были и коммерческие пользователи, по зову которых появилась эта самая "Payara".
Для статьи использовался Payara Server 6.2025.5 с профилем Full, скачать сборку можно по ссылке.
Запускается командой:
bin/asadmin start-domain
Так выглядит в действии развертывание и запуск нашего приложения:
Тут все совсем хорошо и никаких дополнительных шагов не требуется совсем, база (H2) запускается по-умолчанию, программный IdentityStore подхватывается автоматически из бина и определяются оба типа вебсервисов — JAX-RS и JAX-WS, которые спокойно работают одновременно.
Эпилог
Перед вами одна из статей, материал для которой автор собирал несколько лет и до последнего не был уверен, что подобную «техноересь» вообще стоит показывать психически здоровым людям, тем более что храбрый индийский архитектор Чандракант (да будут всегда выделяться ресурсы его процессам) все же творил свою лютую месть довольно давно.
Поэтому адаптация его «архитектурного джихада» под современные реалии Java заняла в итоге несколько лет экспериментов и тестов — все ради того чтобы дорогие читатели ощутили на себе с какими ужасами от мира разработки временами приходится иметь дело.
Не буду просить читателей никогда не применять описанные выше техники в реальных проектах — все равно не получится, поскольку для такого нужен праведный гнев, избранность и помощь волшебных грибов.
Но если столкнетесь с таким на практике и захотите сохранить психику ваших программистов в девственном виде — теперь будете знать кому написать.
Статья была опубликована на Хабре, менее цензурный оригинал с саундтреком и дополнительными материалами в нашем блоге.
То что реформы назрели в ВМФ, и ежу ясно. Вопрос какие. Потратив 15 минут на общение с chat GPT я их неплохо сформулировал. Да, можно сколько угодно ржать на глупым мной и глупым chat GPT, но Вы уверены, что в данный момент реформы флота идут хотя бы на таком простом уровне?
Если флот сейчас строить с нуля, это строить надо не «флот больших кораблей», а морскую распределённую IT-армию: датчики, дешёвые носители, БПЛА/БЭК/подводные аппараты, береговые ракетные комплексы, защищённая связь, быстрый цикл доработок.
1. Главный принцип
Не «линкор ищет бой», а:
“Каждый дорогой корабль — сервер в дата-центре, который нельзя подставлять. Всё опасное делают дешёвые периферийные устройства.”
То есть корабль больше не главный герой. Главный герой — сеть.
2. Состав такого флота
Он выглядел бы примерно так:
20% — классические корабли. Фрегаты, корветы, тральщики, подлодки, транспорт. Но они не ходят гордо туда-сюда, а работают как защищённые узлы: ПВО, Калибры, связь, РЭБ, командование.
30% — беспилотный ударный слой. Морские дроны, малые катера-носители, барражирующие БПЛА, разведчики, ложные цели. Не единичные «чудо-дроны», а серийные расходники.
Старый флот мыслит базой как парадным портом. Нужно делать иначе:
Севастополь, Новороссийск, Темрюк, Керчь, малые бухты, временные стоянки — всё превращается в распределённую систему. Корабли не стоят красиво у стенки. Они постоянно меняют места, прикрываются ложными макетами, дымом, сетями, баржами, мобильными РЭБ и ПВО.
Главная мысль: противник не должен понимать, где настоящий корабль, где макет, где ловушка, где пустой причал.
4. Противодроновая оборона была бы отдельным родом сил
Не «матрос с пулемётом увидел БЭК ночью», а полноценная служба:
Командование противодроновой обороны ЧФ.
Её задача — не героически отбиваться, а строить непрерывный контур:
Каждая атака противника разбирается как инцидент в IT: лог, причина пробоя, патч, новая версия защиты.
5. Корабли изменились бы внешне
Большие красивые корабли получили бы «уродливый», но полезный обвес:
много оптики, тепловизоров, малых РЛС, сеток, дополнительных постов наблюдения, дешёвых автоматизированных турелей, мест запуска малых дронов, контейнеров РЭБ, ложных тепловых/радиолокационных целей.
И главное — каждый корабль имел бы свои мини-БПЛА, как глаза на 20–50 км вокруг. Без этого корабль в 2026 году слеповат.
Он выпускает разведчиков, ретрансляторы, ложные цели, перехватчики, морские дроны. Сам не лезет в бой, а управляет «стаей».
Идеальный флот после 2022–2026 годов — это не фрегат против фрегата. Это:
фрегат + 30 дешёвых глаз + 20 ложных целей + 10 перехватчиков + береговые датчики + спутниковая/радиоразведка + ремонтная команда на берегу.
7. Доктрина: не господство на море, а управление риском
Старая мечта: «контролировать Чёрное море».
Новая реалистичная цель:
не дать противнику свободно действовать, сохранить свои пусковые/логистические возможности и не терять дорогие корабли от дешёвых систем.
Можно не иметь большого флота, но парализовать чужой. Carnegie прямо описывает это как асимметричную модель, где флот можно сделать функционально бесполезным без симметричного корабельного боя.
8. Кадры: адмиралы стали бы “продуктовыми менеджерами войны”
Самое важное изменение было бы не в железе, а в культуре.
В новом флоте нужно держать рядом:
инженеров, программистов, операторов FPV/БЭК, аналитиков данных, офицеров РЭБ, ремонтников, закупщиков, боевых командиров.
И цикл был бы такой:
атака → разбор → новая версия → испытание → массовое внедрение.
Не через 5 лет ОКР, а через недели.
9. Что стало бы с большими кораблями
Они не исчезли бы, но потеряли бы культовый статус.
Крейсер типа «Москва» в такой системе выглядел бы не символом мощи, а слишком дорогой и слишком заметной платформой. Его либо глубоко модернизировали бы под ПВО/БПЛА/РЭБ, либо держали бы далеко, либо вообще не строили бы.
Будущее — за меньшими, многочисленными, ремонтопригодными платформами.
10. Итоговая картинка
Черноморский флот такого типа выглядел бы не как парад кораблей, а как роевая экосистема:
То есть не «флот адмиралов», а флот инженеров войны.
Главный лозунг такого ЧФ был бы:
“Дорогой корабль не должен видеть противника первым. Его должны видеть тысячи дешёвых глаз.”
p.s.: опять таки всякие псевдо IT-Шники, которых тут роится много словно мух не знаю зачем, могут сколько угодно высмеивать эти идеи. Но для всех моих настоящих IT-шников, работающих в банках, в робототехнике, в devops, с БПЛА, это уже давно очевидные вещи. И все они в недоумении, почему кому-то это может быть непонятно. Шурик, это же очевидно!
Какое-то время пилил self-hosted чат в стиле Discord и наконец довёл до состояния, которым не стыдно поделиться. Бесплатный, открытый исходный код (MIT).
Зачем вообще: большинство self-hosted чатов требуют Docker, инстанс Postgres, очередь сообщений и полдня жизни до того, как увидишь экран входа. Мне хотелось, чтобы моё сообщество могло общаться, не завися от чужих серверов, и без необходимости быть админом-девопсом. Поэтому тут всё наоборот — только PHP и один файл SQLite. Если ваш хостинг тянет блог на WordPress, он потянет и это.
Что умеет: серверы, текстовые каналы и личные сообщения с редактированием и реакциями; голосовые комнаты и звонки по WebRTC с демонстрацией экрана; обмен файлами (картинки сжимаются автоматически, лента грузит лёгкие миниатюры); устанавливается как PWA на компьютер и телефон без магазинов приложений; несколько тем и 4 языка с переключением на лету; есть API мини-приложений (в комплекте демо 3D-шашек). Весь брендинг и лимиты живут в одном config.json — код трогать не нужно.
Что нужно на сервере: PHP 7.3+ (рекомендуется 8.1+), PDO SQLite, опционально GD для миниатюр, Apache или Nginx с HTTPS. Никакого Node, Composer, отдельной БД и сборки. Установка по сути: залить файлы → дать права на папку uploads → отредактировать конфиг → открыть в браузере.
Проект ранний, делаю один, так что буду рад фидбэку — особенно по голосовому стеку и безопасности. Баг-репорты и комментарии в духе «вот чего мне не хватает, чтобы я реально это развернул» очень приветствуются.
Передача буфера обмена между устройствами через защищённый канал
Короткое напоминание
Месяц назад я тут рассказывал, как сделал свой сервис для обмена чувствительной и приватной информацией Copy Sync - устроенный так, чтобы мой сервер физически не мог прочитать ваши пароли и ссылки. Текст шифруется прямо на вашем устройстве, на сервер уезжает уже зашифрованная каша, ключа от неё у меня нет.
Многие тогда справедливо спросили в комментах: "а ключи-то от шифрования откуда устройства берут?" Вопрос в точку. И в той статье я сам честно написал, что тут осталась слабое место. Вот её и чиню.
В чём была дыра
Объясню простым языком:
Чтобы зашифровать сообщение для вашего второго устройства, первому нужен "публичный ключ" второго, что-то вроде открытого почтового ящика, куда можно бросить письмо, но достать его может только владелец. Вопрос: откуда первое устройство этот ящик берёт? Спрашивает у сервера. У моего сервера.
И вот тут собака зарыта. А что если сервер (или тот, кто его взломал) вместо настоящего ящика вашего устройства подсунет свой? Тогда:
ваше первое устройство шифрует письмо в подставной ящик;
сервер его спокойно открывает, читает, потом перепаковывает в настоящий ящик и отправляет дальше;
второе устройство получает письмо как ни в чём не бывало.
Оба ваших устройства довольны, а посередине кто-то всё прочитал. Это называется "человек посередине" (man-in-the-middle). И самое обидное шифрование тут ни при чём, оно идеальное. Просто зашифровали не туда. А "не туда" подсунул именно тот, кому мы вроде как не должны были доверять, мой сервер.
Неприятно, что мой же сервис, про который я писал "нечем вас прочитать", в этом сценарии всё-таки мог. Так не пойдёт.
Как защититься
Способ старый и проверенный, такой же используют в Signal и WhatsApp, когда показывают "код безопасности". Идея простая:
У каждого ящика-ключа есть короткий отпечаток - набор букв и цифр, который из этого ключа однозначно вычисляется. Как отпечаток пальца: у разных ключей он разный, у одного и того же - всегда одинаковый.
Вы открываете Copy Sync на двух своих устройствах и сравниваете отпечатки глазами. Совпали - значит, между устройствами реально один и тот же ключ, никто посередине не встрял. А если сервер подсунул свой ключ - отпечаток сразу разойдётся, и вы это увидите. Подделать его нельзя: отпечаток намертво привязан к ключу.
Пять секунд работы - и MITM из "незаметно читает всё" превращается в "попадётся на первой же сверке".
А теперь - самое главное, ради чего и пишу
Когда вы сверили отпечатки и нажали "Сверено", эту галочку надо где-то запомнить. И вот тут у меня был соблазн сделать "как удобно": сохранить её на сервере, чтобы синхронизировалась между устройствами.
Я этого не сделал. Сознательно.
Смотрите. Мы защищаемся от кого? От сервера. А теперь представьте, что я бы доверил тому же серверу хранить отметку "этому ключу можно верить". Взломщик просто поставил бы галочку "проверено" своему поддельному ключу и вся защита превратилась бы в спектакль. Нельзя ставить сторожить дверь того, от кого ты эту дверь запираешь.
Поэтому галочка "сверено" живёт только в вашем браузере и на сервер не уходит вообще никогда. У этого есть приятный побочный эффект: галочка привязана к самому ключу. Если сервер завтра попробует подменить ключ, отметка "проверено" слетит сама собой, и устройство снова покажет "не сверено". Вы заметите, что что-то поменялось. Подмена ключа автоматически сбрасывает доверие - это не баг, это и есть защита.
Цена честная: сверять придётся на каждом устройстве отдельно. Но это в сто раз лучше, чем доверять "проверку" тому, кого проверяешь.
Бонусом - подключение второго устройства по QR
Заодно сделал удобную мелочь. Раньше, чтобы добавить второе устройство, надо было вводить пароль. Теперь на первом устройстве показывается QR-код, вы сканируете его вторым и всё, вы в системе. Без пароля.
И тут важная деталь в том же духе: по QR передаётся только разовый "пропуск" (живёт 5 минут, срабатывает один раз). Ключи шифрования по нему не передаются - второе устройство создаёт свои собственные, прямо у себя, и они его никогда не покидают. Так что даже перехваченный QR не даст доступа к вашим данным.
Честно о том, чего ещё нет
Как и в прошлый раз - про минусы сам, без прикрас:
Сверка ручная. Она работает, только если вы реально сравнили отпечатки. Не сравнили - защита не сработает. Я не заставляю это делать насильно, но честно: это инструмент, а не автоматический щит.
Сервис пока не предупреждает сам, если ключ вдруг сменился - он лишь снимает галочку "проверено". Автоматическое уведомление "эй, ключ поменялся!" следующая задача.
Это по-прежнему пет-проект одного человека. Веб-версия работает, расширение и мобильные приложения - в планах. Код по-прежнему весь открыт - можете сами проверить, а не верить на слово.
Посмотреть
Сайт: copysync.ru (заведите два устройства, подключите второе по QR и сверьте отпечатки — увидите всё своими глазами)
Буду рад вопросам и критике - особенно от тех, кто шарит в безопасности. Нашли, как обойти сверку, - для меня это ценнее лайка.
А вопрос к вам такой: вы вообще когда-нибудь сверяли "код безопасности" в Signal или WhatsApp? Или это та штука, которую все видели, но никто ни разу не нажимал?